



Running large-scale transformer models for training or inference is essentially a challenge of managing available GPU memory. Each GPU in a cluster has a fixed VRAM capacity, and as both model sizes and context windows continue to expand, engineers are forced to carefully balance how computational workloads are distributed across hardware. A novel approach proposed by Zyphra, known as Tensor and Sequence Parallelism (TSP), provides a fresh perspective on these trade-offs — and in benchmarks scaling up to 1,024 AMD MI300X GPUs, it consistently achieves lower peak memory usage per GPU compared to any conventional parallelism strategy, for both training and inference scenarios.
The Challenge That TSP Addresses
To appreciate why TSP matters, it helps to first understand the two parallelism strategies it merges.
Tensor Parallelism (TP) divides model weights among multiple GPUs. Within an attention or MLP layer, each GPU in the TP group stores just a portion of the weight matrix. This directly cuts down the memory each GPU uses for parameters, gradients, and optimizer states — collectively known as the ‘model state’ memory. The downside is that TP demands collective communication steps (typically all-reduce or reduce-scatter/all-gather pairs) every time a layer is processed. This communication overhead scales with activation size, making it increasingly costly as sequence lengths increase.

Sequence Parallelism (SP) follows a different path. Rather than partitioning weights, it distributes the input token sequence across GPUs. Each GPU handles only a subset of tokens, which lowers activation memory and the quadratic complexity of attention computation. The catch, however, is that SP keeps full copies of model weights on every GPU, so model-state memory does not benefit from spreading the workload across more GPUs.
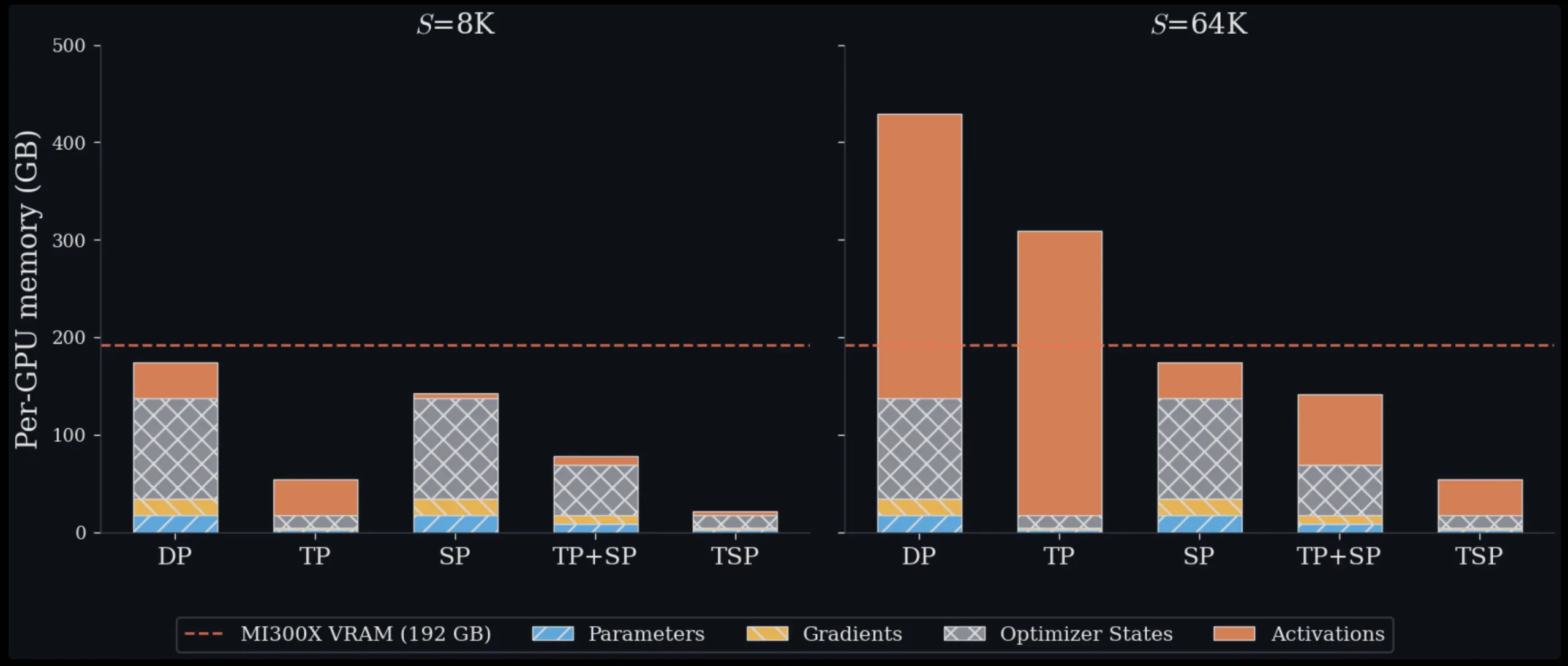
In typical multi-dimensional parallelism setups, engineers combine TP and SP by assigning them to separate, orthogonal axes of a device mesh. Achieving a TP degree of T and an SP degree of Σ means the model replica consumes T·Σ GPUs. This approach carries two significant costs. First, it dedicates more GPUs to the model-parallel group, reducing the number available for data-parallel replicas. Second, if T·Σ is large enough to extend beyond a single node, some collective communication must traverse slower inter-node interconnects like InfiniBand or Ethernet rather than the high-bandwidth intra-node fabric, such as AMD Infinity Fabric or NVIDIA NVLink. Data Parallelism (DP), another widely used alternative, sidesteps these model-parallel overheads entirely but replicates the entire model state on every device, rendering it impractical for large models or long context windows on its own.
