



StepFun, an AI research firm based in Shanghai, has launched StepAudio 2.5 Realtime — an end-to-end, real-time speech large language model that lets users fully customize personas.
Unlike traditional pipeline systems that handle speech recognition, reasoning, and voice synthesis as separate sequential steps, StepAudio 2.5 Realtime processes everything in a unified manner within a single framework. You feed audio in, and audio comes out — no intermediate modules. The model supports both Chinese and English.
It’s accessible through a WebSocket API at wss://api.stepfun.com/v1/realtime, using the model identifier step-2.5-realtime.
The Three Core Innovations
The StepFun research team highlights three foundational architectural breakthroughs powering the model:
1. Persona Data Augmentation at Million-Sample Scale
The team began with more than 10,000 carefully written, high-quality personas and used algorithmic techniques to expand this foundation into a persona feature matrix containing millions of distinct profiles. This expanded dataset was then paired with millions of actual conversational samples during training. The goal is broad generalization — specifically, ensuring the model remains consistent and reliable even when handling challenging, niche, or uncommon conversational scenarios. Rather than manually crafting millions of persona examples, StepFun’s researchers algorithmically grew the dataset from a well-curated set of seed profiles.
2. Tailored RLHF Alignment for Roleplay Stability
One of the most common issues in conversational AI is “out-of-character” (OOC) drift — where the model gradually loses consistency with its assigned persona during a conversation. StepFun’s team carried out dedicated RLHF (Reinforcement Learning from Human Feedback) optimization focused specifically on maintaining persona fidelity during roleplay exchanges. RLHF is a training methodology where human preference data is used to construct a reward model that, in turn, steers the language model’s outputs. Applying this technique with a targeted emphasis on roleplay consistency is a deliberate and focused design decision.
3. Integrated Speech Understanding and Generation
StepAudio 2.5 Realtime builds on the text-to-speech capabilities of StepAudio 2.5 and tightly integrates speech understanding with speech generation through reinforcement learning. This integration enables what StepFun refers to as “global scene-level tonal setting” alongside “intra-sentence detail sculpting.” In practice, the model can establish an overall emotional tone for an entire response while simultaneously fine-tuning subtle acoustic nuances within individual sentences.
Paralinguistic Perception
A particularly notable technical strength of this model lies in its paralinguistic perception. Paralinguistics covers the non-verbal acoustic cues embedded in speech — elements such as vocal tone, speaking pace, pauses, sighs, and laughter. By interpreting these signals, the model can gauge the user’s emotional state and detect underlying intentions. For instance, it can recognize fatigue from a subdued tone or frustration from an accelerated speaking rate. Capturing these subtleties requires the model to work directly with raw audio features rather than relying solely on transcribed text.
On the paralinguistic comprehension benchmark, StepAudio 2.5 Realtime achieved a score of 82.18, demonstrating its ability to perceive vocal speed, emotional state, age, and other acoustic characteristics.
