



Over the last couple of years, digital sovereignty has shifted from being a topic of policy debate to a hands-on concern for platform engineering teams. The EU Data Act became fully enforceable on January 11, 2025. Regulations like NIS-2 and DORA are already influencing everyday platform decisions across regulated industries, and the UK Data Use and Access Act 2025 is being phased in throughout 2026, bringing strict data portability rules into play.
Because of this, platform teams are now expected to show not just where their workloads are hosted, but also how their infrastructure is managed, secured, and governed. Inquiries about control planes, encryption keys, admin access, audit trails, and workload portability are now appearing right alongside traditional data residency demands.
For teams building cloud-native platforms, this creates a significant architectural challenge. While choosing the right regional infrastructure still matters, many sovereignty requirements ultimately come down to how control, access, and operational responsibility are spread across the entire platform stack.
This article looks at how Kubernetes-based platforms can meet these demands, and why the design of the control plane is becoming a more and more critical piece of the sovereignty puzzle.
What “sovereign” truly demands from a platform
When you break down what regulators, auditors, and procurement teams consistently ask for, four key properties keep coming up:
- Jurisdictional containment. Every component that has the ability to read tenant data — including the control plane — operates under a legal jurisdiction the organization can clearly identify and justify.
- Operational autonomy. The team responsible for running a workload should be able to rebuild, migrate, and audit it without relying on any single vendor’s managed services.
- Cryptographic and access control. Encryption keys, etcd data, and admin credentials must remain inaccessible to any entity outside the designated jurisdiction.
- Portability. If the underlying hardware, cloud provider, or country needs to change, the workload should be able to move without requiring a rewrite.
For those building sovereign clouds, these aren’t just regulatory checkboxes. The location of the control plane, where metadata is stored, who has administrative access, how encryption and key management are handled — all of these must be explicitly defined. Backup strategies and support access models must also respect jurisdictional boundaries. None of this is addressed simply by saying “we chose Frankfurt.” It’s addressed by making infrastructure decisions that extend all the way down to the control plane.
Why a single Kubernetes cluster isn’t enough
When constructing a sovereign platform, these requirements become impossible to ignore. Kubernetes acts as the central foundation that ties them all together and provides the right base for sovereign platforms. Its CNCF backing, declarative APIs, and open ecosystem — including Kyverno for policy, Argo CD and Flux for GitOps, KubeVirt for VMs, Cilium for networking, and SPIFFE/SPIRE for workload identity — are precisely the components that regulated enterprises in the region are rallying around. The Swisscom sovereign Kubernetes reference architecture published on architecture.cncf.io is a strong indicator of where the industry is headed.
As soon as you begin applying real sovereignty requirements to a single cluster, the shortcomings become apparent:
- One control plane serves every tenant. A jurisdictional issue impacting one tenant’s data plane could potentially affect all workloads sharing the same API server, etcd, and controllers.
- Namespaces don’t provide true isolation. Even with robust RBAC, custom resource definitions are shared, admission webhooks are shared, and a misconfigured controller can leak across the cluster.
- Cluster sprawl becomes the default workaround. Running a full Kubernetes cluster per jurisdiction, per environment, per team. This is operationally burdensome, costly, and slow to adapt.
In real-world scenarios, operators frequently run shared platforms that support several regulated environments at the same time, each with its own operational, compliance, and residency requirements.
