



# Introduction
Over recent years, AI Explainability (XAI) has become a major focus in the world of real-world AI systems, and Large Language Models (LLMs) are no exception. Because these models are so complex and powerful, it is crucial to shift from static testing to dynamic evaluation. This helps us better grasp how these mysterious “black-box” systems produce their text outputs. Additionally, blending dynamic evaluation with solid statistical methods and cost-effective, production-ready monitoring tools is becoming a quietly significant trend in the industry.
This piece explores the concept of LLM explainability. It highlights the latest advancements, trends, and ongoing work in this vital area of research, which strives to measure, interpret, and control some of the most advanced AI systems we have today.
# LLM Explainability
While LLMs have completely transformed the AI landscape, their internal processes remain mostly hidden. High-stakes sectors are increasingly relying on these complex, specialized models, where choices based on their answers can carry heavy consequences. In this environment, XAI—especially LLM explainability—is more critical than ever.
Historically, a model’s decision-making “intelligence” has been judged using public, unchanging benchmarks. However, new research shows that this traditional scoring system is failing, as models are starting to memorize public tests rather than demonstrate actual reasoning. This creates a pressing need for dynamic, multi-layered evaluation frameworks that test models against fresh, expert-designed scenarios.
But what is XAI truly after, beyond just checking if an LLM’s answer is right or wrong? It mainly wants to figure out why. For this purpose, model-agnostic local explanations are a highly effective method. Cutting-edge tools based on the SMILE framework—standing for Statistical Model-Agnostic Interpretability with Local Explanations—excel at this. They examine how tiny changes in a user’s prompt (the model’s input) affect the generated text. Rather than just using basic distance measurements, these frameworks employ advanced, rigorous statistical distance metrics. This allows them to create powerful visual tools like heatmaps, which highlight exactly which parts of the input (such as specific words) had the biggest impact on the model’s choice to produce a particular output.
The diagram below illustrates how to tackle the problem of limited or nonexistent model transparency. gSMILE, a framework built on SMILE, can be utilized to clarify how LLMs react to various segments of a prompt.
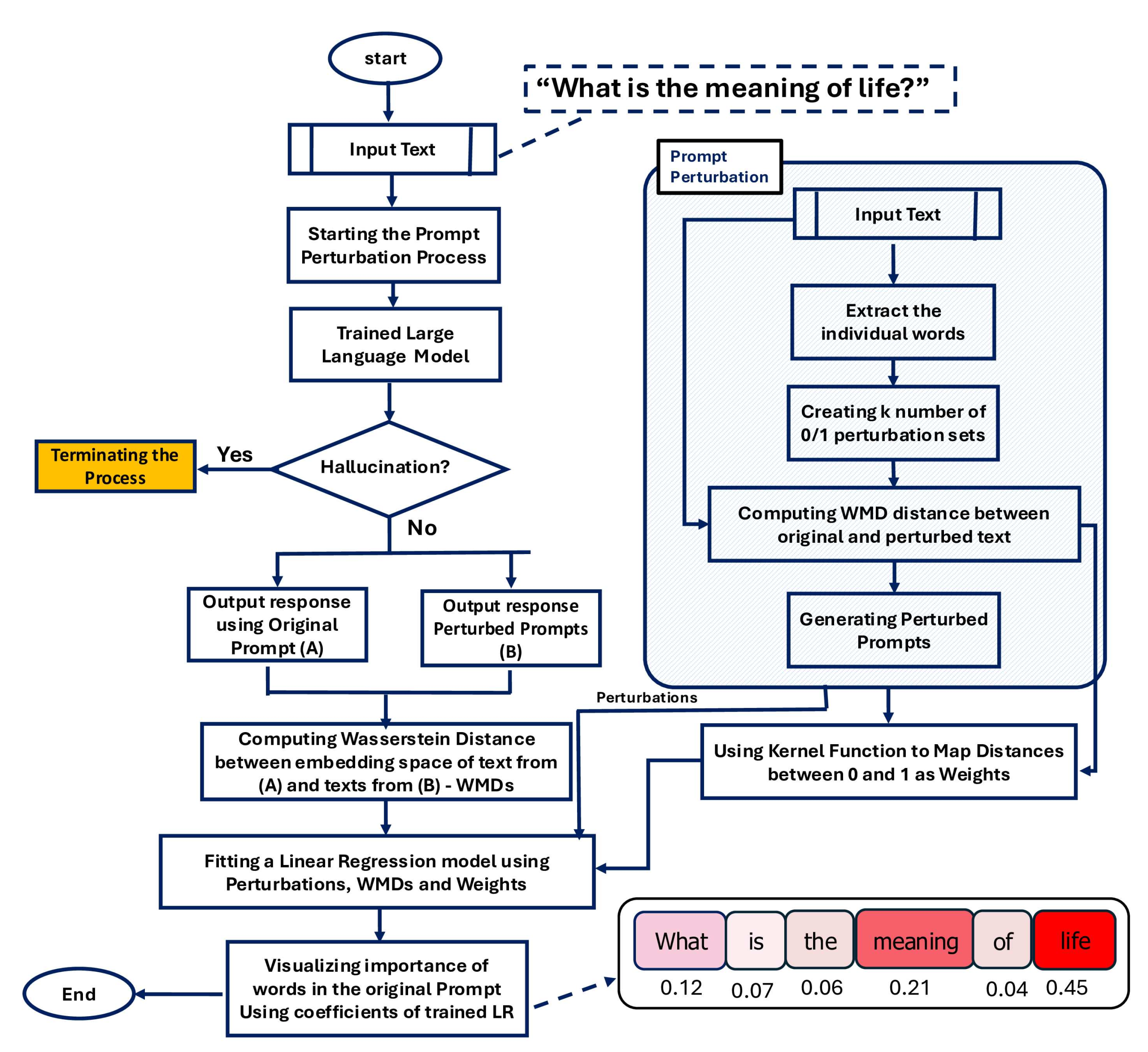
gSMILE explains how LLMs provide responses to distinct parts of a prompt | Image by LLM-SMILE
While having these advanced frameworks to assess an LLM’s internal logic sounds great in theory, creating local, prompt-specific explanations can be incredibly expensive and difficult for massive, closed-source LLMs due to the enormous volume of API calls they handle. This has driven the demand for affordable and accessible solutions, as highlighted in recent studies. To address this, researchers have developed a workaround that uses smaller, open-source models to approximate and simplify the complicated decision boundaries of proprietary LLMs. This method guarantees high-quality explanations while drastically cutting costs, making model interpretability achievable even for regular developers.
Aside from scientific and theoretical breakthroughs, there is a growing movement toward practical observability. Engineers are increasingly using tracking platforms like CometLLM. Designed to make explainability widely available, these tools can log prompt iterations, detailed metadata, and past execution traces. As a result, developers can troubleshoot their pipelines and ensure their workflows can be reproduced, all without needing deep mathematical knowledge.
# Summing Up
Based on the progress and future outlook discussed, it is clear that the world of LLM XAI is growing at breakneck speed. Amid this surge of research and the rise of cost-friendly tools, community-focused hubs for LLM XAI are becoming indispensable. Merging solid statistical evaluation with budget-conscious engineering methods is the key to slowly unlocking the black box. This approach ensures our models are not only powerful, but also transparent and reliable.
Key references, for further reading:
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.