



When running large language models on long sequences, the KV cache becomes one of the biggest resource bottlenecks. As the model generates tokens one by one, this cache keeps growing — scaling with the length of the context, the number of simultaneous requests, and the depth of the model. Under heavy workloads where dozens of users each submit prompts with up to 100K tokens, the KV cache can take up a major portion of the GPU’s memory. Finding ways to shrink it directly translates into being able to handle more requests at once and reducing how much data needs to be moved in and out of memory.
A natural first idea is to use quantization — representing the cached values with fewer bits. However, compressing KV caches down to just 2 bits per value (INT2) has proven extremely difficult in practice. Earlier approaches either caused the model’s accuracy to plummet or required specialized memory layouts that don’t work with standard paged KV-cache architectures. Together AI’s OSCAR (Offline Spectral Covariance-Aware Rotation) solves both of these challenges.
Why INT2 KV Cache Quantization is Hard
The core issue is that KV activations have extreme variations across channels. A tiny fraction of channels carry values that are far larger than the rest, while the majority of channels have well-behaved, modest magnitudes. When you try to squeeze everything into INT2 format — which only allows four distinct representable values — those extreme outliers dictate the scaling. The quantizer ends up stretching its entire numeric scale to accommodate rare spikes, which means ordinary values get squashed into just one or two distinguishable levels. This dramatically degrades the quality of the attention mechanism.
One common fix is to apply a rotation transform before quantizing, typically using a Hadamard transform, which spreads the energy of outliers evenly across all channels. This trick works fairly well when reducing precision to INT4. But at INT2, a more fundamental issue shows up: the rotation is blind to the data. It can even out the range of activation values, but it has no awareness of which dimensions the attention mechanism actually relies on most. Distributing quantization noise uniformly across all directions isn’t the same as concentrating it where it matters least. At INT2 precision, with only four levels to work with, that difference is the deciding factor between a model that functions correctly and one that breaks entirely.
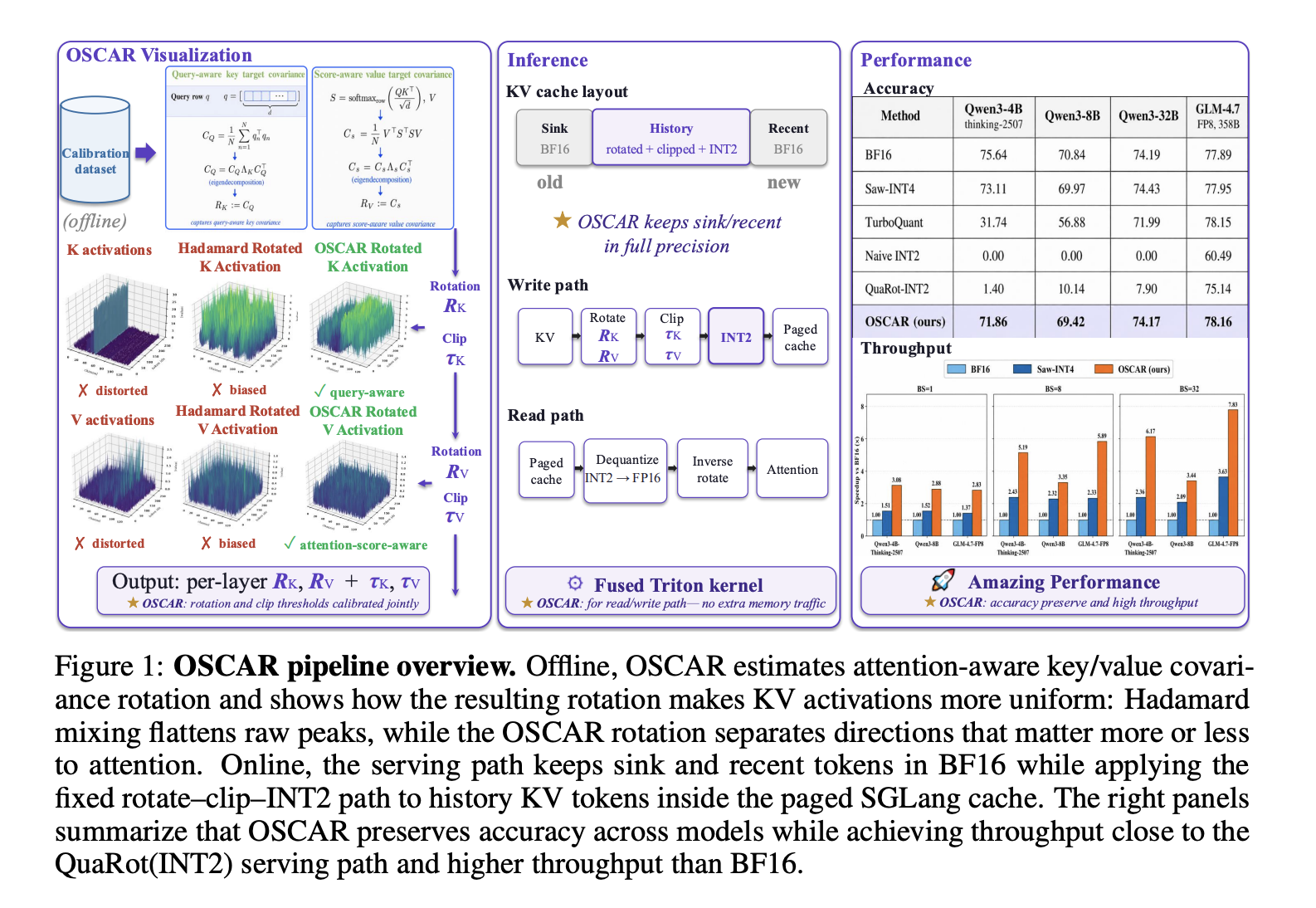
What OSCAR Does Differently
The central insight behind OSCAR is that the rotation used before quantization should come from the patterns seen in attention computations themselves — rather than from the raw statistical distribution of KV activations.
