



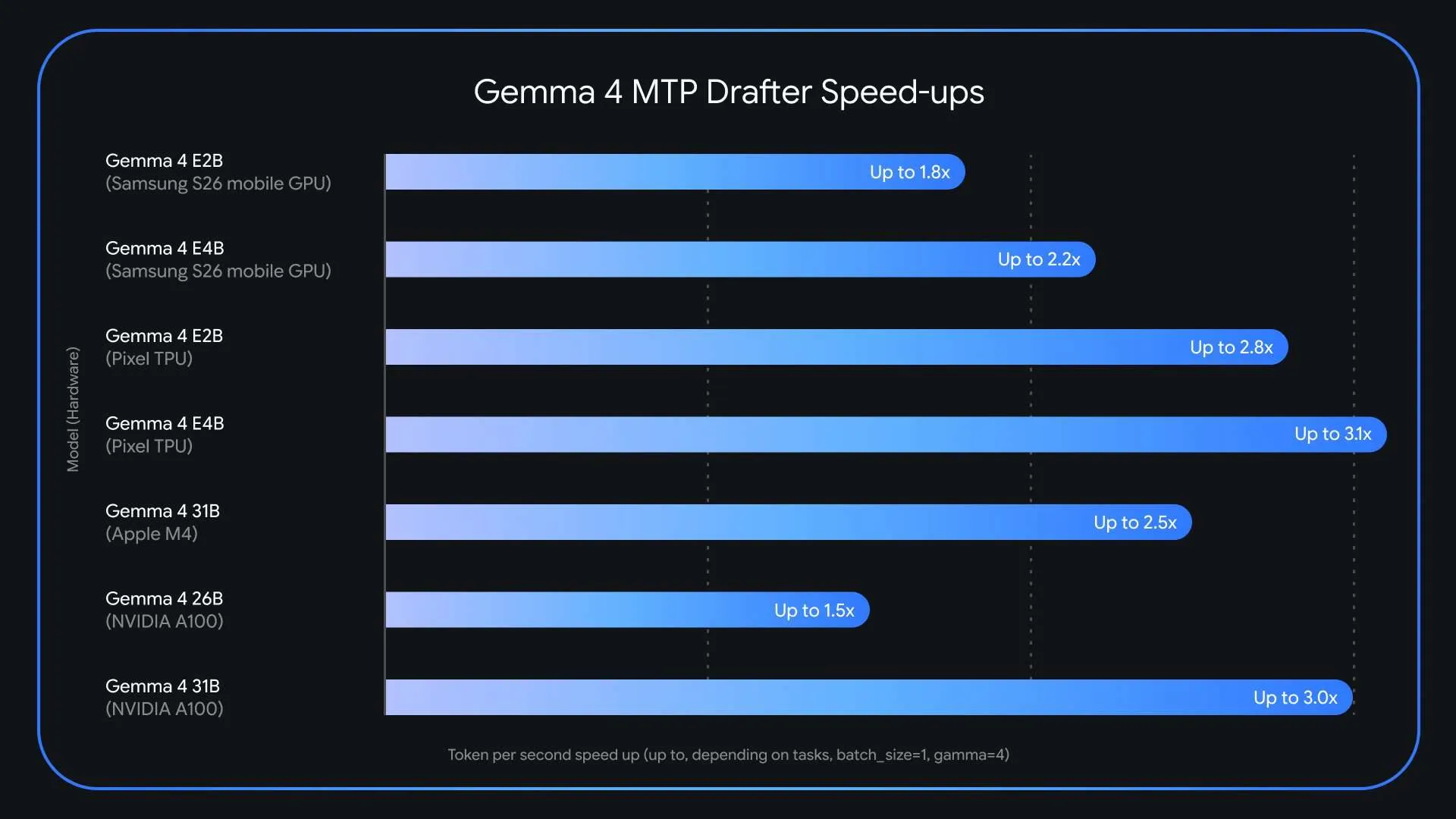
Large language models are becoming remarkably capable, but there’s no denying that their inference speed remains a serious challenge for anyone deploying them in real-world applications. Google has just rolled out Multi-Token Prediction (MTP) drafters for the Gemma 4 model series. This specialized speculative decoding framework can deliver up to three times (3x) faster performance during inference, with zero compromise on output quality or reasoning precision. The launch follows shortly after Gemma 4 crossed 60 million downloads and directly tackles one of the biggest obstacles in large language model deployment: the memory-bandwidth bottleneck that throttles token generation no matter how powerful the underlying hardware is.
