




Breaking the single datacenter assumption
Today’s AI systems typically rely on the idea of centralized, uniform data centers. In practice, though, infrastructure is far from neat. For the majority of organizations, compute resources are scattered across private clouds, research labs, and a mix of on-premises and edge hardware from different generations. When these resources are locked inside operational silos, putting them to work on intensive AI tasks becomes a major headache. Making the most of GPUs is no longer purely a matter of raw computing power — it is, at its core, an infrastructure problem.
Why geo-distributed AI becomes a Kubernetes problem
AI infrastructure has quietly reached a turning point. What started as a machine learning concern — training models more quickly, running inference at lower cost, and scaling compute as needed — has grown into something much larger and more structural. With companies like OpenAI building on Kubernetes and the CNCF officially embracing this path, Kubernetes has become the go-to orchestration platform for AI workloads. Running AI across multiple geographic locations is now, fundamentally, a cloud-native infrastructure challenge.
The moment workloads extend beyond a single centralized data center and stretch across on-prem clusters, cloud regions, and edge sites, the difficulty ramps up fast. You are no longer simply queuing a training job. You have to oversee cluster lifecycles across different locations, keep cross-site connections stable, and work with rapidly changing hardware — from ultra-fast interconnects like NVLink to next-generation memory technologies like HBM. These are classic distributed systems challenges, and they fall squarely within Kubernetes’ domain.
This is exactly where multi-cluster orchestration stops being optional. No single cluster can cover all those locations, and a fleet managed by hand will quickly overwhelm any team. What you need is a robust platform layer that handles cross-site networking and diverse hardware in a consistent way, all while staying fully Kubernetes-native. In the end, the question is no longer whether AI should run on Kubernetes — it is whether your Kubernetes platform is ready to support AI wherever it needs to operate.
Using the k0smos stack as the foundation
The k0smos stack is a unified collection of open-source projects that provides the architectural backbone for running geo-distributed AI infrastructure. It splits responsibilities across three distinct technical layers. At the foundation sits k0s, a fully CNCF-conformant Kubernetes distribution delivered as a single binary with zero external dependencies. Because it makes no built-in assumptions about which CNI, runtime, or package manager to use, k0s runs natively on virtually any Linux environment without modifying the host OS. This lightweight design makes it a flexible underlying runtime that can execute standard Kubernetes workloads across scattered edge nodes, bare-metal servers, and resource-limited VMs.
For managing these deployments at scale, k0smotron serves as the hosted control plane (HCP) engine. It is a Kubernetes operator that launches k0s control planes as isolated, versioned pods inside a central management cluster, fully separating the control plane from the worker nodes. By treating control planes as dynamically scheduled workloads instead of dedicated machines, k0smotron dramatically cuts resource overhead. It supports a remote machine model in which worker nodes in any location — cloud instances, on-prem hardware, or edge devices — can connect back to the central management cluster.
Binding everything together is k0rdent, the declarative management plane for multi-cluster lifecycle orchestration. It wraps the provisioning, configuration, and templating of an entire cluster fleet into Kubernetes-native APIs, enabling a GitOps-driven workflow where clusters are defined, versioned, and audited as infrastructure-as-code. Thanks to its multi-provider support, k0rdent delivers a uniform operational experience whether the underlying infrastructure is bare metal, OpenStack, AWS, vSphere, or any other compute provider — effectively bringing highly diverse hardware environments under a single, standardized platform layer.
Field studies built on top of a geo-distributed heterogeneous AI infrastructure
Building on the k0smos stack described above, we are working alongside the German Federal Agency for Disruptive Innovation (SPRIND). Our joint exalsius project aims to combine fragmented, heterogeneous GPU hardware resources into one unified compute system.
