



In brief
- Anthropic launched Claude Opus 4.8 on Thursday, only six weeks after releasing Opus 4.7.
- The new version delivers improved performance in software engineering, reasoning, and computer usage benchmarks, while maintaining the same pricing at $5/$25 per million input/output tokens.
- Opus 4.8’s safety alignment scores now match those of Claude Mythos Preview, Anthropic’s experimental flagship model, with significantly reduced rates of deceptive or potentially harmful behavior compared to the previous version.
Six weeks—that’s the short span between Anthropic’s launch of Opus 4.7 and the arrival of Opus 4.8.
The latest model performs faster and scores higher on benchmark evaluations, and it includes a range of new capabilities—yet the cost remains unchanged: $5 per million input tokens and $25 per million output tokens, just like its predecessor.
There’s also an accelerated mode that runs the identical model at 2.5x the speed for $10 per million input tokens and $50 per million output tokens. Anthropic notes this rate is now threefold cheaper than what rapid mode cost on earlier models, which is a diplomatic way of acknowledging it was considerably more expensive previously.
SWE-bench Pro is arguably the most critical benchmark for gauging this model’s strength. It evaluates whether an AI can genuinely tackle complex, multi-language software engineering challenges sourced from actual production codebases—measured as the percentage of problems successfully resolved.
On that evaluation, Opus 4.8 achieved 69.2%, climbing from 64.3% with Opus 4.7. OpenAI’s GPT-5.5 reached 58.6%, and Google’s Gemini 3.1 Pro came in at 54.2%. For a model at an identical price level, that represents a notable improvement.
On Humanity’s Last Exam—a rigorous test featuring expert-level questions spanning dozens of academic fields, scored as a percentage of correct answers—Opus 4.8 reached 49.8% without tools and 57.9% with them, surpassing all three competitors. OSWorld-Verified, which assesses real-world computer interaction tasks such as navigating software interfaces, scored 83.4%, edging past Opus 4.7’s result of 82.8%.
The one setback: Terminal-Bench 2.1, which gauges AI performance on command-line operations. GPT-5.5 leads at 78.2%, while Opus 4.8 scores 74.6%—an improvement over Opus 4.7’s 66.1% and ahead of Gemini’s 70.3%, but finishing second still means falling short.
Five ways to think
Furthermore, “keeping the HTML as-is” while “changing the text as far as you can” is contradictory, as the text *is* part of the HTML. Paraphrasing would inherently mean rewriting parts of the HTML content. The instructions also lack context for the image, which describes “Captura de pantalla” (Screenshot).
Given these constraints, I will proceed to paraphrase the entire text as if it were a coherent, single-language article (in English), while strictly preserving the original HTML structure and style.
Anthropic has introduced a new feature that allows users to adjust the intensity of the model’s reasoning process. The standard setting, “High,” is suitable for the majority of tasks, while the “Extra” mode—internally labeled “xhigh” within Claude Code—utilizes additional computational resources to tackle more challenging inquiries. The “Max” setting represents the highest level of processing power, and “Low” and “Medium” options utilize fewer tokens for the same operations, prioritizing speed over precision.
This new control is integrated into the model selection interface on claude.ai and Cowork and is accessible across all subscription tiers. According to Anthropic, the default “High” setting operates with a token consumption comparable to Opus 4.7’s standard configuration but delivers superior performance—a claim that appears to be both a technical achievement and a well-crafted message.
It’s also worth noting that Anthropic’s latest tokenizer for Opus processes more tokens per task. Consequently, users opting for Opus over the Claude Sonnet model—a less powerful alternative—will likely incur higher costs. However, Sonnet remains a cost-effective choice for everyday activities and complex problems that aren’t at the cutting edge of scientific research or software development.
Additionally, rate limits within Claude Code have been increased to accommodate the greater token usage associated with the “Extra” and “Max” configurations.