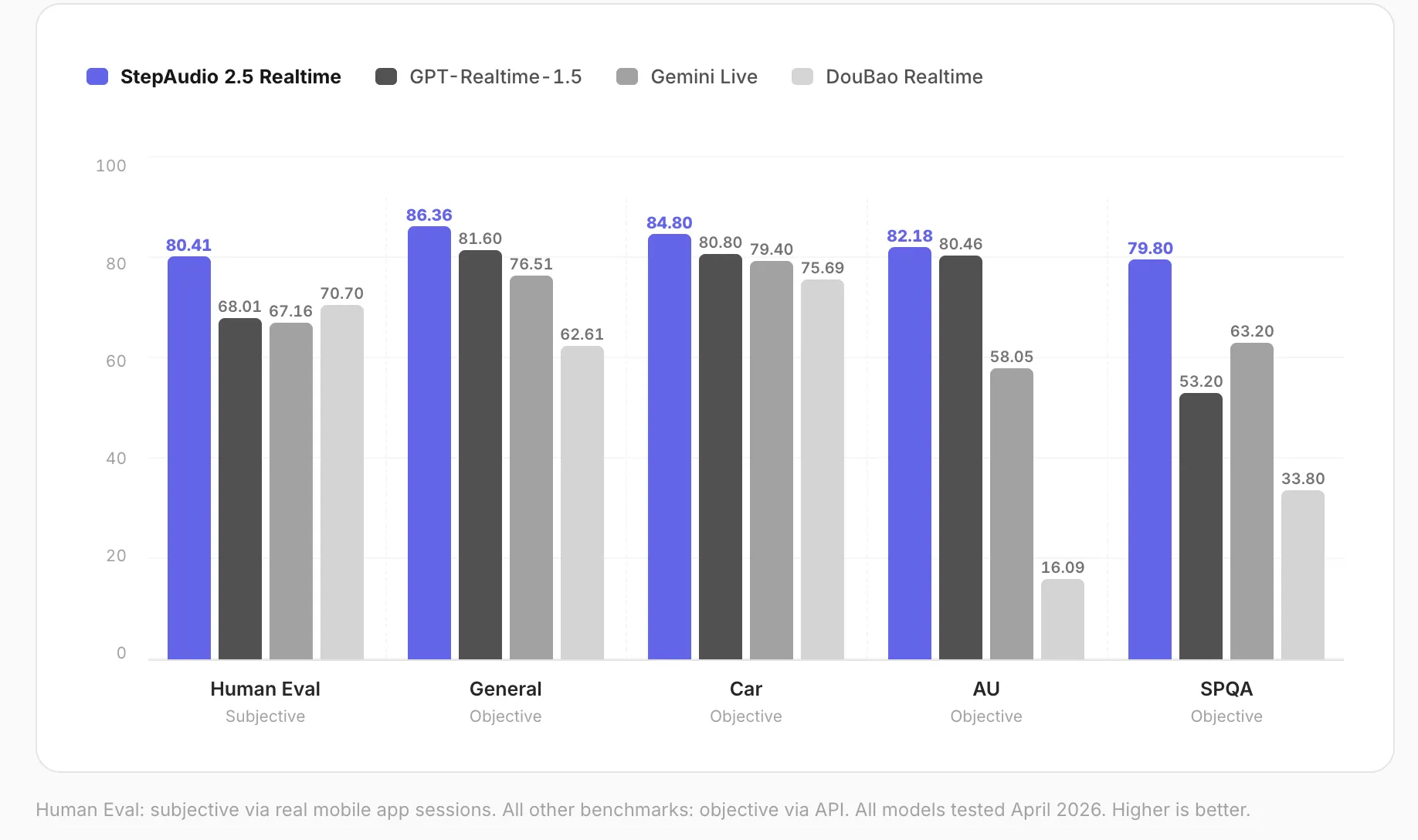
Benchmark Results
The StepFun research team carried out an extensive set of both subjective and objective evaluations, benchmarking StepAudio 2.5 Realtime against leading
Here is the paraphrased version of the article in HTML format:
Real-time voice models are assessed across five key performance areas.
Human evaluation is carried out using actual mobile app conversations that are rated by human evaluators. The results are as follows:
- Human evaluation (subjective): 80.41
- General dialogue (objective): 86.36
- Automotive scenario (objective): 84.80
- Spoken QA, spanning 11 audio understanding tasks (objective): 79.80
- Paralinguistic comprehension (objective): 82.18
Key Takeaways
- StepAudio 2.5 Realtime is a fully end-to-end real-time speech large language model, developed by Shanghai-based StepFun.
- It leverages persona-specific RLHF and data augmentation at the million-scale to ensure consistent character behavior.
- The model achieved the top ranking across all five benchmark dimensions, as tested in April 2026.
- Paralinguistic comprehension — the ability to detect tone, speaking rate, and emotion from audio — stands out as a key technical advantage.
- API access is available via WebSocket at
wss://api.stepfun.com/v1/realtimeusing the model identifierstep-2.5-realtime.
Be sure to check out the Model Card and Demo. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and subscribe to our Newsletter. Wait — are you on Telegram? Now you can join us on Telegram as well.
Looking to partner with us to promote your GitHub repo, Hugging Face page, product launch, webinar, or more? Get in touch with us

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.