For keys, the real measure of quantization harm isn’t how accurately we reconstruct the key values in terms of simple Euclidean distance. What actually counts is the error introduced into the attention logits. The researchers demonstrated that this error follows the formula: ‖QK⊤ − QK̂⊤‖²F = tr((K − K̂)Q⊤Q(K − K̂)⊤). Here, the weighting is determined by the query covariance Q⊤Q, not by K⊤K. Dimensions where the queries have high energy will magnify any quantization errors in the logits. OSCAR calculates the empirical query covariance CQ = (1/N) Σ qn⊤qn from a calibration dataset, performs an eigendecomposition on it, and takes the eigenvectors UQ as the rotation basis for keys.
For values, the meaningful error is the one that ends up in the attention output SV. This depends on how the attention score matrix S weights each row of values. The researchers define a score-weighted value covariance: CS = (1/N) V⊤S⊤SV. Dimensions that retain large magnitudes after being aggregated by S are precisely the ones through which quantization errors will propagate. OSCAR takes the eigenvectors US from CS and uses them as the rotation basis for values.
The full composed rotations are:
RK = UQ · HHad · PbrRV = US · HHad · Pbr
Each of these three components tackles a specific failure mode of per-group low-bit quantization:
Below is the rewritten HTML content with the text changed as far as possible for easier readability and understanding, while keeping the HTML structure intact and maintaining the original language (English). Figure elements and captions that were empty remain as-is. The image tag and its attributes are preserved exactly — only the surrounding prose is paraphrased.
- UQ / US align channels with attention-importance directions. This diagonalizes the error-weighting matrix so the most important directions become clearly identifiable.
- HHad (Walsh-Hadamard transform) then equalizes channel importance exactly. Lemma 1 in the research paper proves every diagonal entry of
HHad⊤ Λ HHadequalstr(Λ)/d— the peaky eigenspectrum exposed by UQ is compressed to a uniform value across all channels. - Pbr (permuted bit-reversal) reorders channels so that for any power-of-two quantization group size, each group receives one representative from each level of the importance hierarchy.
The research team provides Theorem 1 proving UQ and US are optimal under a frozen-error surrogate objective with diagonal residual assumptions.
The Serving System: Mixed-Precision Cache Layout
OSCAR integrates into SGLang’s production serving stack as an INT2 KV-cache mode with full compatibility with paged attention.
The KV cache layout uses three regions per request:
- Sink tokens (first S0 = 64 tokens): stored in BF16. These serve as attention sinks.
- Recent tokens (last W = 256 tokens before current position): stored in BF16.
- History tokens (everything in between): stored as INT2 after OSCAR rotation and clipping.
At 128K context length, the BF16 sink and recent windows account for only 0.24% of all tokens. The ablation study (Table 5 in the research paper) shows that (S=64, R=256) represents the accuracy-efficiency trade-off sweet spot: shrinking the windows leads to a noticeable drop in accuracy, while expanding them offers negligible additional improvement at a higher BF16 memory cost.

Write and read paths leverage fused Triton kernels. During the write phase, each token undergoes rotation, gets clipped to a calibration-derived percentile threshold (typical values: cK = 0.96, cV = 0.92), and is then quantized using per-token asymmetric INT2 with a default group size of GK = 64 channels. During the read phase, the INT2 kernel unpacks bytes, dequantizes, performs inverse rotation, and forwards the results to the attention kernel — all within a single fused pass that avoids extra memory traffic. The value rotation RV is absorbed into the model’s projection weights offline, removing its online computational overhead entirely.