For instance, a provider might run separate EU and UK tenant environments, each supported by its own regional infrastructure, storage, and audit boundaries, as illustrated below:
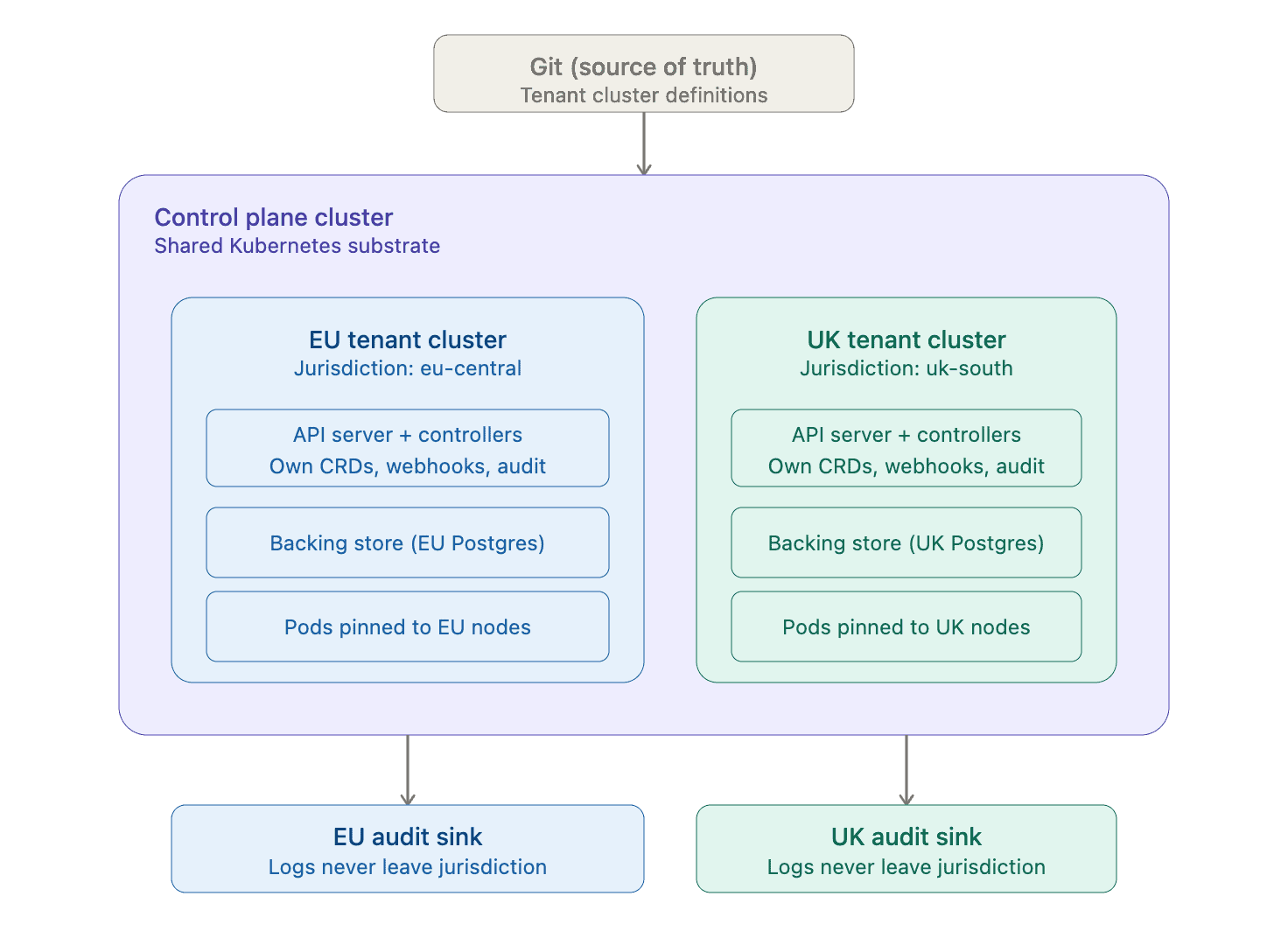
Pic: Sovereign Design, which isn’t Sovereign (From Sovereign: What It Means)
The problem with the setup above is that simply placing workloads in different regions doesn’t guarantee sovereignty. Even when tenant workloads run in separate regions, a shared Kubernetes control plane still centralizes administrative authority, policy enforcement, APIs, controllers, and critical operational decisions. Wherever that control plane is located and whoever has governance over it ultimately determines the platform’s true sovereignty boundary.
Tenant clusters as a sovereignty primitive
The architectural pattern worth understanding here is the tenant cluster: a dedicated Kubernetes control plane carved out for a single isolation boundary, running on top of a shared underlying cluster. Each tenant cluster comes with its own API server, its own controller manager, its own scheduler, and its own data store. From the workload’s point of view, it’s communicating with a genuine, conformant Kubernetes cluster. From the platform’s perspective, the tenant cluster’s control plane operates as a collection of pods on a shared Control Plane Cluster.
