



Poetiq has released impressive new findings demonstrating that its Meta-System achieved a state-of-the-art result on LiveCodeBench Pro (LCB Pro), a competitive programming benchmark, by automatically constructing and refining its own inference harness — all without fine-tuning any underlying model or accessing model internals.
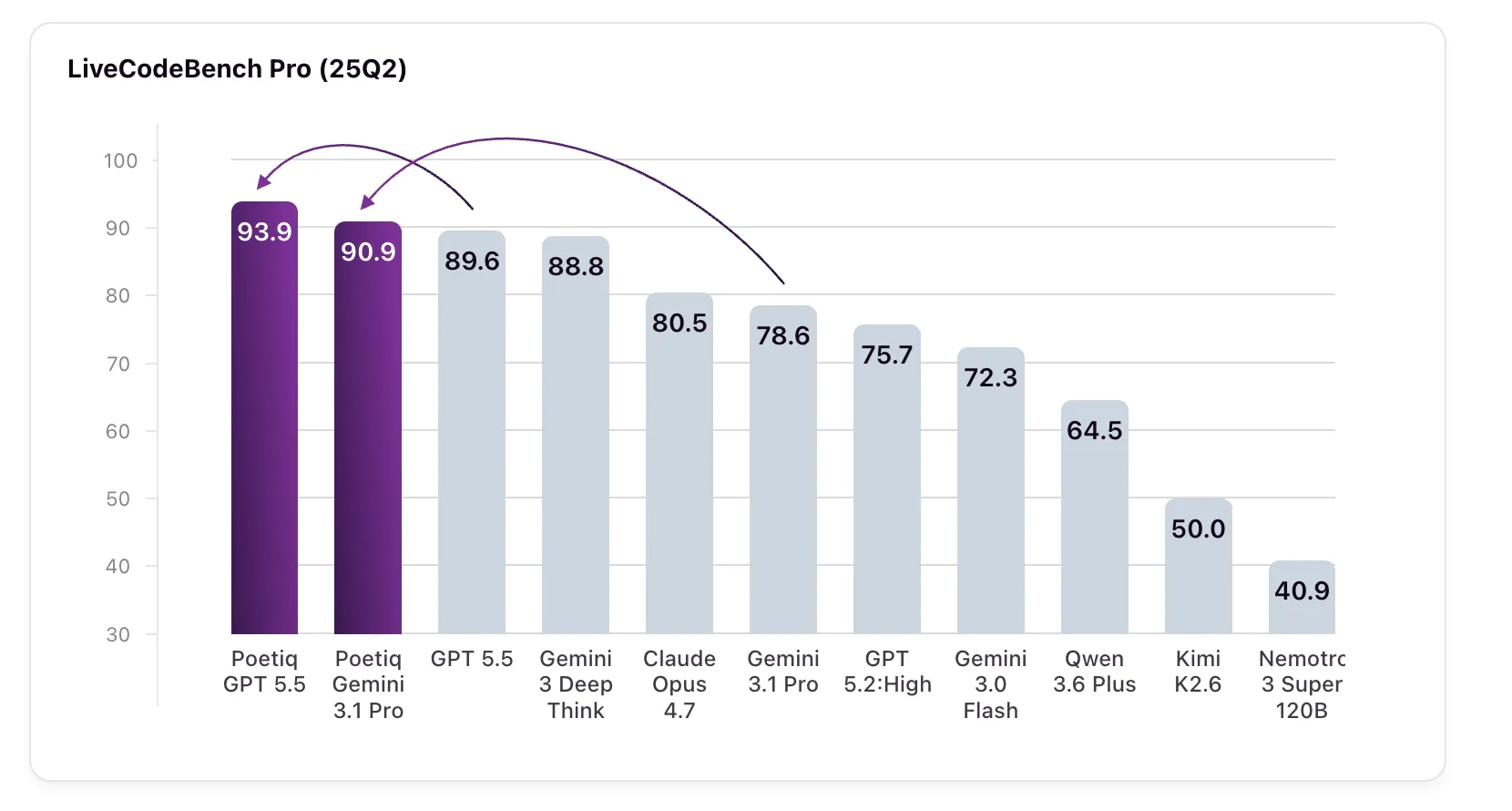
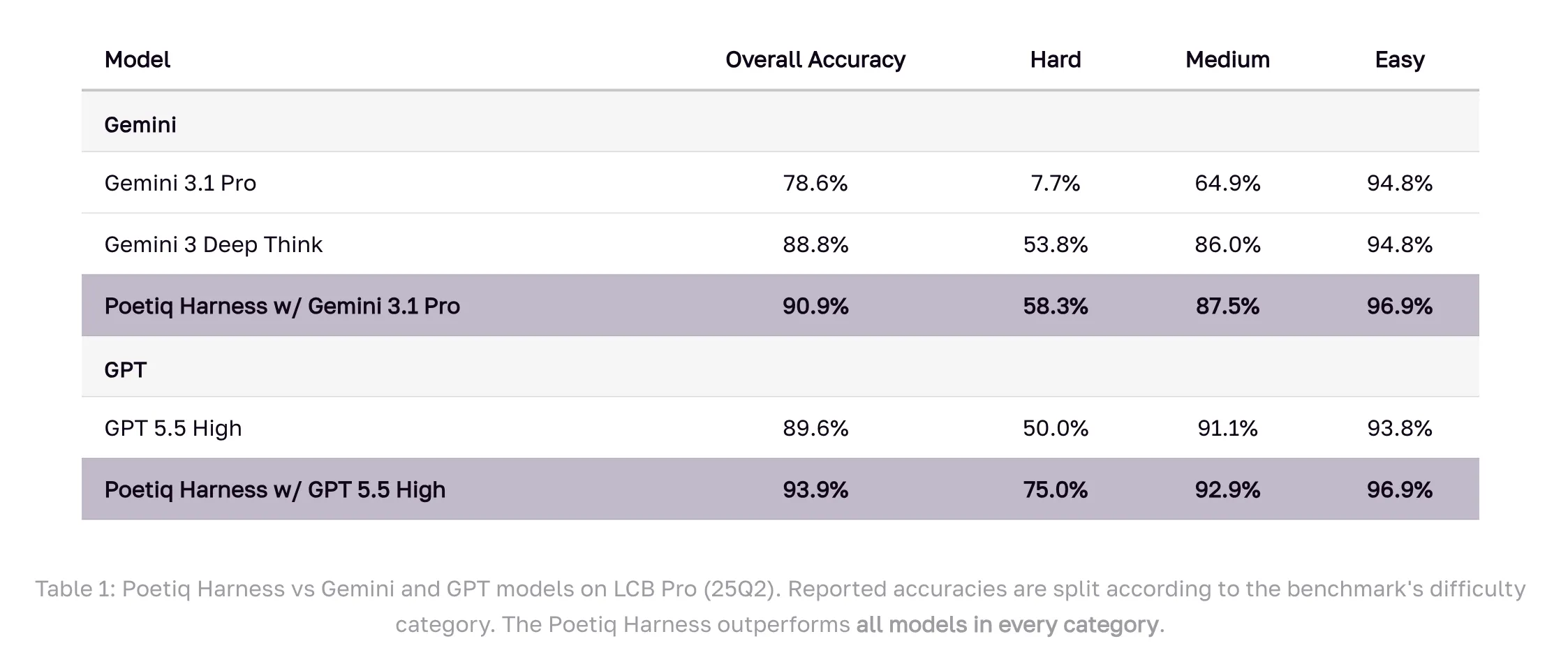
The outcome: GPT 5.5 High paired with Poetiq’s harness scores 93.9% on LCB Pro (25Q2), rising from its baseline of 89.6%. Gemini 3.1 Pro, the model the harness was specifically optimized for, climbs from 78.6% to 90.9% — exceeding Google’s own Gemini 3 Deep Think (88.8%), a model that isn’t even available via API for external verification.
What is LiveCodeBench Pro?
Before diving into the technical details, it’s worth understanding why this benchmark is significant. LiveCodeBench Pro (LCB) is built to evaluate AI coding skills in a way that avoids two common pitfalls in benchmarks: data contamination and overfitting.
LCB Pro sources problems from major competitive programming contests and keeps the official reference code private. Rather than just checking for correct answers, solutions are run through a thorough testing framework. Getting the right output isn’t sufficient — solutions must also meet defined memory and runtime limits. The benchmark is also regularly updated, which sets it apart from many standard benchmarks that quickly become outdated.
The benchmark centers on C++ challenges and emphasizes creative coding, assessing a model’s ability to tackle complex problems and produce high-quality, efficient procedural logic. This makes it different from datasets like SWEBench, which focus on tool usage or bug-fixing workflows. Problems are ranked by difficulty — Easy, Medium, and Hard — based on how often competitive programmers solve them successfully.
