



Supertone has unveiled Supertonic 3, the latest version of its on-device, ONNX-powered text-to-speech engine. This release brings support for 31 languages, enhanced pronunciation accuracy, fewer instances of repeated or skipped words, and publicly available ONNX assets that remain compatible with v2. It delivers lightning-fast, on-device, multilingual, and highly accurate TTS.
What’s New from v2 to v3
Relative to Supertonic 2, the new version significantly cuts down on repeat and skip errors, boosts speaker consistency across shared languages, and broadens language support from just 5 to a total of 31. Version 2 covered English, Korean, Spanish, Portuguese, and French. Version 3 now includes Japanese, Arabic, Bulgarian, Czech, Danish, German, Greek, Estonian, Finnish, Croatian, Hungarian, Indonesian, Italian, Lithuanian, Latvian, Dutch, Polish, Romanian, Russian, Slovak, Slovenian, Swedish, Turkish, Ukrainian, and Vietnamese — spanning 31 ISO language codes in all. A special na fallback option is also available for text in languages that are either unidentified or fall outside the supported range.
The model has grown slightly to handle the expanded language set. With roughly 99 million parameters across its public ONNX assets, Supertonic 3 remains far more compact than open TTS systems in the 0.7B to 2B parameter range. This smaller footprint offers real-world benefits in terms of download size, initialization speed, and on-device inference performance. The update also brings the total disk space required for the public ONNX assets to 404 MB. On top of that, Supertone recently introduced the Voice Builder, a tool that lets developers build custom, edge-ready TTS models using their own recorded voice samples.
A notable addition in v3 that was absent in v2 is support for expressive tags. Supertonic 3 recognizes simple expression markers such as
Architecture and Runtime
The core architecture remains consistent with earlier versions: a speech autoencoder that converts waveforms into continuous latent representations, a flow-matching-based text-to-latent module that maps text to audio features, and a duration predictor that governs natural speech timing. Flow matching is a generative modeling approach that learns a vector field to transform a simple distribution into a target one — it samples more quickly than diffusion models at low step counts, which is what enables Supertonic to generate usable output in as few as 2 inference steps. To further enhance output quality, v3 incorporates Length-Aware Rotary Position Embedding (LARoPE) for improved text-speech alignment and applies a Self-Purifying Flow Matching technique during training to maintain resilience against noisy data labels.
In terms of runtime performance, Supertonic 3 runs efficiently on CPU — even outpacing larger baseline models benchmarked on A100 GPUs — while consuming significantly less memory. It has no GPU dependency, making local, browser-based, and edge deployments far more straightforward.
Reading Accuracy
Across the languages tested, Supertonic 3 maintains a competitive WER/CER range compared to much larger open TTS models like VoxCPM2, all while keeping a lightweight on-device deployment profile. WER (Word Error Rate) and CER (Character Error Rate) are standard TTS intelligibility benchmarks: a passage is synthesized, ASR is run on the output, and the transcription is compared against the original text. CER is applied for languages without clear word boundaries, while the rest use WER. The system’s efficiency shines on extreme edge hardware — it achieves an average RTF of 0.3x on an Onyx Boox Go 6 (an E-ink e-reader) running in airplane mode. Additionally, the ecosystem has grown to include Flutter (with macOS support), .NET 9, and Go, while the web implementation uses onnxruntime-web for fully client-side execution.