One widely adopted way to implement this pattern is vCluster, an open-source project that provisions tenant clusters as pods within an existing Kubernetes cluster. We’ll use it as the primary example throughout the rest of this post because it’s straightforward to experiment with locally, but the architectural principles apply to any solution that gives each isolation boundary its own control plane.
Several characteristics of tenant clusters are directly relevant to sovereignty.
Independent control planes. Each tenant cluster has its own API server and its own backing
The backing store for a tenant cluster can be an embedded etcd instance, an external etcd deployment, or a SQL database. Each tenant’s custom resources, admission webhooks, and audit logs remain strictly isolated from other tenants. Because each tenant has its own control plane, they can run different Kubernetes versions, follow independent upgrade schedules, and use different platform configurations. This level of separation becomes increasingly valuable as the number of tenants grows. Treating each cluster as a distinct jurisdictional boundary provides meaningful isolation.
Flexible storage options. The tenant cluster’s state can be stored on encrypted volumes on hardware you control, managed by whichever operator you prefer. This gives you the ability to design for data residency, not just workload placement.
Full tenant isolation, not shared namespaces. Workloads running inside a tenant cluster have no access to the host cluster’s API. For even stronger isolation at the container level, you can pair the tenant cluster with a user-namespace runtime like vNode, or use gVisor or Kata Containers when a VM-level boundary is needed. This is especially important for AI cloud providers, where the security concerns typically include both container escape risks and the need to prevent tenants from seeing each other’s workloads on shared infrastructure.
Easy workload migration. A tenant cluster provides a standard Kubernetes API. Any workloads running inside it can be moved to any compliant Kubernetes environment, whether managed or self-hosted. Switching from a hyperscaler-backed cluster to a sovereign provider or bare metal doesn’t require rewriting your applications.
The overall approach is simple. Platform teams manage a small number of underlying Kubernetes clusters, while each tenant, jurisdiction, or regulated workload gets its own dedicated tenant cluster. Sovereignty boundaries become clearly defined resources that you can declare, audit, and relocate, as illustrated here with vCluster:
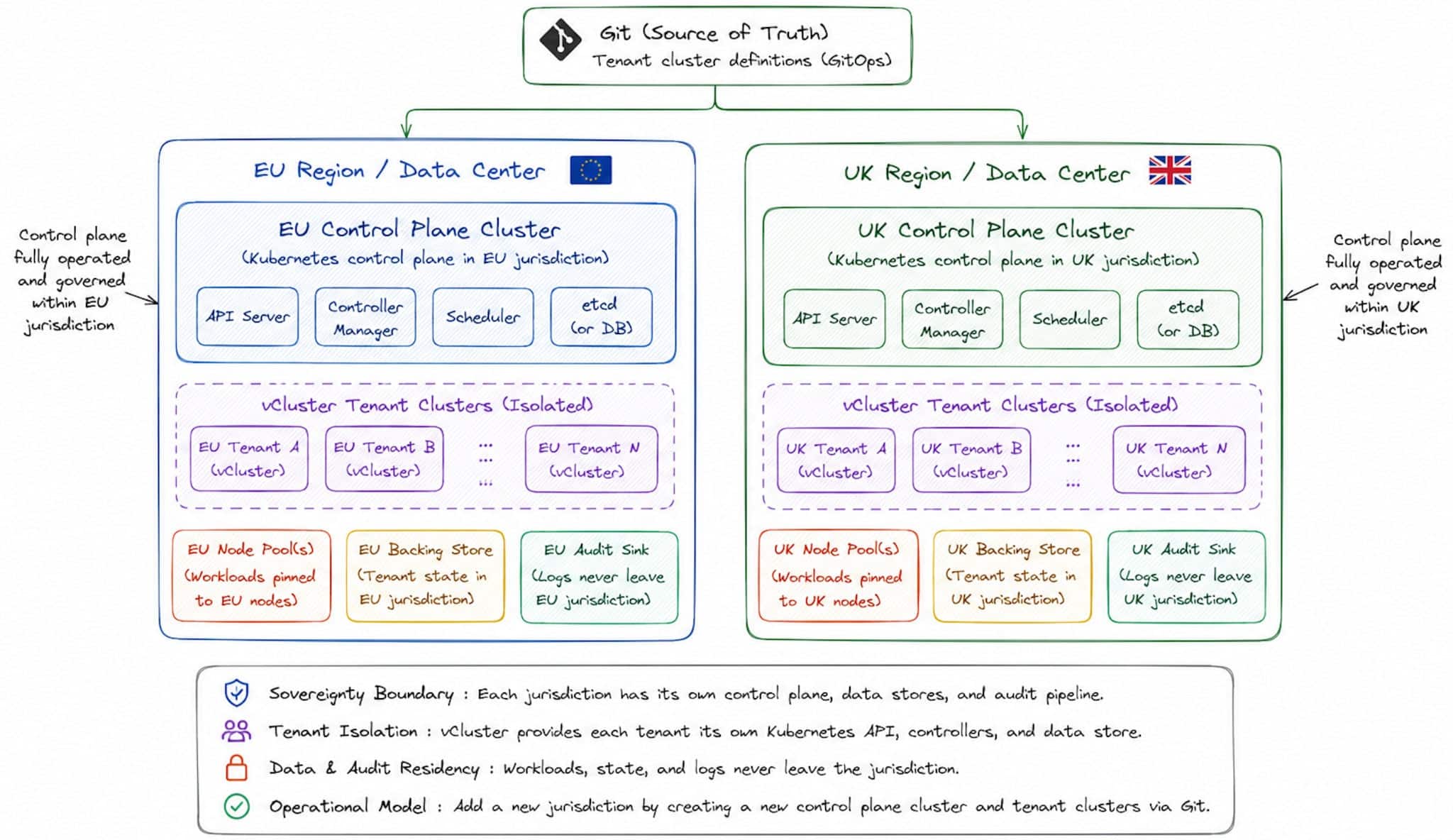
In practice, this typically means deploying one underlying control plane cluster per sovereign jurisdiction or data center, with isolated tenant clusters created for customers within that boundary.
