



Retrieval is the place most RAG programs quietly break. Conventional pipelines depend on vector similarity—embedding queries and doc chunks into the identical area and fetching the “closest” matches. However similarity is a weak proxy for what we really want: relevance grounded in reasoning. In lengthy, skilled paperwork—like monetary stories, analysis papers, or authorized texts—the appropriate reply typically isn’t in probably the most semantically related paragraph. It requires navigating construction, understanding context, and performing multi-step reasoning throughout sections. That is precisely the place vector-based RAG begins to disintegrate.
PageIndex is designed to resolve this hole by rethinking retrieval from first ideas. As a substitute of chunking paperwork and looking out through embeddings, it builds a hierarchical table-of-contents-style tree index and makes use of LLMs to cause over that construction—very similar to a human professional scanning sections, drilling down, and connecting concepts. This permits a vectorless, reasoning-driven retrieval course of that’s extra interpretable, traceable, and aligned with how information is definitely extracted from complicated paperwork. By changing similarity search with structured exploration and tree-based reasoning, PageIndex delivers considerably larger retrieval accuracy—demonstrated by its robust efficiency on benchmarks like FinanceBench—making it significantly efficient for domains that demand precision and deep understanding.

On this article, we’ll use PageIndex to index the seminal Transformer paper — “Attention Is All You Need” — and run two cross-cutting queries towards it with no single vector or embedding. As a substitute of chunking the PDF and retrieving by similarity, PageIndex builds a hierarchical tree of the doc’s sections, then makes use of GPT-5.4 to cause over node summaries and establish precisely which sections include the reply — earlier than studying a single phrase of full textual content.

Establishing the dependencies
For this tutorial, you’d require PageIndex & OpenAI API keys. You may get the identical from and respectively.
pip set up pageindex openai requestsfrom pageindex import PageIndexClient
import pageindex.utils as utils
import os
from getpass import getpass
PAGEINDEX_API_KEY = getpass('Enter PageIndex API Key: ')
pi_client = PageIndexClient(api_key=PAGEINDEX_API_KEY)We import the OpenAI shopper and configure it with an API key to allow entry to LLMs. Then, we outline an asynchronous helper operate that sends prompts to the mannequin and returns the generated response.
import openai
OPENAI_API_KEY = getpass('Enter OpenAI API Key: ')
async def call_llm(immediate, mannequin="gpt-5.4", temperature=0):
shopper = openai.AsyncOpenAI(api_key=OPENAI_API_KEY)
response = await shopper.chat.completions.create(
mannequin=mannequin,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
return response.decisions[0].message.content material.strip()Constructing the PageIndex Tree
On this chunk, we obtain the Transformer paper straight from arXiv and submit it to PageIndex, which processes the PDF and builds a hierarchical tree of its sections — every node storing a title, a abstract, and the total part textual content. As soon as the tree is prepared, we print it out to examine the construction PageIndex has inferred: each chapter, subsection, and nested heading turns into a node within the tree, preserving the doc’s pure group precisely because the authors meant it.
# ─────────────────────────────────────────────
# Step 1: Construct the PageIndex Tree
# ─────────────────────────────────────────────
# 1.1 Obtain the Transformer paper and submit it
import os, requests
pdf_url = "
pdf_path = os.path.be a part of("data", pdf_url.break up("/")[-1])
os.makedirs("data", exist_ok=True)
print("Downloading 'Attention Is All You Need'...")
