



Once a human stops fine-tuning them, most AI agents stop getting better. The underlying model stays the same, and so does the infrastructure built around it. Hexo Labs aims to evolve both simultaneously. This week, the company open-sourced SIA (Self-Improving AI) under the MIT license.
The central — and deliberately narrow — claim behind SIA is this: within a single self-improvement loop, it can modify both the agent’s surrounding infrastructure and the model’s internal weights.
What is SIA (Self-Improving AI)
SIA divides a task-specific agent into two layers. The first layer is the harness (sometimes called the scaffold), which includes the system prompt, tool-routing logic, retry rules, and answer-parsing code. The second layer is the model’s weights themselves.
Three large-language-model components power the loop. A Meta-Agent generates an initial scaffold from a task description and any available reference code. A Task-Specific Agent then runs the job while logging every step of the process. After completion, a Feedback-Agent reviews that full trajectory and determines what adjustments need to be made.
This decision-making step is the core innovation. Following each run, the Feedback-Agent chooses one of two paths: it can revise the scaffold while keeping the model weights frozen, or it can apply a weight update while leaving the scaffold unchanged.
The base model is openai/gpt-oss-120b. For weight updates, SIA uses LoRA — a low-rank adapter — set at rank 32. Both the Meta-Agent and the Feedback-Agent run on Claude Sonnet 4.6. All training is executed on H100 GPUs via Modal, the team’s reinforcement-learning platform.
The team defines two operating modes: SIA-H and SIA-W+H. SIA-H applies harness changes only. SIA-W+H layers weight updates on top of harness edits.
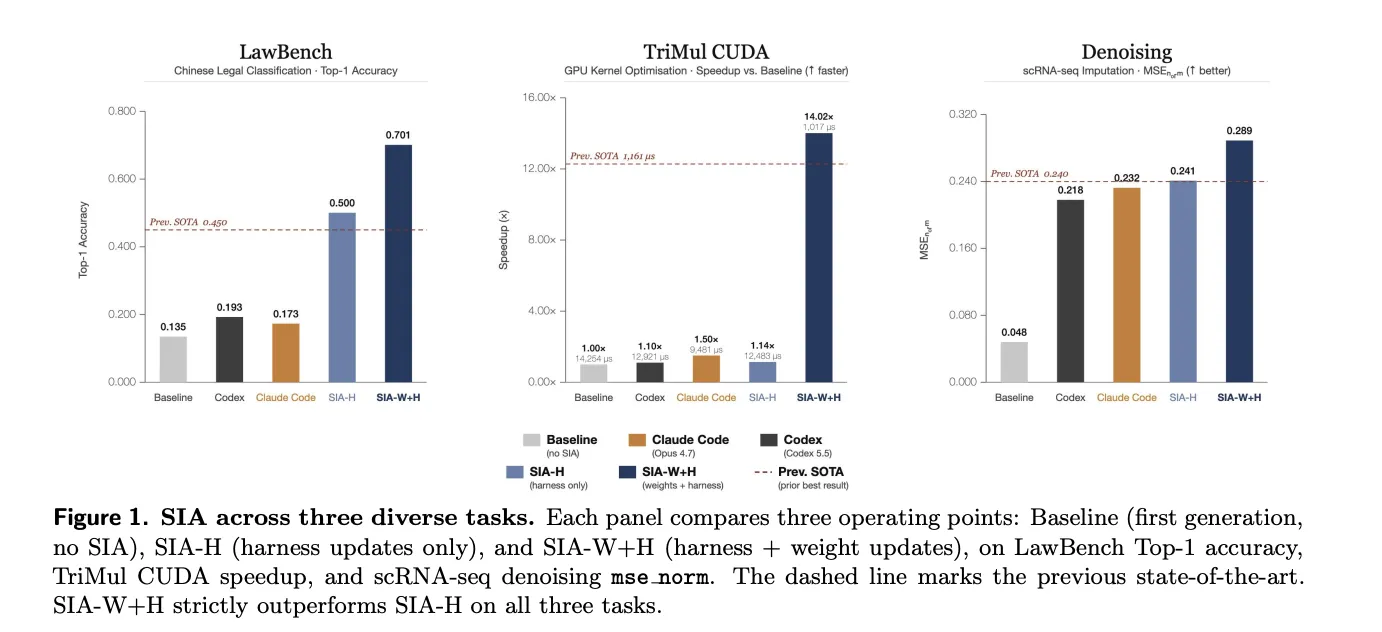
The Benchmark Case
The team evaluated SIA across three deliberately diverse domains. A consistent pattern emerged: weight updates consistently delivered gains beyond what scaffold modifications alone could achieve. “Initial” represents the Meta-Agent’s first scaffold running against the base model, before any feedback loop has fired.