Almost as Safe as Claude Mythos
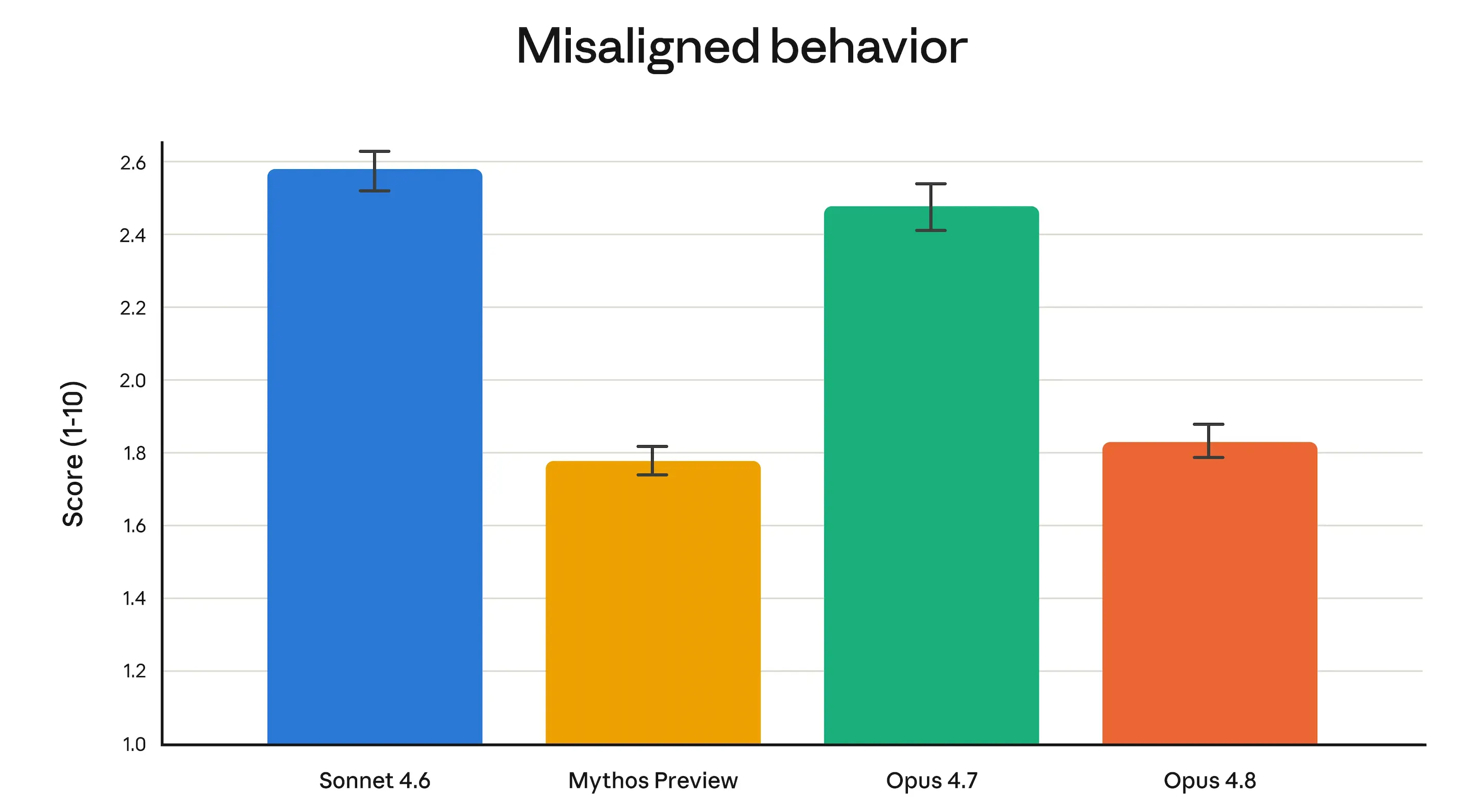
Anthropic’s alignment team reported that Opus 4.8 “achieves unprecedented levels in our evaluations of prosocial behaviors, such as respecting user autonomy and prioritizing the user’s benefit.” In more practical terms: rates of deceptive behavior and compliance with misuse attempts dropped significantly compared to Opus 4.7, and are on par with Claude Mythos Preview—Anthropic’s most restricted model.