For instance, an EU control plane cluster might exclusively serve EU-based tenants, while a separate UK control plane cluster independently handles UK customers. This setup lets each tenant operate its own Kubernetes control plane without needing a dedicated physical cluster per customer.
A practical approach: treating jurisdictions as clusters
Imagine a SaaS company with customers in both the EU and UK. Under the EU Data Act, all customer data, audit logs, and metadata for EU-based tenants must stay within EU jurisdiction and remain portable. UK customers are governed by the Data Use and Access Act 2025, which has similar but not identical requirements. Same product, two separate sovereignty boundaries.
A clean solution is to create one tenant cluster per jurisdiction, defined as Kubernetes resources and managed through GitOps. The pattern stays consistent regardless of the tooling you use: a custom resource specifies the tenant cluster’s location, storage backend, and security policies, and a controller handles the reconciliation.
The key constraints that need to be defined in that resource include:
- A node selector or topology constraint that ensures all pods in the tenant cluster are assigned to nodes tagged with the correct jurisdiction. This should be enforced as a hard requirement at the tenant control plane level, not left to voluntary compliance.
- A storage backend for the tenant cluster’s own state (whether etcd or a SQL equivalent) that resides within the chosen jurisdiction. The control plane’s data, API objects, and secrets must not pass through a managed service outside that jurisdiction.
- Audit log destinations located within the jurisdiction, ensuring the tenant cluster’s audit trail never crosses the boundary that regulators care about.
- A policy engine (such as Kyverno or OPA Gatekeeper) deployed inside the tenant cluster to enforce residency rules, image provenance, and SBOM requirements from within.
A UK tenant cluster follows the same structure but uses different labels, a separate storage backend, and a distinct audit destination. Adding a new jurisdiction is as simple as submitting a pull request, not building an entirely new cluster.
The entire configuration is stored in Git. The audit trail explaining why tenant X’s data resides in jurisdiction Y is captured in commit history, not in a screenshot of a management console.
Limiting the impact of a sovereignty breach
Discussions about sovereignty usually center on data residency. The more challenging question is what happens when something goes wrong, such as a legal subpoena, a misconfigured controller, or a leaked credential.
Tenant clusters help contain the damage in specific, practical ways.
A CLOUD Act-style request directed at the operator of the underlying cluster doesn’t automatically expose a tenant cluster’s etcd data if that storage is managed by a local operator within the jurisdiction. The legal target and the technical target are intentionally separated by design.
