In my earlier piece, “From Code to Insights: Software Engineering Best Practices for Data Analysts,” I mentioned how engineering skills and best practices are hugely valuable for analysts and other data professionals.
This holds even greater relevance today, in the AI era, where we have many more chances to build our own analytical tools — from sophisticated data viewers that render charts or present various scenarios, to simulators capable of forecasting outcomes based on given parameters. In my daily work, I rely on web applications constantly.
Vibe coding has generated a buzz, yet professional developers are already past it and gravitating toward spec-driven development. Even Andrej Karpathy, who introduced the term “vibe coding” in February, conceded just a year after that this phase is winding down and we are stepping into the age of agentic engineering — coordinating agents against precise specifications with human supervision.
Today (one year on), programming through LLM agents is rapidly becoming the standard workflow for professionals, though with greater oversight and scrutiny. The aim is to capture the productivity boost from using agents without sacrificing any software quality. Many have attempted to coin a better label to separate this from vibe coding — personally, my current favorite is “agentic engineering”:
– “agentic” because the norm now is that you aren’t writing code directly 99% of the time — you’re orchestrating agents who do it while serving as quality gate.
– “engineering” to stress that there is craft, science, and skill involved. It’s something you can study and master, rich with its own form of depth.
In this post, I’d like to apply spec-driven development hands-on to a project from scratch, following the practices from JetBrains’ DeepLearning.AI course, “Spec-Driven Development with Coding Agents”.
The project is somewhat more personal but still centered around data. As I gear up for my half marathon in September, I’m juggling running and strength training. There are countless tools available, each addressing a different slice of the puzzle, so finding one solution that genuinely fits my needs has been harder than I expected. So, I chose to kill two birds with one stone: build my own web app while hopefully picking up some new skills along the way.
Ready to dive in? So am I. But before we get into the code, let me take a few minutes to lay out the theory behind spec-driven development.
Vibe coding vs Spec-driven development
Most of us have already tried vibe coding: you type a brief prompt (say, “Please add a DAU chart to my web app”), let the agent produce the change, run it locally, and see if the output matches what you had in mind.
More often than not, it doesn’t. So you return to the same chat, ask the agent to tweak the chart, and keep iterating until the result is acceptable.
This method works fine for small projects, but it falls apart at scale, particularly when several developers share the same codebase.
The biggest downsides are the absence of best practices and shared conventions. Without a structured approach, teams can easily end up with five different ways to run ML model training within the same DBT pipeline.
Another frequent problem is that we rarely save the outcomes or reasoning from our AI agent conversations. This makes it easy to lose sight of why certain choices were made. For instance, an agent might forget why you cleaned data a particular way, and the next update could quietly produce a different result.
Context decay is another widespread issue. AI agents are stateless, and on larger projects we often have to start fresh chats due to context window limits, essentially resetting our communication from zero.
Spec-driven development (SDD) aligns much more closely with traditional engineering practices. Rather than jumping straight into coding, we begin by doing the hard thinking ourselves: making architectural choices, defining requirements, and recording them in a structured markdown spec stored in the repo and updated as the project progresses. This creates a crucial shift: we separate the specification (what we’re building and why) from the implementation (the actual code).
SDD tackles many of the core pain points of vibe coding by preserving context across sessions (and even across different AI agents) while keeping both humans and agents aligned around the project’s key non-negotiables.
SDD workflow
A typical spec-driven development workflow generally includes the following stages.
The first step is defining the constitution — an agreement on the project’s key decisions. It usually consists of several core documents:
- Mission explains the why: why are we building this project, and what are its primary goals and features?
- Tech Stack records technical decisions, along with deployment and update processes.
- Roadmap outlines project phases, planned features, and is continuously updated as the project evolves.
Specifications can be written for both new and existing projects, which makes this approach quite flexible.
Once the project-level documentation is set up, we can move into the feature development phase, which typically involves:
- Understanding what we want to build and drafting a detailed specification.
- Implementing the changes.
- Verifying that the implementation works as intended.
After you’ve successfully shipped your first feature, you might feel the pull to jump straight into the next one. But this is actually the perfect moment to pause and reflect.
This is where replanning comes in. It’s a dedicated phase for revisiting the constitution and reviewing previous feature decisions and plans to ensure they still match the project’s goals.
Now that we’ve gone through the theory, let’s put it into action.
Building
Enough theory — time to build. To get a clearer picture of how spec-driven development works in practice, I decided to apply it to a real greenfield project.
I began by creating a new repository for this project (and, naturally, spending half an hour picking the name and logo): repository. I also captured my initial product vision in the README.md file.