response = requests.get(pdf_url)
with open(pdf_path, "wb") as f:
f.write(response.content material)
print(f"✅ Saved to {pdf_path}")
doc_id = pi_client.submit_document(pdf_path)["doc_id"]
print(f"📄 Document submitted. doc_id: {doc_id}")
# 1.2 Retrieve the tree (ballot till prepared)
import time
print("nWaiting for PageIndex tree to be ready", finish="")
whereas not pi_client.is_retrieval_ready(doc_id):
print(".", finish="", flush=True)
time.sleep(5)
tree = pi_client.get_tree(doc_id, node_summary=True)["result"]
print("nn📂 Document Tree Structure:")
utils.print_tree(tree)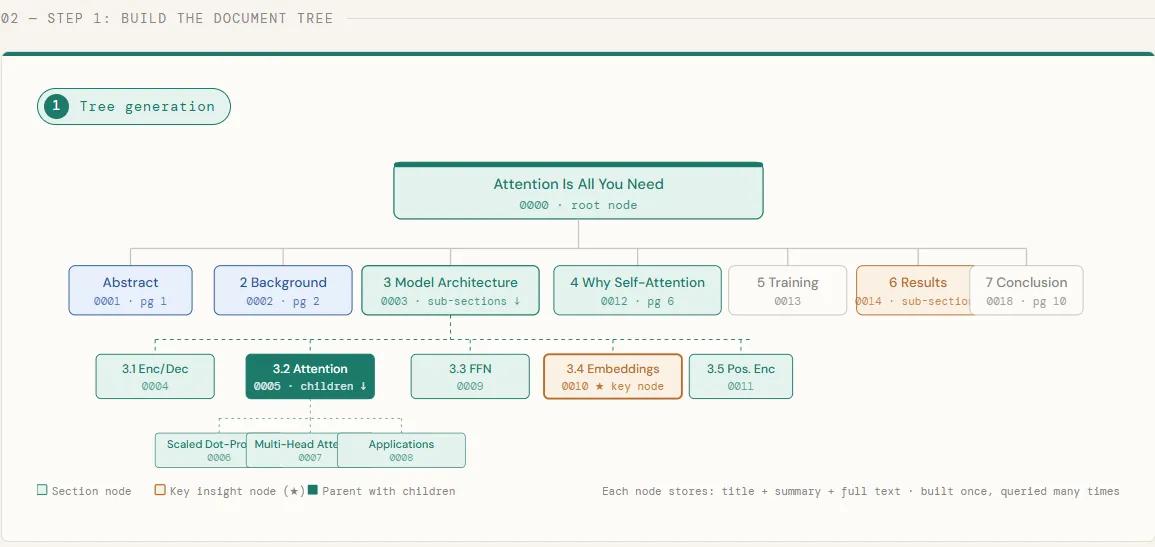
Reasoning-Primarily based Retrieval
With the tree constructed, we now run a question that’s deliberately cross-cutting — one that may’t be answered by a single part of the paper. We strip the total textual content from every node, leaving solely titles and summaries, and move your entire tree construction to GPT-5.4. The mannequin then causes over these summaries to establish each node more likely to include a related reply, returning each its step-by-step pondering and an inventory of matched node IDs. That is the core of what makes PageIndex totally different: the LLM decides the place to look earlier than any full textual content is loaded.
# ─────────────────────────────────────────────
# Step 2: Reasoning-Primarily based Retrieval
# ─────────────────────────────────────────────
# 2.1 Outline a question that requires navigating throughout sections
import json
# This question is deliberately cross-cutting -- it might't be answered
# by a single part, which is the place tree search shines over top-k.
question = "Why did the authors choose self-attention over recurrence, and what are the complexity trade-offs they compared?"
tree_without_text = utils.remove_fields(tree.copy(), fields=["text"])
search_prompt = f"""
You might be given a query and a hierarchical tree construction of a analysis paper.
Every node has a node_id, title, and a abstract of its content material.
Your activity: establish ALL nodes which are more likely to include info related to answering the query.
Consider carefully -- the reply could also be unfold throughout a number of sections.
Query: {question}
Doc tree:
{json.dumps(tree_without_text, indent=2)}
Reply ONLY on this JSON format, no preamble:
{{
"thinking": "",
"node_list": ["node_id_1", "node_id_2", ...]
}}
"""
print(f'🔍 Question: "{query}"n')
print("Running tree search with GPT-5.4...")