What Parallelism Folding Really Involves
The central innovation of TSP is parallelism folding: instead of assigning TP and SP to independent, orthogonal mesh dimensions, it collapses both onto a single device-mesh axis of size D. Every GPU in the TSP group simultaneously holds 1/D of the model weights and 1/D of the token sequence. Because both weight sharding and sequence sharding are spread across the same D GPUs, the per-device memory footprint shrinks by a factor of 1/D for both parameter memory and activation memory — an outcome that no single conventional parallelism technique can achieve by itself. TSP stands as the only approach that simultaneously reduces weight-dependent memory (parameters, gradients, optimizer states) and activation memory by the same 1/D ratio along a single axis.
without the need for a two-dimensional T.Σ device layout.
The core difficulty is that when each GPU holds only a portion of the model weights and a portion of the input sequence, it must cooperate with other GPUs to complete each layer’s forward computation. TSP addresses this by using two distinct communication strategies—one tailored for the attention mechanism and another for the gated MLP layer.
For attention, the system cycles through weight partitions one step at a time. At each step, one GPU broadcasts its grouped attention weight shards—namely WQ, WK, WV, and WO—to every other GPU within its group. Each GPU then uses those weights to process its own local batch of tokens, computing local projections for Q, K, and V. Because causal attention requires the full sequence of keys and values, the local K and V tensors are collected from all GPUs in the TSP group using an all-gather operation, then rearranged with a zigzag partitioning scheme before FlashAttention is executed. The zigzag arrangement balances computational load across GPUs: without it, later tokens—which attend to longer preceding context—would naturally create uneven workloads.
For the gated MLP component, TSP employs a circulating ring-based schedule. Each GPU begins with local portions of the gate, up-projection, and down-projection weights. These weight shards are passed sequentially between GPUs using point-to-point send and receive operations. As each shard arrives, every GPU accumulates partial results locally. A critical benefit of this approach is the removal of the all-reduce step that standard tensor parallelism normally requires after the MLP output—here, the sequence data remains on its originating GPU, and only the weight data travels across devices. Furthermore, the ring is structured to overlap weight transfers with GEMM calculations, meaning communication proceeds in the background while the GPU is actively computing.