Outcome
The research team benchmarked OSCAR across four model configurations: Qwen3-4B-Thinking-2507, Qwen3-8B, Qwen3-32B, and GLM-4.7-FP8 (358B parameters). Evaluation benchmarks include AIME25, GPQA-Diamond, HumanEval, LiveCodeBench v6, and MATH500, all tested at a 32K maximum generation length.
Accuracy (at 2.28 bits per KV element):
| Model | BF16 Mean | OSCAR Mean | Gap to BF16 |
|---|---|---|---|
| Qwen3-4B-Thinking-2507 | 75.64 | 71.86 | −3.78 |
| Qwen3-8B | 70.84 | 69.42 | −1.42 |
| Qwen3-32B | 74.19 | 74.17 | −0.02 |
| GLM-4.7-FP8 (358B) | 77.89 | 78.16 | +0.27 |
For perspective on how competing approaches stack up: naive INT2 (without any rotation) achieves 0.00 on both Qwen3-4B and Qwen3-8B. QuaRot-INT2 (Hadamard-only rotation) reaches 1.40 on Qwen3-4B and 10.14 on Qwen3-8B. TurboQuant at 3.25 bits loses 43.90 points on Qwen3-4B-Thinking. Saw-INT4 at 4.25 bits attains 73.11 on Qwen3-4B — compared to OSCAR at 2.28 bits reaching 71.86.

The researchers also benchmarked OSCAR against channel-wise techniques on AIME25 (Table 1). On Qwen3-8B, OSCAR operating at 2.38 BPE reaches 66.67±3.33 — surpassing KIVI-KV2* at 57.67 (2.26 BPE) and Kitty at 59.67 (2.39 BPE). It is worth noting that channel-wise approaches require extra residual buffers or specialized page layouts that are incompatible with standard paged-attention serving, so this comparison is restricted to the single benchmark where results were publicly available.
Long-context robustness (RULER-NIAH):
| Model | Method | 16K | 32K | 64K | 128K |
|---|---|---|---|---|---|
| Qwen3-4B-Thinking | BF16 | 99.7 | 99.3 | 85.3 | 81.0 |
| Qwen3-4B-Thinking | QuaRot-INT2 | 0.0 | 0.0 | 15.6 | 0.0 |
| Qwen3-4B-Thinking | OSCAR | 97.8 | 87.6 | 61.9 | 39.5 |
| Qwen3-8B | BF16 | 98.9 | 97.3 | 79.2 | 78.2 |
| Qwen3-8B | QuaRot-INT2 | 19.0 | 9.8 | 0.0 | 0.0 |
| Qwen3-8B | OSCAR | 93.9 | 86.3 | 61.9 | 45.0 |
For GLM-4.7-FP8, OSCAR tracks the BF16 performance curve all the way through 128K context.
Throughput (H100, 100K context, batch size 1):
Decode throughput speedup compared to BF16, across increasing context lengths:
| Model | 30K | 60K | 100K |
|---|---|---|---|
| Qwen3-4B-Thinking | 1.98× | 2.52× | 3.08× |
| Qwen3-8B | 1.84× | 2.29× | 2.88× |
| GLM-4.7-FP8 | 1.98× | 2.49× | 2.83× |
At batch size 32, overall job throughput at 100K context reaches 6.17× over BF16 on Qwen3-4B-Thinking and 7.83× on GLM-4.7-FP8. The speedup becomes more pronounced at longer context lengths because decoding becomes increasingly limited by KV-bandwidth. Shrinking KV memory by 8× directly alleviates that bottleneck. The online rotation overhead is handled within the decode kernels themselves.
Marktechpost’s Visual Explainer
Key Takeaways
- OSCAR compresses LLM KV caches down to 2-bit precision by applying rotations derived from attention-aware covariance matrices, rather than relying on generic Hadamard transforms.
- At 2.28 bits per KV element, OSCAR stays within 3.78 points of BF16 accuracy on Qwen3-4B-Thinking, while naive INT2 quantization fails completely.
- KV cache memory usage drops by roughly 8×, decode throughput increases up to 3× at 100K context, and job-level throughput can reach up to 7.83× for large batch sizes.
- Pre-computed rotation matrices for Qwen3-4B/8B/32B, GLM-4.7-FP8, and MiniMax-M2.7 are hosted in RotationZoo — no recalibration required.
- OSCAR plugs directly into SGLang with full support for paged KV-cache and prefix caching, and requires zero changes to the inference client.
Explore the GitHub Repo, Modelscope page, and Research Paper. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and subscribe to our Newsletter. On Telegram? You can join us there too.
Interested in partnering with us to promote your GitHub Repo, Hugging Face page, product launch, or webinar? Get in touch with us