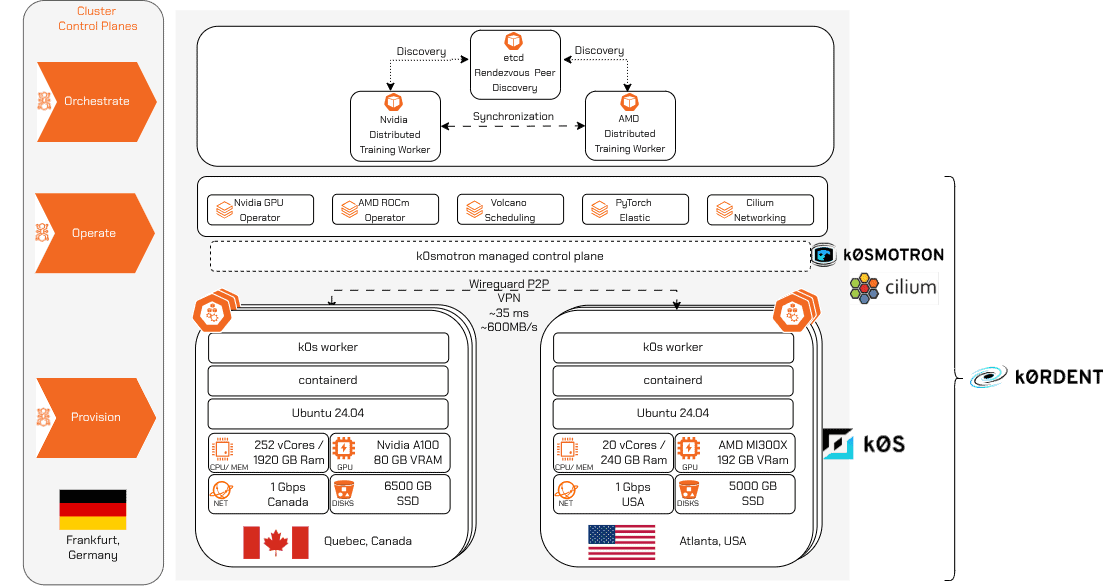
To test this approach, we created an environment that mirrors the fragmented reality of modern AI infrastructure. As shown in the architecture diagram, we connected Nvidia A100 nodes in Quebec with AMD MI300X nodes in Atlanta. The cluster control plane runs on CPU-only nodes in Frankfurt, Germany. This configuration is designed to demonstrate that cross-border, cross-vendor GPU environments can operate as a cohesive whole.
Because the k0smos stack takes care of the underlying cluster lifecycle, we did not need to build custom management infrastructure from scratch. Instead, we layered on components to automatically detect and profile available hardware (essential for optimizing training configurations) and concentrated our engineering efforts on three core areas:
1. Provisioning: We used the k0smotron ClusterAPI provider to launch deployments directly from our management cluster in Frankfurt. The worker nodes in Quebec and Atlanta were set up with k0s along with their respective vendor-specific GPU software stacks — the Nvidia GPU operator for the A100s and the ROCm operator for the MI300Xs.
2. Operation: For cross-site connectivity, we deployed the CNCF project Cilium as our CNI, creating secure, direct WireGuard peer-to-peer tunnels (approximately 35ms latency, around 600MB/s throughput) between the worker nodes. Data plane traffic bypasses centralized VPN gateways entirely, while cluster state continues to be managed centrally in Frankfurt. On top of this network, we integrated AI frameworks such as PyTorch Elastic, Ray, and vLLM using custom k0rdent ServiceTemplates and Helm charts, provisioned through the k0rdent state manager (KSM) using Sveltos.
3. Orchestration: We introduced the operational abstraction and business logic needed to run distributed training and batch workloads reliably over the peer-to-peer network.
Our initial field study confirmed the effectiveness of this architecture by executing consistent, repeatable AI workloads across a fixed, geographically dispersed configuration. We successfully trained a variety of benchmark models—including GPT-NeoX for large language models, ResNet for computer vision, GCN for graph learning, PPO for reinforcement learning, and Wav2Vec2 for audio processing—directly across both AMD and Nvidia nodes.
The key factor enabling this achievement was the joint design of both the infrastructure and the training methodology. To avoid our long-distance peer-to-peer connections from becoming a performance bottleneck, we adopted a distributed, low-communication training strategy based on decoupled momentum optimization (as described in our NeurIPS publications [add-links] and code repository [add-link]). While the underlying systems layer handled execution across diverse hardware, this specialized training approach significantly minimized the need for cross-site data exchange.
This study demonstrated that physical separation and hardware differences are no longer fundamental obstacles to distributed model training. By combining the k0smos stack with our purpose-built orchestration tools, workloads run seamlessly across multiple locations, completely independent of the cloud provider, geographic position, or GPU manufacturer.
In our second field study, we moved beyond the assumption of a static environment to simulate a more realistic operational scenario: a highly dynamic setting where GPU resources join and leave the training pool depending on the availability of surplus electricity. As different geographic locations enter and exit periods of favorable energy conditions, the active computing fabric continuously evolves.