One of the appealing aspects of the SDD approach is that it is largely agnostic to the choice
You’re free to choose your preferred development setup—whether it’s built around an LLM, an agent framework, or an IDE. For my part, I’ll be working in Visual Studio Code using the Claude Code extension. This lets me leverage Claude as an agent while also reviewing every code change directly within the editor.
Drafting a Constitutional Agreement
As mentioned earlier, our first step is to draft a constitution. There’s no need to do this from scratch—we can leverage LLMs to construct it based on the preliminary product vision, supplemented by additional context gathered through follow-up questions.
We are building Trainlytics, a personal fitness tracking web app tailored
for individuals who crave greater control, flexibility, and deeper insights
than traditional fitness apps offer. Review the complete requirements in README.md.
Let's compose a "constitution" in a specs directory comprising three sections:
- mission.md - outlining the product's core purpose and mission
- tech-stack.md - summarizing foundational technical decisions
- roadmap.md - delineating project phases in chronological order of implementation
IMPORTANT: You must use your AskUserQuestion tool to collect my feedback.The agent then poses a variety of clarifying questions that help shape the project’s constitutional framework and lay out the initial implementation strategy.
Ultimately, the agent generated the three requested files.

At this stage, you might feel tempted to immediately ask the agent to begin building the project, but it’s best to pause.
Before advancing any further, we must first validate and fine-tune the constitution. Investing time now to reach consensus on the plan is crucial, since this specification will eventually evolve into thousands of lines of code. It’s far wiser to iron out any ambiguities and errors at this early juncture.
My usual approach is to review the documents myself and iterate with the agent through clarifying questions, gradually refining the plan step by step. A solid practice is to direct all modifications through the agent rather than manually editing documents yourself, ensuring consistency across the entire project. For instance, I specified to the agent that we need authentication built into the app, since my workflow involves logging workouts from both my desktop and mobile devices. This prompted updates to both the tech stack document and the roadmap.

Once the review is satisfactory, you can also enlist a second agent—with a fresh perspective—to critically evaluate the plan. There’s substantial evidence that reflective processes enhance output quality.
After all validations pass, it’s time to commit the constitution to the repository.
Starting the First Feature Phase
Now, we can move on to the initial feature phase.
Per our roadmap, we’ll begin with the MVP: Core Activity Logging. By the conclusion of this phase, users should be able to sign in from both desktop and mobile, log a run and a gym workout, and view both entries in their history with complete details.
As outlined before, each feature phase follows a straightforward cycle: plan → implement → validate. So let’s begin by drafting the specification and formulating the plan.
Locate the next phase in specs/roadmap.md and create a new branch,
prompt me about any steps in the specs that aren't entirely clear.
Then establish a new directory formatted as YYYY-MM-DD-feature-name under specs/
for this feature, containing the following files:
- plan.md - a structured list of numbered task groupings
- requirements.md - scope, key decisions, and relevant context
- validation.md - our definition of success and criteria for confirming
the implementation is merge-ready
Use specs/mission.md and specs/tech-stack.md as reference.Tip: It’s beneficial to start a fresh session with clearly defined context in your LLM agent.
The agent assembled the specifications swiftly.

Once again, it’s time to review the specs and confirm alignment with the original vision. As you’ll notice with the agentic engineering paradigm, the developer’s role pivots toward guiding, reviewing, and making high-level architectural choices—rather than directly authoring specifications or code.
Once you’re satisfied with the plan, it’s time to proceed with implementation. I prefer tackling one group of tasks at a time rather than attempting to implement the entire feature phase in one go, though depending on the feature’s scope, that approach may also work. For this project, I used the following prompt.
Take the next task group from 2026-05-04-phase-1-mvp/plan.md and implement it.
Refer to requirements.md and validation.md for guidance.
Once complete, update the status in both the plan and validation documents.When the code is ready, it’s time for review. This is one of the most critical steps, so dedicating adequate time here is well worthwhile.
In data-centric applications, I typically concentrate my review on the core business logic and verify that the results align with my expectations.
I’ll be upfront—I have virtually no expertise in frontend technologies, so I rarely inspect frontend code in granular detail. Instead, I simply run the interface locally and verify whether everything functions as intended. For this particular case, I decided to fire up the app and see it in action.
After several iterations with the agent, we got the app running locally, and it worked. We can already add various exercises and activity categories, and log both cardio and strength sessions.