Memory and Throughput Results
Evaluations on a single 8-GPU MI300X node across sequence lengths ranging from 16K to 128K tokens show TSP consistently requiring the least peak memory at every tested workload. With 16K tokens, TSP and TP perform similarly—31.0 GB versus 31.5 GB per GPU—because model parameter memory dominates at shorter sequence lengths. At 128K tokens, the contrast is stark: TSP uses 38.8 GB per GPU, whereas TP demands 70.0 GB, and two alternative TP+SP decomposition strategies consume 85.0 GB and 140.0 GB respectively on the same hardware. All theoretical estimates in this study are drawn from a reference 7 billion parameter dense decoder-only transformer (hidden dimension h=4096, 32 layers, 32 query heads, 32 KV heads, FFN expansion factor F=4, bf16 precision), offering a consistent framework for head-to-head comparison.
Across 128 full nodes totaling 1,024 MI300X GPUs, TSP sustains higher throughput than matched TP+SP baselines in every test. With parallelism degree D=8 and input sequences of 128K tokens, TSP reaches 173 million tokens per second—roughly 2.6 times faster than the TP+SP baseline at 66.30 million tokens per second. The performance gap widens as parallelism degree increases and sequences grow longer.

Practical Trade-offs to Understand
TSP does involve greater total data movement compared to tensor parallelism on its own. It introduces an additional weight-transfer cost per layer on top of the same K/V all-gather proportional to the activation size used in sequence parallelism. However, the researchers demonstrate that whenever the batch size B multiplied by sequence length S exceeds 8h (with h representing the model’s hidden embedding dimension), TSP’s per-forward-pass communication volume remains on par with standard tensor parallelism’s. This threshold is comfortably met in the majority of long-context training and inference workloads.
The essential point stressed by the Zyphra team is that total bytes communicated and actual time spent communicating are fundamentally different metrics. Whether additional data movement results in slower real-world performance hinges on whether the collective operations are limited by network latency or bandwidth, and to what extent those transfers can be hidden behind matrix multiplication work. Their implementation stages weight transfers behind the heaviest GEMM operations so that the additional communication saturates available bandwidth rather than lengthening the critical execution path.
TSP is not designed
You are a paraphrasing software that takes an article in HTML format and rewrite it in a way that is easy to read and understand, Keep HTML as-is, change the text as far as you can. Do not change the content language: to serve as a replacement for TP, SP, or TP+SP across all configurations. It functions as an added dimension within the multi-dimensional parallelism framework. It integrates seamlessly with pipeline, expert, and data parallelism. This allows teams to incorporate TSP into existing setups where standard configurations would normally require model-parallel groups over slower inter-node connections.
Key Takeaways
- Zyphra’s Tensor and Sequence Parallelism (TSP) maps tensor parallelism and sequence parallelism onto a single hardware axis, meaning every GPU manages 1/D of the model weights and 1/D of the token sequence concurrently, lowering memory use for both training and inference.
- TSP stands as the only approach that cuts weight-based memory (parameters, gradients, optimizer states) and activation memory by an identical 1/D factor along one axis, eliminating the need for a two-dimensional T.Σ device mesh.
- Tests conducted on one 8-GPU MI300X node reveal TSP requires 38.8 GB per GPU at a 128K sequence length, versus 70.0 GB for TP and 85.0–140.0 GB for TP+SP setups.
- When scaled to 1,024 MI300X GPUs, 128K context, and D=8, TSP delivers 173 million tokens each second compared to 66.30 million tokens each second with a comparable TP+SP baseline (representing roughly a 2.6x speed improvement).
- TSP works alongside pipeline, expert, and data parallelism, fitting best for memory-intensive, long-context training and inference tasks, where cutting down duplication of weights and activations matters more than the increased communication involved.
Have a look at the Paper and Technical details. Additionally, feel free to follow us on Twitter, and remember to become part of our 130k+ ML SubReddit and subscribe to our Newsletter. Hold on! Are you on Telegram? Now you can join us on Telegram as well.
Interested in partnering with us to highlight your GitHub Repo, Hugging Face Page, Product Launch, or Webinar? Connect with us