| Task | Initial | Prev. SOTA | SIA-H (harness only) | SIA-W+H (harness + weights) |
|---|---|---|---|---|
| LawBench (top-1 acc) | 13.5% | 45.0% | 50.0% | 70.1% |
| AlphaEvolve TriMul (reward) | 0.105 | 1.292 | 0.120 | 1.475 |
| Denoising (mse_norm) | 0.048 | 0.240 | 0.241 | 0.289 |
On LawBench, the challenge is a 191-class Chinese criminal-charge classification task. Repeated harness iterations constructed a TF-IDF plus LinearSVC pipeline and leveled off at 50.0% accuracy. Subsequent weight updates through PPO pushed performance up to 70.1% — a 20.1 percentage-point improvement over the harness-only ceiling.
The TriMul task requires writing a custom CUDA kernel for an H100 GPU. The kernel implements a core operation in AlphaFold2’s Evoformer module. Scaffold editing alone achieved a 1.14× speedup over the baseline. Weight updates then slashed runtime from 12,483 µs to 1,017 µs — a 91.9% reduction from the harness-only peak.
The results chart includes an important qualification: the coding assistant Claude Code achieved a 1.50× speedup on TriMul without any help, outpacing SIA-H’s 1.14× result. SIA-W+H still delivered the best overall outcome at 14.02×.
For the denoising task, the agent optimizes MAGIC, a single-cell RNA imputation method. Harness sweeps across hyperparameters settled at an mse_norm of 0.241. After the first weight-update checkpoint, the agent introduced a two-step line that no scaffold iteration had ever generated — it rounded imputed counts to non-negative integers, lifting the score to 0.289.
How the Feedback-Agent Picks Its Move
SIA doesn’t rely on a single fixed RL recipe. The Feedback-Agent chooses a training algorithm based
The reward signal it observes guides its approach to improvement.
On LawBench, since the reward was a clear, outcome-based numerical value, the team employed PPO with GAE. On TriMul, where most kernels did not compile successfully, they applied entropic advantage weighting—a technique that gives more importance to uncommon high-reward outcomes. For the denoising task, they adopted GRPO, which removes the need for a value network altogether.
The researchers also reference REINFORCE with KL-to-base, DPO, and best-of-N behavioral cloning. Each method aligns with a different reward structure and carries its own set of potential failure risks.
Strengths and Points to Consider
Strengths:
- According to the authors’ comparison table, this is the first system to modify both the agent scaffold and model weights within a single loop.
- Delivers consistent improvements over previous state-of-the-art methods across three distinct and unrelated domains.
- Open source under the MIT license, installable as sia-agent, and comes with four pre-packaged tasks.
- The choice of algorithm adapts based on the rewards observed, rather than following a predetermined sequence.
Points to Consider:
- The study reports results from three tasks; wider algorithm-selection findings are reserved for future work.
- Both optimization levers target the same fixed verifier, which introduces the risk of tightly coupled Goodhart effects.
- The researchers caution that the joint fixed point may prove fragile if subjected to outside disturbance.
Marktechpost’s Visual Guide
01 / 09
Key Takeaways
- SIA is the first self-enhancing loop capable of editing both an agent’s scaffold and its model weights in tandem.
- After each run, a Feedback-Agent reviews the entire trajectory and decides between a scaffold rewrite or a weight update.
- Using both levers together surpassed scaffold-only optimization on every task tested: LawBench, TriMul kernels, and scRNA-seq denoising.
- Scaffold edits contribute software-engineering rigor; weight updates unlock domain knowledge inaccessible through prompting alone.
- Open source under MIT (hexo-ai/sia), running on gpt-oss-120b with LoRA rank 32.
Explore the Repo and Research Paper. Also, feel free to follow us on Twitter—and don’t miss our 150k+ ML SubReddit and Newsletter subscription. Are you on Telegram? You can join us there too.
Looking to collaborate on promoting your GitHub Repo, Hugging Face Page, Product Release, Webinar, or similar? Get in touch with us