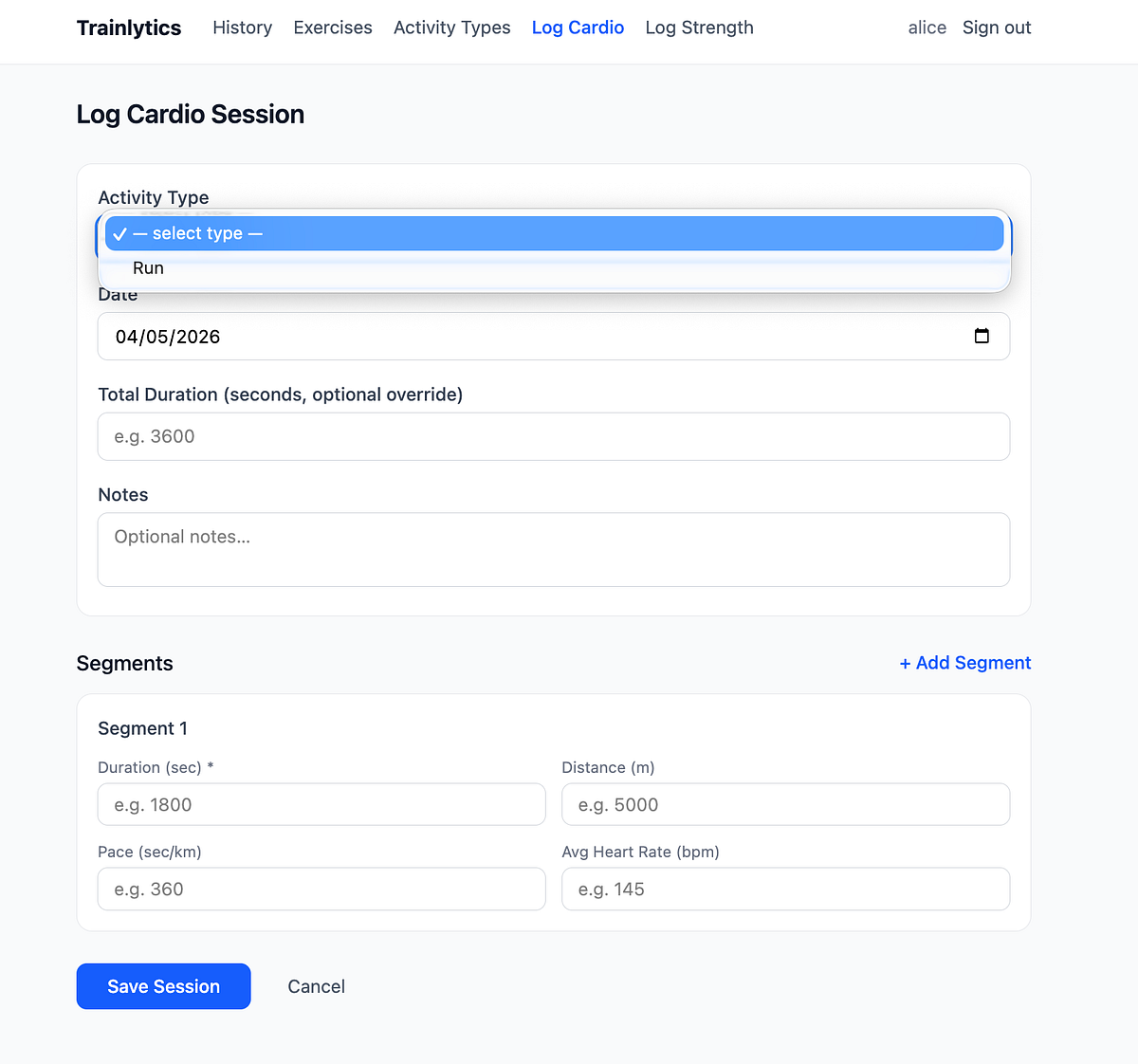
Following the manual review, it’s also valuable to employ reflection by asking a fresh agent to assess whether the implementation aligns with the plan, as well as to review the checkpoints outlined in validation.md.
In theory, spec-driven development dictates that the feature phase concludes with validation. In practice, it seldom works out that neatly. You’ll probably discover that certain parts of the implementation don’t behave as expected. At that point, you have two options:
- Add additional iterations to your
plan.mdand continue refining the feature (this works well for smaller- If the issues are minor, address them directly (small tweaks, quick fixes), or
- If the problems are more significant, incorporate them into the next feature phase and address them during replanning.
One key pitfall to avoid: it’s easy to fall into the habit of just describing the problem to the LLM agent and requesting a fix, rather than updating the specifications and reworking the implementation from there. Try to avoid that shortcut. Maintaining the specification as the single source of truth is what makes this approach reliable and scalable.
Once all validations are done, we can create and merge the pull request.
