



Video modifying has all the time had a grimy secret: eradicating an object from footage is simple; making the scene appear like it was by no means there may be brutally exhausting. Take out an individual holding a guitar, and also you’re left with a floating instrument that defies gravity. Hollywood VFX groups spend weeks fixing precisely this type of drawback. A crew of researchers from Netflix and INSAIT, Sofia College ‘St. Kliment Ohridski,’ launched VOID (Video Object and Interplay Deletion) mannequin that may do it mechanically.
VOID removes objects from movies together with all interactions they induce on the scene — not simply secondary results like shadows and reflections, however bodily interactions like objects falling when an individual is eliminated.
What Drawback Is VOID Really Fixing?
Commonplace video inpainting fashions — the type utilized in most modifying workflows at present — are skilled to fill within the pixel area the place an object was. They’re basically very refined background painters. What they don’t do is motive about causality: if I take away an actor who’s holding a prop, what ought to occur to that prop?
Present video object elimination strategies excel at inpainting content material ‘behind’ the thing and correcting appearance-level artifacts reminiscent of shadows and reflections. Nevertheless, when the eliminated object has extra important interactions, reminiscent of collisions with different objects, present fashions fail to appropriate them and produce implausible outcomes.
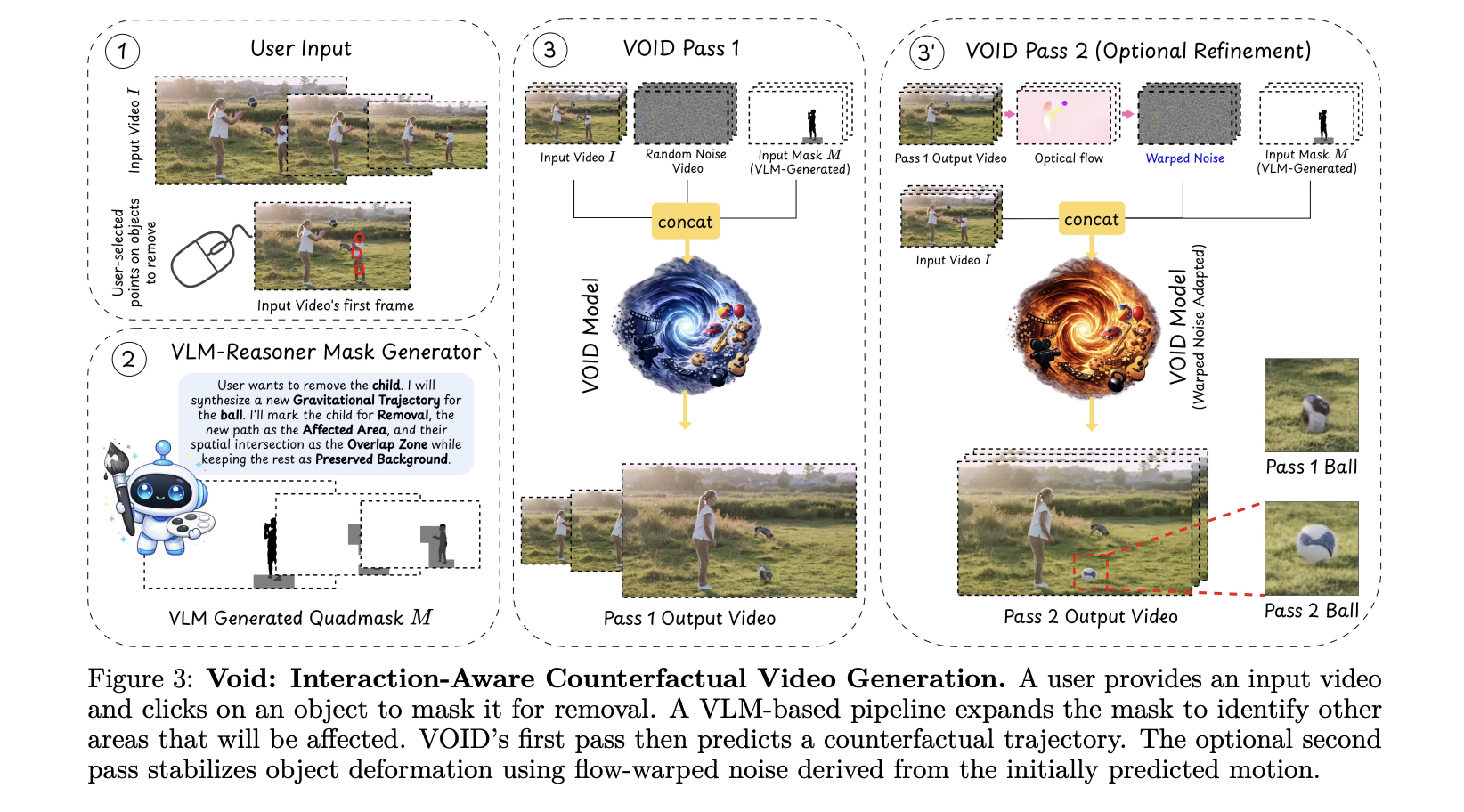
VOID is constructed on prime of CogVideoX and fine-tuned for video inpainting with interaction-aware masks conditioning. The important thing innovation is in how the mannequin understands the scene — not simply ‘what pixels should I fill?’ however ‘what is physically plausible after this object disappears?’