tree_search_result = await call_llm(search_prompt)
# 2.2 Examine the retrieval reasoning and matched nodes
node_map = utils.create_node_mapping(tree)
result_json = json.masses(tree_search_result)
print("n🧠 LLM Reasoning:")
utils.print_wrapped(result_json["thinking"])
print("n📌 Retrieved Nodes:")
for node_id in result_json["node_list"]:
node = node_map[node_id]
print(f" • [{node['node_id']}] Page {node['page_index']:>2} -- {node['title']}") 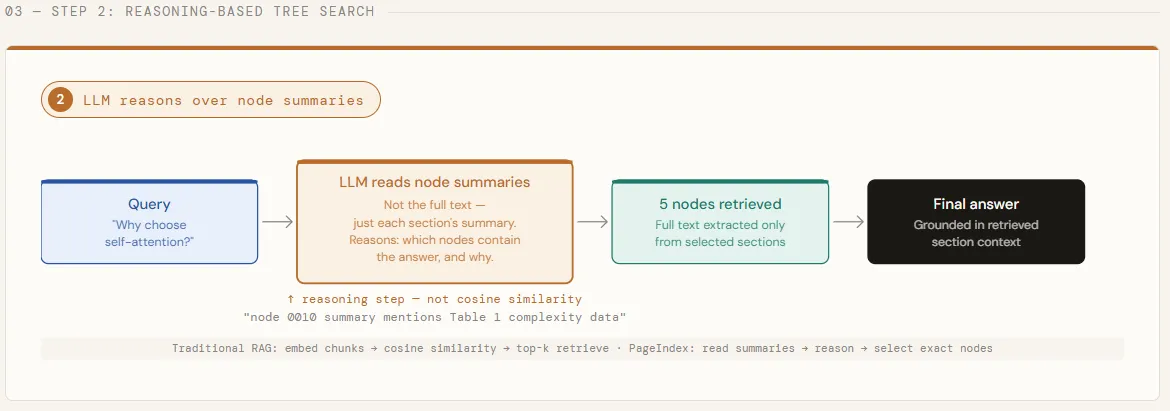
Reply Era
As soon as the related nodes are recognized, we pull their full textual content and sew it collectively right into a single context block — every part clearly labeled so the mannequin is aware of the place every bit of data comes from. That mixed context is then handed to GPT-5.4 with a structured immediate that asks for the core motivation, the precise complexity numbers, and any caveats the authors acknowledged. The mannequin solutions utilizing solely what was retrieved, grounding each declare straight within the paper’s textual content.
# ─────────────────────────────────────────────
# Step 3: Reply Era
# ─────────────────────────────────────────────
# 3.1 Sew collectively context from all retrieved nodes
node_list = result_json["node_list"]
relevant_content = "nn---nn".be a part of(
f"[Section: {node_map[nid]['title']}]n{node_map[nid]['text']}"
for nid in node_list
)
print(f"n📖 Retrieved Context Preview (first 1200 chars):n")
utils.print_wrapped(relevant_content[:1200] + "...n")
# 3.2 Generate a structured reply grounded within the retrieved sections
answer_prompt = f"""
You're a technical assistant. Reply the query beneath utilizing ONLY the offered context.
Be particular -- reference precise design decisions, numbers, and trade-offs talked about within the textual content.
Query: {question}
Context:
{relevant_content}
Construction your reply as:
1. The core motivation for selecting self-attention
2. The precise complexity comparisons made (embrace any tables or numbers)
3. Any caveats or limitations the authors acknowledged
"""
print("💬 Generating answer...n")
reply = await call_llm(answer_prompt)
print("─" * 60)
print("✅ Final Answer:n")
utils.print_wrapped(reply)