Poetiq’s Strategic Approach: Three Core LLM Task Types
This marks Poetiq’s third publicly shared benchmark, and the selection of LCB Pro was intentional. The team organizes LLM performance into three core task types: Reasoning tasks (measured using ARC-AGI), Retrieval tasks (assessed via Humanity’s Last Exam, or HLE), and Coding tasks — which represent the most widespread commercial use of AI today, blending reasoning and retrieval with the creation of specialized procedural logic.
Their coding effort had three clear goals: first, show that a smart harness can enhance performance without fine-tuning or privileged model access; second, confirm the Meta-System’s ability to recursively self-improve in building that harness autonomously; and third, prove the harness works across any model without changes. Based on their findings, all three goals were met.
Understanding Harnesses and Their Importance
Here, a harness describes the framework built around a language model to tackle a particular task. You can think of it as an orchestration layer — it manages how the model receives prompts, how outputs are formatted, how responses are combined across multiple calls, and how final solutions are assessed.
Typically, engineers craft these harnesses manually. Poetiq’s key claim is that their Meta-System designs and refines these harnesses on its own, through recursive self-improvement. Behind the scenes, the Meta-System evolves by developing sharper strategies for deciding what questions to pose, refining chains of sequential questions, and inventing new approaches for piecing together answers. The system continuously draws on insights from past and current tasks and datasets to generate new, tailored task-specific harnesses — as well as agents and orchestrators for other task categories.
Building the Harness
Poetiq’s Meta-System was tasked with the LCB Pro challenge and built a harness entirely from the ground up, using Gemini 3.1 Pro as the sole base model. The Meta-System addressed all three dimensions that LCB Pro evaluates: accuracy, runtime efficiency, and memory limits. The system leveraged knowledge gained from its earlier work on ARC-AGI and HLE when engineering the harness. No fine-tuning of the underlying model was involved, and no access to internal model activations was needed — just standard API access.
After the harness was developed and fine-tuned for Gemini 3.1 Pro, it was then deployed across a wide range of other models spanning different providers and generations — both open-weights and proprietary — with no further adjustments. Every single model showed improvement.
The Results
The benchmark outcomes across difficulty levels deserve a closer look. On Hard problems — the tier where performance gaps between models are most pronounced — Gemini 3.1 Pro paired with Poetiq’s harness achieves 58.3%, a dramatic jump from its 7.7% baseline. GPT 5.5 High with the harness hits 75.0% on Hard, up from 50.0%. Across Easy and Medium tiers, the harness also surpasses all base models.
Results from smaller models are equally impressive. Gemini 3.0 Flash gains 10 percentage points, climbing from 72.3% to 82.3% — outperforming Claude Opus 4.7, Gemini 3.1 Pro, and GPT 5.2 High, all of which are larger and costlier models. This echoes a trend Poetiq previously saw on ARC-AGI, where their optimization enabled a smaller, more budget-friendly model to overtake a larger one. Kimi K2.6 records the biggest leap: from 50.0% to 79.9%, an improvement of roughly 30 percentage points. Nemotron 3 Super 120B gains 12.8%.
Accuracy figures are sourced directly from the LCB Pro leaderboard at livecodebenchpro.com (25Q2). For models not listed on the leaderboard, Poetiq ran its own evaluations, verifying its experimental setup by reproducing official leaderboard accuracies for baseline models.
Key Takeaways
- Poetiq’s Meta-System autonomously constructs task-specific harnesses via recursive self-improvement, requiring no model fine-tuning or internal model access
- GPT 5.5 High with the harness achieves 93.9% on LCB Pro (25Q2), a 4.3% gain from its 89.6% baseline; Gemini 3.1 Pro surges 12.3% (78.6% → 90.9%)
- The harness is model-agnostic: built using only Gemini 3.1 Pro, it boosted every other model tested — both open-weights and proprietary — without any modifications
- Gemini 3.0 Flash rises 10 percentage points with the harness (72.3% → 82.3%), overtaking Claude Opus 4.7, Gemini 3.1 Pro, and GPT 5.2 High despite being smaller and more affordable
- Kimi K2.6 delivers the largest improvement at ~30 percentage points (50.0% → 79.9%); Nemotron 3 Super 120B gains 12.8%
Check out the technical details here. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and subscribe to our newsletter. Wait — are you on Telegram? Now you can join us on Telegram as well.
Looking to partner with us to promote your GitHub repo, Hugging Face page, product release, webinar, or more? Connect with us