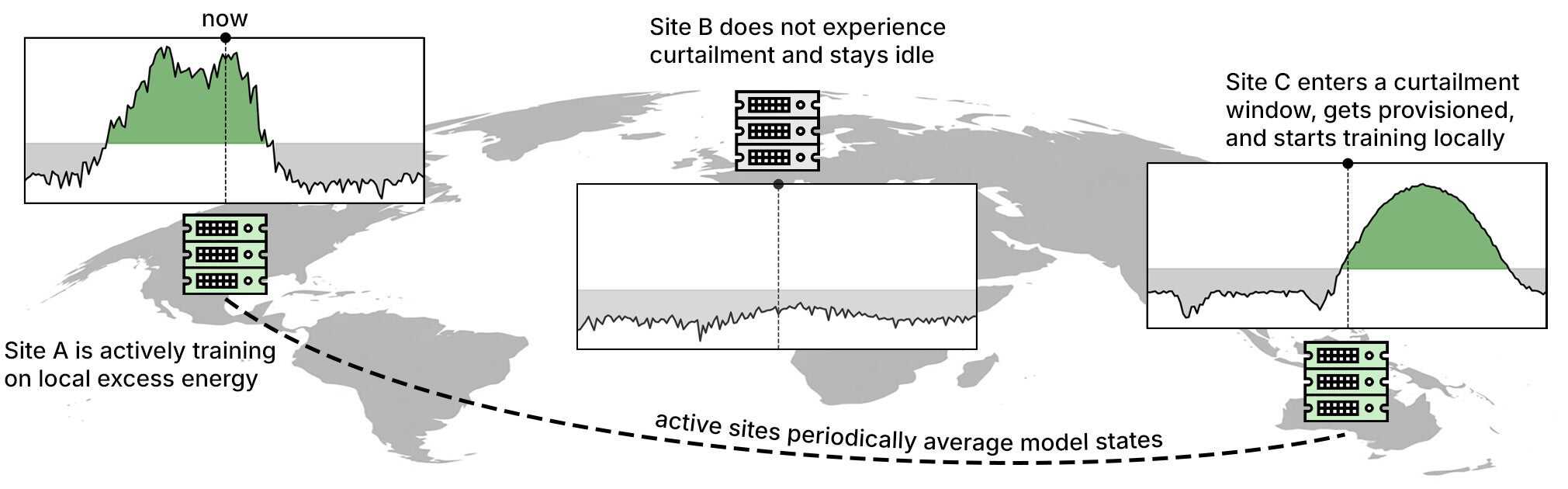
To handle this constant change, we implemented a federated learning approach, treating each location as an independent training domain that synchronizes model state only when active. Building on our k0smos foundation, we engineered this dynamic lifecycle through three core implementations:
1. We created an API that enables the orchestration scheduler to spin up and shut down workers in response to real-time energy availability signals from our non-profit partner, WattTime. A custom k0smotron extension interprets these signals, activating GPU capacity during optimal energy windows and releasing it as conditions shift.
2. We built a custom Kubernetes operator for the Flower AI framework (github links in References). Deployed through the k0rdent state manager (KSM), this operator manages a declarative “Federation” custom resource. Newly provisioned nodes immediately join the federation as available training sites, while decommissioned nodes exit the reconciliation process smoothly.
3. During operation, the coordinator and active sites communicate via gRPC over our established secure peer-to-peer network. We implemented a custom server-side scheduling strategy that uses a Redis Publish-Subscribe queue to reliably distribute round completion notifications and shutdown commands across the transient fleet.
Recently showcased at the Flower AI Summit 2026 and EuroSys 2026, this study confirms that our cloud-native platform scales from static geo-distributed training to dynamic, energy-aware orchestration. For a more in-depth look at the technical specifics and experimental outcomes, read the technical report or explore the code repository (github, report, and presentation links in references).
Conclusion
While the k0smos stack delivered a highly stable, cloud-native foundation, these field studies revealed where challenges persist in fragmented environments: GPU lifecycle management and cross-site networking. In practice, preparing nodes into a clean, GPU-ready state across different locations involves significant complexity. Despite the substantial contributions of the Nvidia and ROCm operators, handling cloud-specific kernels, conflicting pre-installed drivers, and partially configured states demands deep operational expertise. Similarly, while WireGuard and Cilium provided secure cross-site connectivity with minimal bandwidth impact, managing site-specific network constraints and latency-sensitive synchronization for distributed training (such as torch.distributed) remains a sophisticated engineering task.
However, the most promising insight is that running AI workloads across geo-distributed, heterogeneous hardware is fully achievable today. By aggregating isolated GPU capacity into a powerful, unified computing fabric, we can dynamically adjust to evolving execution models without reconstructing the underlying platform. To foster this growing ecosystem, we are actively contributing our customizations and tools back as upstream improvements to the Mirantis k0smos projects, ensuring the broader community can continue to build on this foundation.