print("─" * 60)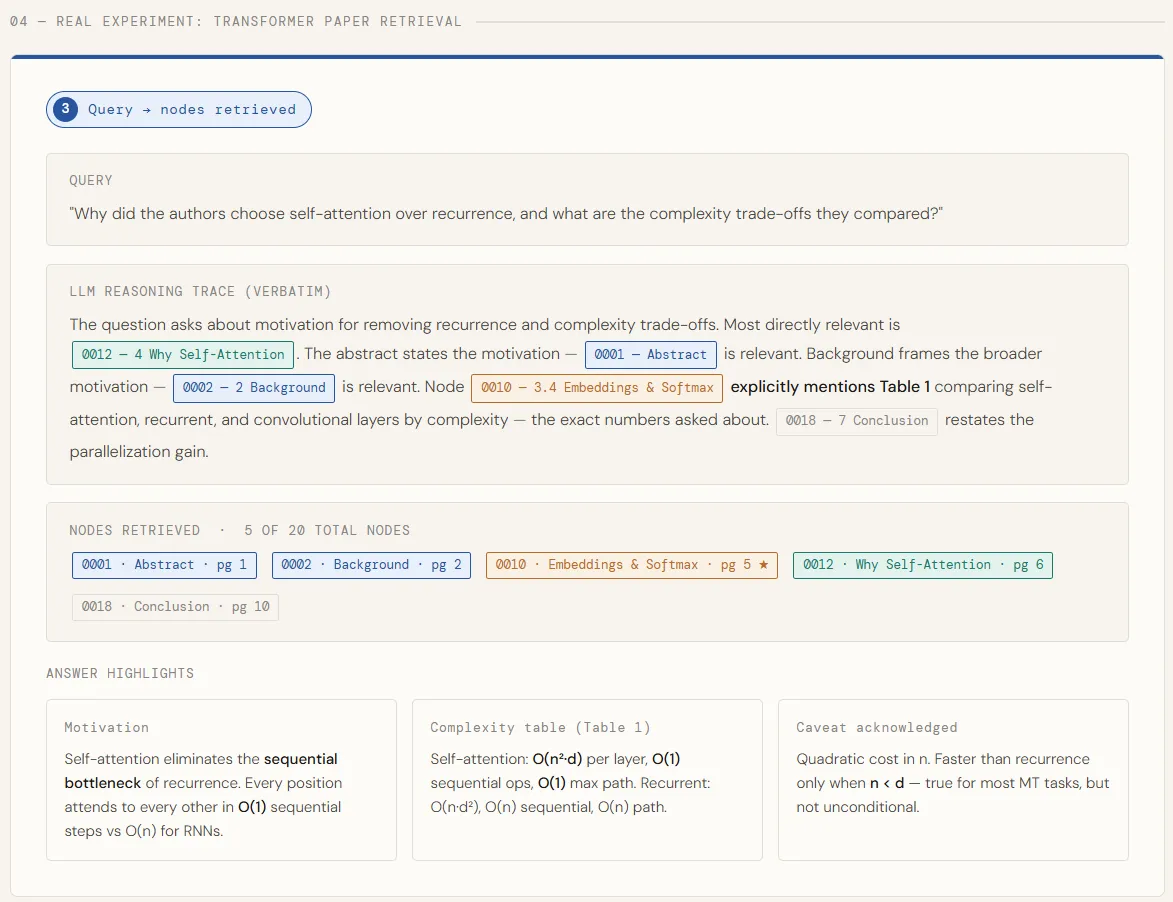

Testing with a Second Question
To indicate that the tree is constructed as soon as and reused at no additional value, we run a second question — this time focusing on a localized mechanism fairly than a cross-cutting design determination. The identical tree construction is handed to GPT-5.4, which narrows its search to simply the eye subsections, retrieves their full textual content, and generates a clear rationalization of how multi-head consideration works and why the scaling issue issues. No re-indexing, no re-embedding — only a new query towards the identical tree.
query2 = "How does the multi-head attention mechanism work, and what is the role of scaling in dot-product attention?"
search_prompt2 = f"""
You might be given a query and a hierarchical tree construction of a analysis paper.
Determine all nodes more likely to include the reply.
Query: {query2}
Doc tree:
{json.dumps(tree_without_text, indent=2)}
Reply ONLY on this JSON format:
{{
"thinking": "",
"node_list": ["node_id_1", ...]
}}
"""
print(f'nn🔍 Second Question: "{query2}"n')
result2_raw = await call_llm(search_prompt2)
result2 = json.masses(result2_raw)
print("🧠 Reasoning:")
utils.print_wrapped(result2["thinking"])
relevant_content2 = "nn---nn".be a part of(
f"[Section: {node_map[nid]['title']}]n{node_map[nid]['text']}"
for nid in result2["node_list"]
)
answer_prompt2 = f"""
Reply the next query utilizing ONLY the offered context.
Clarify the mechanism clearly, as if for a technical weblog put up.
Query: {query2}
Context: {relevant_content2}
"""
answer2 = await call_llm(answer_prompt2)
print("n✅ Answer:n")
utils.print_wrapped(answer2) 
Take a look at the Full Codes right here. Discover 100s of ML/Information Science Colab Notebooks right here. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 130k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as effectively.
Must accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so forth.? Join with us

I’m a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I’ve a eager curiosity in Information Science, particularly Neural Networks and their utility in numerous areas.