The canonical instance from the analysis paper: if an individual holding a guitar is eliminated, VOID additionally removes the particular person’s impact on the guitar — inflicting it to fall naturally. That’s not trivial. The mannequin has to know that the guitar was being supported by the particular person, and that eradicating the particular person means gravity takes over.
And in contrast to prior work, VOID was evaluated head-to-head towards actual opponents. Experiments on each artificial and actual knowledge present that the method higher preserves constant scene dynamics after object elimination in comparison with prior video object elimination strategies together with ProPainter, DiffuEraser, Runway, MiniMax-Remover, ROSE, and Gen-Omnimatte.
The Structure: CogVideoX Beneath the Hood
VOID is constructed on CogVideoX-Enjoyable-V1.5-5b-InP — a mannequin from Alibaba PAI — and fine-tuned for video inpainting with interaction-aware quadmask conditioning. CogVideoX is a 3D Transformer-based video era mannequin. Consider it like a video model of Steady Diffusion — a diffusion mannequin that operates over temporal sequences of frames slightly than single photos. The particular base mannequin (CogVideoX-Enjoyable-V1.5-5b-InP) is launched by Alibaba PAI on Hugging Face, which is the checkpoint engineers might want to obtain individually earlier than working VOID.
The fine-tuned structure specs: a CogVideoX 3D Transformer with 5B parameters, taking video, quadmask, and a textual content immediate describing the scene after elimination as enter, working at a default decision of 384×672, processing a most of 197 frames, utilizing the DDIM scheduler, and working in BF16 with FP8 quantization for reminiscence effectivity.
The quadmask is arguably essentially the most attention-grabbing technical contribution right here. Fairly than a binary masks (take away this pixel / maintain this pixel), the quadmask is a 4-value masks that encodes the first object to take away, overlap areas, affected areas (falling objects, displaced objects), and background to maintain.
In observe, every pixel within the masks will get one in every of 4 values: 0 (major object being eliminated), 63 (overlap between major and affected areas), 127 (interaction-affected area — issues that can transfer or change on account of the elimination), and 255 (background, maintain as-is). This offers the mannequin a structured semantic map of what’s taking place within the scene, not simply the place the thing is.
Two-Move Inference Pipeline
VOID makes use of two transformer checkpoints, skilled sequentially. You possibly can run inference with Move 1 alone or chain each passes for larger temporal consistency.
Move 1 (void_pass1.safetensors) is the bottom inpainting mannequin and is enough for many movies. Move 2 serves a particular objective: correcting a identified failure mode. If the mannequin detects object morphing — a identified failure mode of smaller video diffusion fashions — an elective second go re-runs inference utilizing flow-warped noise derived from the primary go, stabilizing object form alongside the newly synthesized trajectories.
It’s value understanding the excellence: Move 2 isn’t only for longer clips — it’s particularly a shape-stability repair. When the diffusion mannequin produces objects that progressively warp or deform throughout frames (a well-documented artifact in video diffusion), Move 2 makes use of optical movement to warp the latents from Move 1 and feeds them as initialization right into a second diffusion run, anchoring the form of synthesized objects frame-to-frame.
How the Coaching Information Was Generated
That is the place issues get genuinely attention-grabbing. Coaching a mannequin to know bodily interactions requires paired movies — the identical scene, with and with out the thing, the place the physics performs out appropriately in each. Actual-world paired knowledge at this scale doesn’t exist. So the crew constructed it synthetically.
Coaching used paired counterfactual movies generated from two sources: HUMOTO — human-object interactions rendered in Blender with physics simulation — and Kubric — object-only interactions utilizing Google Scanned Objects.
HUMOTO makes use of motion-capture knowledge of human-object interactions. The important thing mechanic is a Blender re-simulation: the scene is about up with a human and objects, rendered as soon as with the human current, then the human is faraway from the simulation and physics is re-run ahead from that time. The result’s a bodily appropriate counterfactual — objects that had been being held or supported now fall, precisely as they need to. Kubric, developed by Google Analysis, applies the identical thought to object-object collisions. Collectively, they produce a dataset of paired movies the place the physics is provably appropriate, not approximated by a human annotator.
Key Takeaways
- VOID goes past pixel-filling. In contrast to current video inpainting instruments that solely appropriate visible artifacts like shadows and reflections, VOID understands bodily causality — in case you take away an individual holding an object, the thing falls naturally within the output video.
- The quadmask is the core innovation. As an alternative of a easy binary take away/maintain masks, VOID makes use of a 4-value quadmask (values 0, 63, 127, 255) that encodes not simply what to take away, however which surrounding areas of the scene will probably be bodily affected — giving the diffusion mannequin structured scene understanding to work with.
- Two-pass inference solves an actual failure mode. Move 1 handles most movies; Move 2 exists particularly to repair object morphing artifacts — a identified weak point of video diffusion fashions — through the use of optical flow-warped latents from Move 1 as initialization for a second diffusion run.
- Artificial paired knowledge made coaching attainable. Since real-world paired counterfactual video knowledge doesn’t exist at scale, the analysis crew constructed it utilizing Blender physics re-simulation (HUMOTO) and Google’s Kubric framework, producing ground-truth earlier than/after video pairs the place the physics is provably appropriate.
Try the Paper, Mannequin Weight and Repo. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as nicely.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking advanced datasets into actionable insights.