At this stage, we already have a fully functional application, and the outcome is genuinely impressive. Even more remarkably, the entire process took just over two hours from start to finish (including writing this article while the agent was running).
Replanning
With such solid progress, you might be eager to keep building. I get that, but in today’s AI-driven landscape, the primary value a human brings is strategic thinking and architectural insight. So this is actually the perfect time to pause and reflect: do we still want to continue down the same path, and what should we adjust in our product and workflow?
When I began using the application myself, I realized it wasn’t yet ready to fully support my specific use case. That means we need to reprioritize so I can start integrating it into my daily routine as quickly as possible. So, I did it with the following prompt.
Let's revise our plan in roadmap.md. I would prioritise the next phases as follows: 1. Strength session templates I can live without planning, but I need templates, because I often struggle to remember all the exercises in a session. The idea is: - If a template already exists in the log, show all stats (exercises, sets, reps, weight, etc.). Allow editing these values and committing changes - If anything is changed, ask whether the user wants to update the template 2. UI improvements The current design is not yet sleek enough, so I'd prioritise a round of UI improvements: - Add the logo and product motto to the website - Add a settings tab to manage activity types and exercises - Create a single screen to log both cardio and strength sessions - Improve the history screen with richer activity details - Allow adding titles to activities (strength/cardio sessions) and segments - Support specifying time, not only date - Add more color to the interface (I like shades of blue) - For cardio exercises, adjust units to: minutes, kilometers, and min/km pace 3. Basic analytics Add simple analytics to the history screen showing weekly stats at the top of the page (e.g. total minutes and calories split between cardio and strength).Replanning is also a good opportunity to revisit our process itself. For instance, I noticed that we haven’t kept
roadmap.mdup to date consistently, and the specs are beginning to drift. It would also be helpful to introduce a changelog, giving us a clear record of how the product has evolved over time.Let’s ask the agent to handle that for us.
Please review plan.md, update roadmap.md to reflect completed work, and create a CHANGELOG.md file with a concise summary of the changes.Now that we’re aligned on direction and have the right setup in place, let’s keep building.
The next phase
Now we can follow the same process and iterate through phases. Since this is a repeatable cycle, it’s a good time to discuss potential automations.
So far, we’ve been crafting all prompts manually, but these workflows can also be automated as “skills” in Claude Code or other LLM coding agents.
Additionally, there are already ready-to-use implementations of spec-driven development. One of the most popular is Spec Kit by GitHub.
You can install it like this.
uv tool install specify-cli --from git+ specify version # to check that it worksNext, you need to initialize the skills in Claude. This sets up the
.specify/folder and installs slash commands into.claude/commands/specify init . --integration claude # there are 30 integrations with agents so specify the one you're usingYou’ll know it worked when you see the
speckitcommands in Claude Code.
Image by author Once installed, you can follow a similar workflow: start by defining the constitution, then iterate through feature loops.
One difference is that in Spec Kit, the constitution is more focused on high-level concerns like code quality, testing standards, UX consistency, and performance requirements.
To be honest, I slightly prefer the approach proposed by JetBrains, because it keeps more context in the constitution itself. But as always, there’s no silver bullet and Spec Kit may work better depending on your use case. It’s also convenient that you have the SDD workflow already implemented for you.
Using Spec Kit, I ran through the two phases described above, and it worked well. After the first feature phase, development naturally becomes a continuous improvement cycle rather than a linear process. And with that, I think it’s time to wrap up this story.
Summary
In total, it took me around 4.5 hours to build a usable end-to-end product for tracking and analyzing my data. There’s still plenty of room for improvement, and I’ll continue iterating on it. I can already see several potential UI enhancements, and I’d also like to eventually integrate AI to make the app more intelligent.
Frankly speaking, it has been an interesting experience working through such a structured development flow. In my day-to-day work, I often rely on one-off LLM chats to make changes, without maintaining a full trace of decisions and specifications in the repository.
However, there’s no one-size-fits-all approach here.
- If you just want to make a small improvement or run some ad-hoc analysis in yet another Jupyter notebook, writing full specifications upfront is probably overkill.
- But when you’re working on a larger project (especially with other people), spec-driven development would definitely be my default approach.
It’s also interesting to observe how the role of an engineer is shifting: from writing code directly to focusing more on architectural decisions, review, and system design.
And while it may sound a bit extreme today, I do think we’re gradually moving toward a world where English becomes the primary “programming language” interface. We’re already seeing early attempts in this direction, such as CodeSpeak, which explore more natural-language-driven programming paradigms. I’ll try CodeSpeak in my next article, so stay tuned.
Reference
This article is inspired by the “Spec-Driven Development with Coding Agents” short course from DeepLearning.AI.