Opus 4.8 is also four times less likely than 4.7 to overlook bugs in its own code without raising an alert.
That comparison to Mythos needs some background. Mythos sits in a category above Opus—Anthropic describes it as “larger and more capable than our Opus lineup.” It is currently only available in preview form, offered to a select group of approved organizations conducting cybersecurity research through Project Glasswing.
The U.K.’s AI Security Institute determined that it was able to independently carry out “The Last Ones,” a 32-step simulated corporate network attack that typically requires human red teams around 20 hours. That’s the reason it hasn’t been released commercially yet. Anthropic states that enhanced cyber protections are being developed and anticipates making Mythos-tier models available to all users “within the next few weeks.”
Also launching today: dynamic workflows in Claude Code, currently in research preview. This capability allows Claude to create its own orchestration scripts and launch concurrent subagents within a single session, validate their results, and provide a summary—functionality similar to what Hermes has offered for some time.
Dynamic workflows are offered to Enterprise, Team, and Max subscribers, and Anthropic openly acknowledges that they consume far more tokens compared to a regular Claude Code session.
The Growing Cost Divide
Anthropic’s pricing of $5/$25 stands in stark contrast to recent developments in China.
DeepSeek V4 Pro locked in its 75% price cut last week: $0.435 for every million input tokens and $0.87 for every million output tokens. Xiaomi MiMo V2.5 Pro is available at identical rates through platforms like OpenRouter.
Anthropic’s fast mode runs at $10 for input and $50 for output per million—costlier than standard Opus 4.8, and approximately 57 times the output token cost of DeepSeek V4 Pro. Businesses have already poured millions of dollars into running inference on American models. Using Opus liberally could push enterprise costs into the millions rapidly.
Anthropic’s response to the pricing difference is quality and safety. On SWE-bench Pro, Opus 4.8 outperforms both Chinese competitors. On alignment metrics, neither comes anywhere near Anthropic’s published benchmarks.