Text Normalization
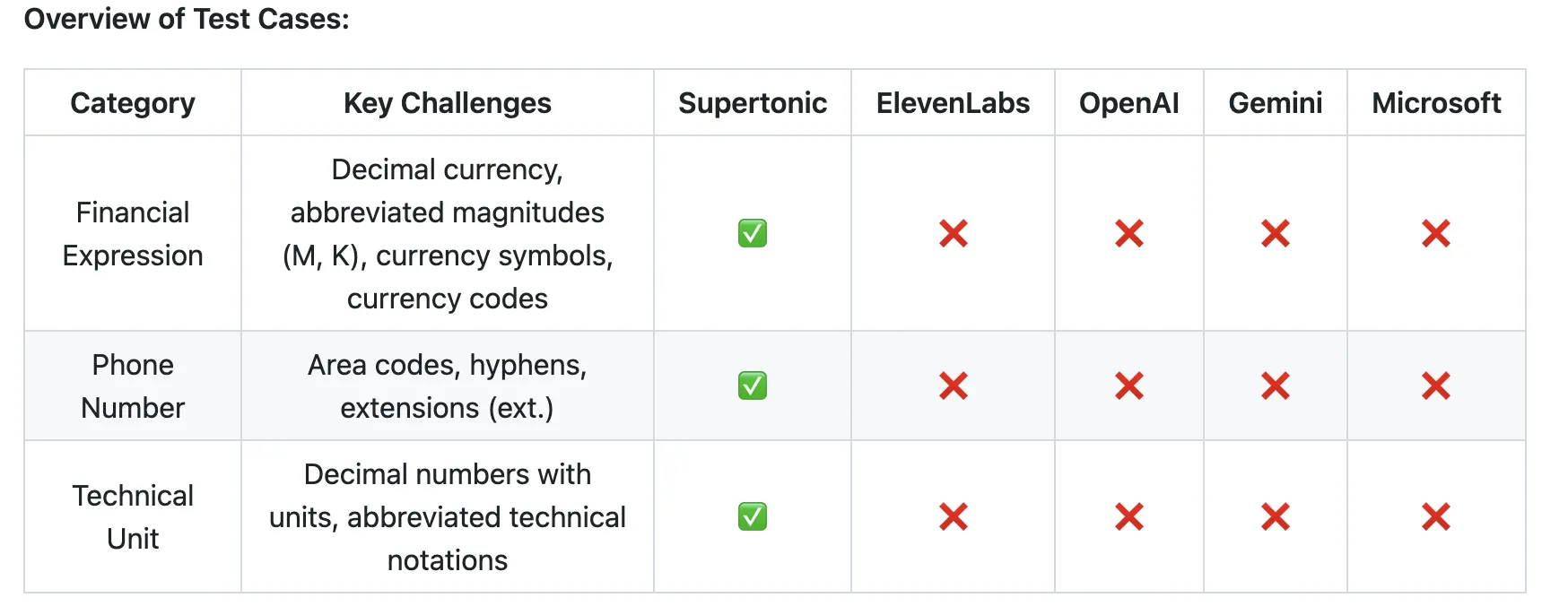
A standover feature carried forward from v2 is built-in text normalization. Supertonic handles complex surface forms — financial expressions like $5.2M, phone numbers with area codes and extensions like (212) 555-0142 ext. 402, time and date formats like 4:45 PM on Wed, Apr 3, 2024, and technical units like 2.3h and 30kph — without requiring any preprocessing pipeline or phonetic annotations. The financial expression “$5.2M” should be read as “five point two million dollars,” and “$450K” as “four hundred fifty thousand dollars.” All four competing systems failed on this front. The technical unit “2.3h” should be read as “two point three hours” and “30kph” as “thirty kilometers per hour.” All four competitors failed this category as well. The competing systems evaluated include ElevenLabs Flash v2.5, OpenAI TTS-1, Gemini 2.5 Flash TTS, and Microsoft.
—
Getting Started
To install the Python SDK, simply run pip install supertonic. The first time you use it, the required model files will be automatically downloaded from Hugging Face. Here’s a basic usage example:
from supertonic import TTS
tts = TTS(auto_download=True)
style = tts.get_voice_style(voice_name="M1")
text = "A gentle breeze drifted through the open window as everyone listened to the story."
wav, duration = tts.synthesize(text, voice_style=style, lang="en")
tts.save_audio(wav, "output.wav")
print(f"Generated {duration:.2f} seconds of audio")Marktechpost’s Visual Guide
Key Takeaways
- Supertonic 3 broadens language coverage from 5 (v2) to 31 languages, scaling from 66M to roughly 99M parameters, with a total ONNX model size of 404 MB
- New in v3: expressive tags (
- Backward-compatible public ONNX interface — existing integrations can upgrade without modifying inference code
- Reading accuracy benchmarked against VoxCPM2; v3 remains within a competitive WER/CER range while being significantly more compact
- v3-specific RTF and throughput figures have not been released; the 167× faster-than-real-time metric is a v2 benchmark and should not be taken as identical for v3
- Native output of 16-bit WAV files ensures high-fidelity audio suitable for engineering use cases
Check out the GitHub Repo and Hugging Face Space. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and subscribe to our Newsletter. Wait — are you on Telegram? You can now join us on Telegram as well.
Looking to partner with us to promote your GitHub Repo, Hugging Face Page, Product Release, Webinar, or more? Connect with us