



Since 2013, Amazon Redshift has brought cloud-based data warehouse power to users at a cost far lower than traditional on-premises systems. With each new architectural evolution—starting with dense compute, moving to Amazon RA3 instances, and expanding into Amazon Redshift Serverless—queries have consistently become more affordable, faster, and more resource-efficient.
For more than ten years, as organizations have expanded their data volumes and analytics needs have grown more complex, many have adopted a dual approach: using data warehouse tables for structured, actively-used data while relying on data lakes to store diverse datasets affordably. The introduction of AI agents into this ecosystem means these automated systems now query your warehouse at rates that far exceed typical human interaction, driving up operational expenses.
Amazon Redshift has strengthened its foundational capabilities to satisfy the requirements of any workload—whether initiated by people or AI agents. As an illustration, in March 2026, Amazon Redshift accelerated business intelligence (BI) dashboards and ETL tasks by delivering new queries up to seven times faster. These gains dramatically enhance the responsiveness of low-latency SQL operations critical to near-real-time analytics, BI dashboards, ETL pipelines, and independent, goal-oriented AI agents.
Today, we’re unveiling Amazon Redshift RG instances—a cutting-edge instance family built on AWS Graviton processors. RG instances elevate performance, executing data warehouse workloads up to 2.2 times faster than RA3 instances while costing 30% less per vCPU. Their built-in data lake query engine empowers you to run SQL analytics spanning both your data warehouse and data lake using one unified engine, delivering performance up to 2.4 times faster than RA3 for Apache Iceberg and up to 1.5 times faster than RA3 for Apache Parquet. This combination of enhanced speed, lower costs, and a merged data lake query engine positions Redshift RG instances as an ideal fit for managing today’s intensive query demands and stringent latency requirements in analytics and agentic AI workloads.
You can contrast the new RG instances alongside the current RA3 instances below:
| Current RA3 Instance | Recommended RG instance | vCPU | Memory (GB) | Primary Use Case |
ra3.xlplus | rg.xlarge | 4 | 32 | Small cluster departmental analytics |
ra3.4xlarge | rg.4xlarge | 12 → 16 (1.33:1) | 96 GB → 128 GB (1.33:1) | Standard production workloads, medium data volumes |