Why Is LLM Inference So Slow?
Modern large language models generate text in an autoregressive fashion — they produce one token at a time, in strict sequence. Each token requires the system to load billions of model parameters from VRAM (video RAM) into the compute units. This makes the process memory-bandwidth bound. The limitation isn’t the raw processing power of the GPU or chip itself, but rather how quickly data can be shuttled from memory to the processing cores.
The result is a major latency problem: compute resources sit idle while the system spends its time simply ferrying data back and forth. What makes this even more wasteful is that the model devotes the same computational effort to an easy, predictable token — like guessing “words” after “Actions speak louder than…” — as it does to producing a sophisticated logical deduction. Standard autoregressive decoding has no way to take advantage of how simple or difficult the next token might be.
What Exactly Is Speculative Decoding?
Speculative decoding is the core technique powering Gemma 4’s MTP drafters. The approach separates token generation from verification by combining two models: a lightweight drafter and a much larger target model.
Here’s how the pipeline functions in practice. The small, fast drafter model rapidly proposes a sequence of several future tokens — a “draft” — in less time than the large target model (say, Gemma 4 31B) would need to process even a single token. The target model then checks all of those proposed tokens simultaneously in one forward pass. If the target model confirms the draft, it accepts the whole sequence — and even produces one additional token of its own along the way. This means an application can emit the entire drafted sequence plus one extra token in roughly the same real-world time it would normally take to generate just a single token.
Because the main Gemma 4 model still performs the final verification, the output is exactly what the target model would have generated on its own, token by token. There’s no sacrifice in quality — it’s a completely lossless speedup.
MTP: What Sets the Gemma 4 Drafter Architecture Apart
Google has incorporated several architectural improvements that make the Gemma 4 MTP drafters especially efficient. The draft models directly leverage the target model’s activations and share its KV cache (key-value cache). The KV cache is a widely used optimization in transformer inference that stores intermediate attention computations so they don’t have to be recalculated at every step. By sharing this cache, the drafter sidesteps the overhead of recomputing context that the larger target model has already handled.
On top of that, for the E2B and E4B edge models — the most compact Gemma 4 variants built for mobile and edge devices — Google applied an efficient clustering method in the embedder layer. This specifically targets a bottleneck that’s especially pronounced on edge hardware: the final logit calculation, which translates internal model representations into vocabulary probabilities. The clustering technique speeds up this step, boosting end-to-end generation speed on devices with limited resources.
When it comes to hardware-specific performance, the Gemma 4 26B mixture-of-experts (MoE) model introduces unique routing complexities on Apple Silicon at a batch size of 1. However, bumping the batch size up to between 4 and 8 unlocks as much as a ~2.2x speedup when running locally. Comparable batch-size-dependent improvements are seen on NVIDIA A100 hardware as well.
Key Takeaways
- Google has released Multi-Token Prediction (MTP) drafters for the Gemma 4 model family, delivering up to 3x faster inference with no drop in output quality or reasoning accuracy.
- MTP drafters rely on a speculative decoding architecture that pairs a lightweight drafter model with a heavy target model — the drafter suggests multiple tokens at once, and the target model validates them all in a single forward pass, overcoming the one-token-at-a-time limitation.
- The draft models share the target model’s KV cache and activations, and for the E2B and E4B edge models, an efficient clustering technique in the embedder layer tackles the final logit calculation bottleneck — enabling faster generation even on memory-limited devices.
- MTP drafters are available right now under the Apache 2.0 license, with model weights hosted on Hugging Face and Kaggle.
Check out the Model Weights and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and subscribe to our Newsletter. Wait! Are you on Telegram? Now you can join us on Telegram as well.
Looking to partner with us to promote your GitHub repo, Hugging Face page, product release, webinar, or more? Connect with us