A compromised admission webhook in the EU tenant cluster can’t affect the UK tenant cluster, since they don’t share a control plane. The webhook operates entirely within one tenant cluster’s API server.
A platform-wide CRD upgrade can be rolled out gradually, one tenant cluster at a time. You might run Kubernetes 1.34 in one jurisdiction and 1.33 in another while a regulator completes its review of a CVE. Running different versions becomes a deliberate advantage, not a complication.
These benefits aren’t accidental. They come from giving each sovereignty boundary its own dedicated control plane, and they’re extremely difficult to add after the fact to a single shared cluster.
Bare metal, AI clouds, and the road ahead
The same pattern extends further down the stack. If the requirement is hardware-level sovereignty rather than just operator-level control, the underlying cluster itself can run on bare metal provisioned with Metal3 and Ironic (or higher-level tools like Tinkerbell) or layers like vMetal. Tenant clusters then inherit that hardware boundary automatically. No part of the stack runs on infrastructure outside the chosen jurisdiction. The Sovereign AI Cloud on Bare Metal GPUs guide provides a detailed walkthrough of what this looks like end to end for GPU-intensive deployments.
This is particularly relevant for the growing AI cloud market. GPU-heavy workloads have been the strongest argument for depending on hyperscalers, and they’re also the workloads most affected by the EU AI Act’s Article 12 logging and governance requirements.
A design that places GPU-equipped base clusters on dedicated, sovereign hardware, with per-customer or per-tenant virtual clusters that receive GPU resources through Dynamic Resource Allocation, offers AI platform teams a concrete response to two critical questions: “Where does training actually execute?” and “Which authority can legally compel access to the model weights?”
This is not a theoretical exercise. Polarise, a German sovereign AI cloud provider, is a real-world operator running this exact architecture in production: pooled GPU resources at the foundation, a dedicated tenant cluster for each customer layered above, all governed by EU law. The specific operator may differ, but the underlying pattern remains consistent.
What this approach does not address
It is important to be transparent about the limitations.
The tenant cluster model does not alter the legal jurisdiction of the entity operating the base cluster. If a US-headquartered company manages the underlying Kubernetes infrastructure, that entity’s exposure under the CLOUD Act persists. The pattern narrows and segments that exposure — it does not eliminate it. For workloads where the operator’s own jurisdiction is the core risk, you still need a sovereign operator running on sovereign hardware, with the tenant cluster pattern layered on top.
This pattern also does not substitute for the rest of the CNCF sovereign technology stack. You still require a policy engine such as Kyverno or OPA Gatekeeper, an SBOM pipeline (the Cyber Resilience Act will not wait for you), an audit logging pipeline, a workload identity layer like SPIFFE/SPIRE, and a GitOps controller. Tenant clusters are a foundational building block, not a complete platform. Frameworks like DORA and SecNumCloud 3.2 make this explicit: the tenant-cluster boundary is one input among many for operational resilience and sovereignty controls, not the entire solution.
Ref: vCluster DORA Infographic
And per-tenant clusters carry a real operational cost. Each one is a genuine control plane that must be monitored, upgraded, and backed up. The benefit only justifies the overhead when the boundary you are establishing carries meaningful legal or risk significance. A dedicated tenant cluster for every customer is excessive for a free-tier offering. A tenant cluster per jurisdiction, with a handful of regulated customers within each, is precisely the scenario this pattern is designed for.
The architecture of a sovereign platform in 2026
Bringing all of this together, the platforms that are passing 2026 audits tend to follow a broadly consistent shape:
A small number of underlying Kubernetes clusters, deployed on sovereign infrastructure wherever the threat model demands it. Tenant clusters organized per jurisdiction, per regulated workload, or per regulated customer — each with its own dedicated control plane, declared in Git, and deployed via Argo CD or Flux. Policy enforced by Kyverno or Gatekeeper at both the underlying cluster level and within each individual tenant cluster. Audit logs streamed to jurisdiction-local destinations, never crossing the boundary that the regulator cares about. Workloads written against standard Kubernetes APIs, portable across different underlying clusters as procurement strategies, geopolitical conditions, and hardware availability evolve.
In this model, sovereignty is not merely a line in a procurement contract. It is a defined object within the cluster — with a name, a template, and a commit history. That is the form regulators are beginning to expect, and it is the form that platform teams can realistically operate.