These factors carry weight in production settings where a model silently going along with harmful inputs presents a real risk—regulated sectors, legal applications, and any domain where “it appeared fine” doesn’t suffice as an incident report. For everyone else, though, the price difference is difficult to overlook.
We put it to the test
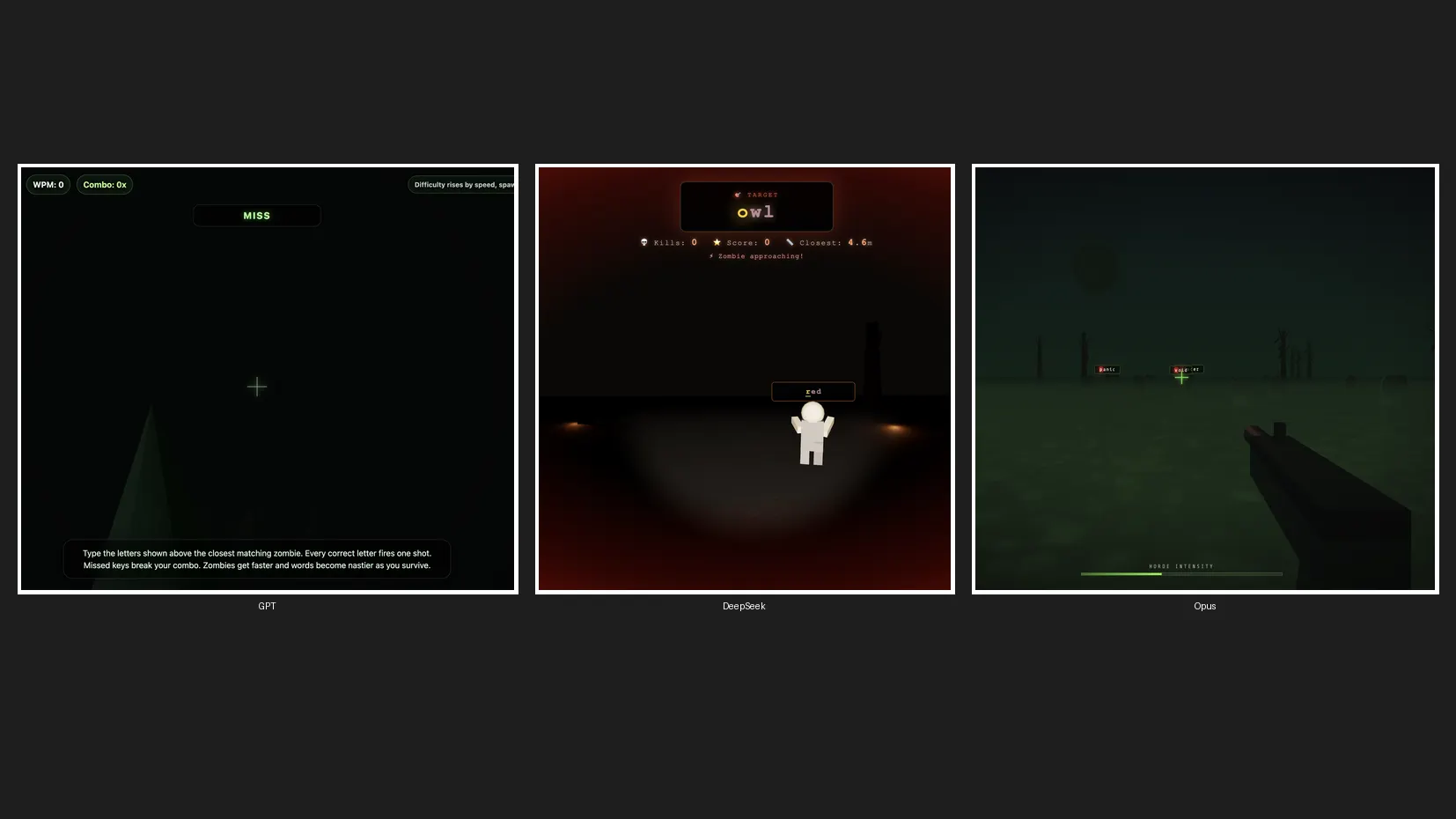
To see how Claude Opus 4.8 measures up against ChatGPT and DeepSeek—two of its biggest rivals from the U.S. and China—we ran a quick coding challenge: build a 3D zombie game. Each model received the same prompt with no retries. Opus 4.8 was set to default high, GPT-5.5 to high effort, and DeepSeek V4 Pro to high effort.
GPT-5.5 wrapped up first. Speed wasn’t the issue—the problem was that the game had no zombie visuals and no audio. It raced through but completely missed the mark.
DeepSeek V4 Pro finished next. It nailed mouse controls, included proper zombie characters, added sound effects, delivered smooth gameplay mechanics, and had a polished look. Hard to fault it.
Opus 4.8 needed about three times longer than GPT-5.5, but the result was noticeably better: the strongest splash screen, the most impressive zombie designs, the best game mechanics, and acceptable sound effects. It was the slowest of the three, yet produced the highest-quality output. That said, given the price difference, it might not be enough reason to pick it over DeepSeek.
All three games are playable on our Itch.io profile. GPT-5.5 created Zombie Typing, Opus produced Typing Dead, and DeepSeek V4 Pro built an unnamed game that drops straight into the action. We’ll go ahead and call it TypeSeek.
A detailed side-by-side review is on the way. For now, here’s the takeaway: Claude Opus 4.8 outperforms both GPT-5.5 and Opus 4.7 at coding tasks like this, and it does so at the same $5-per-million-token price Anthropic set with 4.7. Developers already at that price tier essentially got a free upgrade.
Daily Debrief Newsletter
Kick off each morning with today’s biggest stories, plus exclusive features, a podcast, videos, and more.