This strategy cuts total analytics expenses for customers handling combined data warehouse and data lake workloads while streamlining operations with a single system for querying both warehouse tables and Amazon Simple Storage Service (Amazon S3) data lakes. We suggest using the AWS Pricing Calculator with your specific workload patterns to gauge projected savings.
Getting started with Amazon Redshift RG instances
You can spin up new clusters or transition existing ones through the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS API. The integrated data lake query engine comes enabled by default.
Within the Amazon Redshift console, simply select the new RG instances when you set up a cluster.
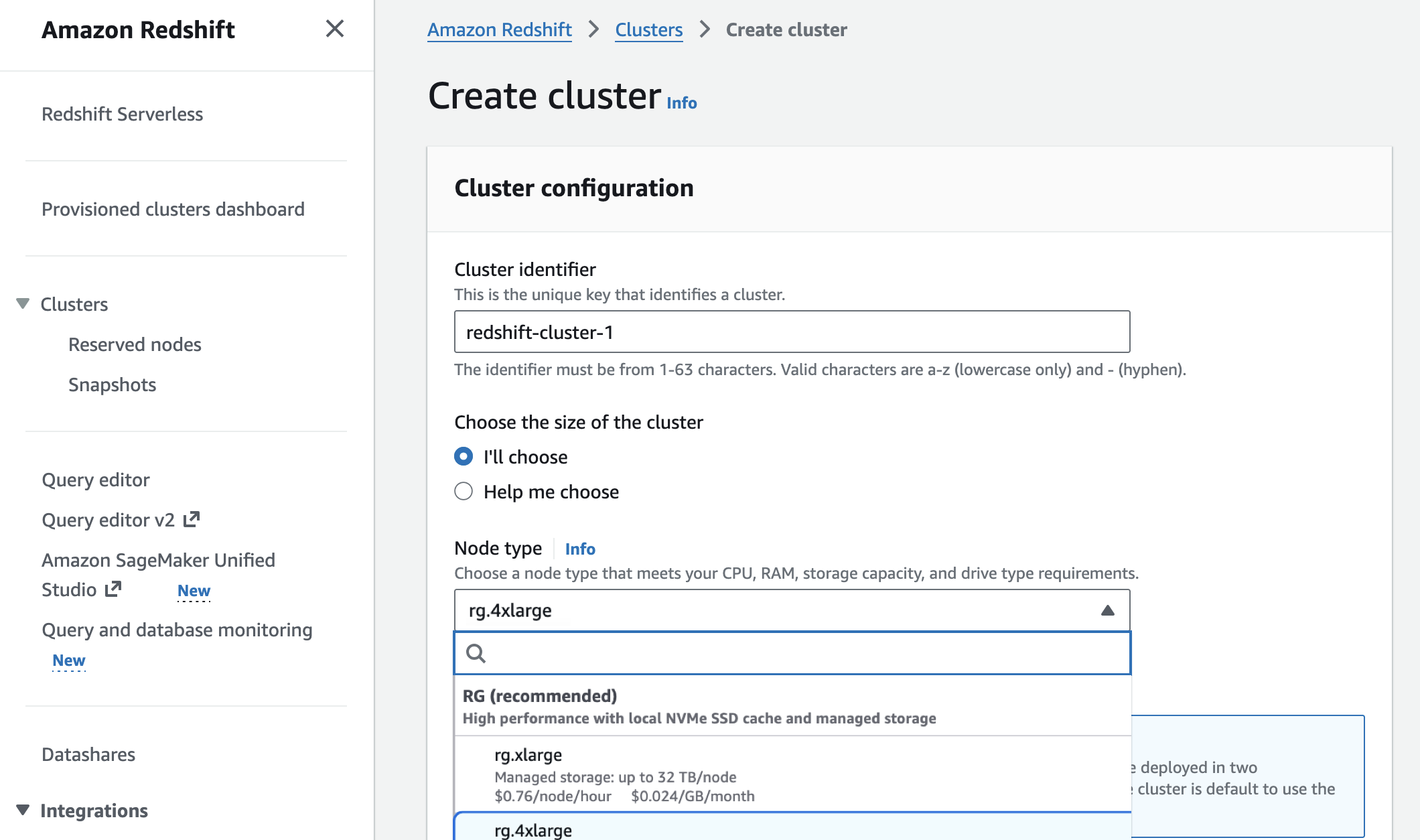
You can transition prior-generation instances to RG instances through ideal migration paths tailored to your cluster setup, letting you forecast costs, confirm compatibility, and automate the migration process.
- Elastic Resize—an in-place migration causing 10–15 minutes of downtime for compatible configurations
- Snapshot and Restore—build a new RG cluster from an RA3 snapshot. This works best for customers wishing to adjust configurations during the transition
Your external tables, schemas, and query syntax—including all existing Spectrum queries—carry over without changes. You won’t need to rebuild external tables or alter any application code. For further details, check out the Redshift Management Guide.
Amazon Redshift now processes data lake queries directly on cluster nodes—the identical compute resources handling data warehouse workloads. As a consequence, Amazon Redshift Spectrum is no longer necessary. Data lake queries remain contained within your VPC, leverage current IAM roles, and carry zero per-terabyte scanning charges—effectively eliminating the $5/TB Spectrum scanning charges that previously inflated total Redshift costs.
Now available
Amazon Redshift RG instances are now live in the following AWS Regions: US East (N. Virginia, Ohio), US West (N. California, Oregon), Asia Pacific (Hong Kong, Hyderabad, Jakarta, Malaysia, Melbourne, Mumbai, Osaka, Seoul, Singapore, Sydney, Taiwan, Tokyo), Canada (Central), Europe (Frankfurt, Ireland, Milan, London, Paris, Spain, Stockholm), Middle East (UAE), and South America (São Paulo). For Regional availability and upcoming plans, explore the AWS Capabilities by Region. For Redshift Provisioned, you can opt for On-Demand Instances billed hourly without commitments, or choose Reserved Instances to maximize cost savings. To learn more, see the Amazon Redshift Pricing page.
Test out RG instances in the Redshift console and share your feedback at AWS re:Post for Amazon Redshift or reach out through your standard AWS Support contacts.
— Channy