



Large language models are incredibly powerful, yet remain frustratingly opaque under the hood. When something goes wrong — a model suddenly switches languages, loops the same output repeatedly, or wrongly blocks a harmless request — developers have almost no visibility into what caused the issue at the computational level. Qwen-Scope was built precisely to solve this black-box problem.
The Qwen Team has just published Qwen-Scope, an open-source collection of sparse autoencoders (SAEs) trained across the Qwen3 and Qwen3.5 model families. The release includes 14 sets of SAE weights spanning 7 model variants — five dense models (Qwen3-1.7B, Qwen3-8B, Qwen3.5-2B, Qwen3.5-9B, and Qwen3.5-27B) and two mixture-of-experts (MoE) models (Qwen3-30B-A3B and Qwen3.5-35B-A3B).
What Exactly Is a Sparse Autoencoder, and Why Does It Matter?
Think of a sparse autoencoder as a decoder ring that translates raw neural network activations into human-readable concepts. As an LLM processes text, it generates high-dimensional hidden states — vectors packed with thousands of numbers — that are nearly impossible to interpret directly. An SAE learns to break these activations down into a large dictionary of sparse latent features, where only a small handful of features fire for any given input. Each of those features typically maps onto a specific, interpretable concept such as a particular language, a writing style, or a safety-related behavior.
In practice, for each backbone model and every transformer layer, Qwen-Scope trains a separate SAE to reconstruct residual-stream activations using only a sparse subset of latent features. The SAE encoder projects each activation into an overcomplete latent space, and a Top-k activation rule retains just the top k activations for reconstruction (with k set to either 50 or 100 in this release). For dense backbone models, the SAE width expands to 16× the model’s hidden size; for MoE backbones, standard SAEs use a 32K width (16× expansion), and wider SAEs up to 128K width (64× expansion) are also provided to capture more fine-grained representational detail.
The outcome is a complete layer-by-layer feature dictionary for every transformer layer across all seven backbone models. One important detail: Qwen3.5-27B is the only backbone whose SAEs were trained on the instruction-tuned variant; all other six backbones use their base model checkpoints.
Four Ways Qwen-Scope Transforms the Development Workflow
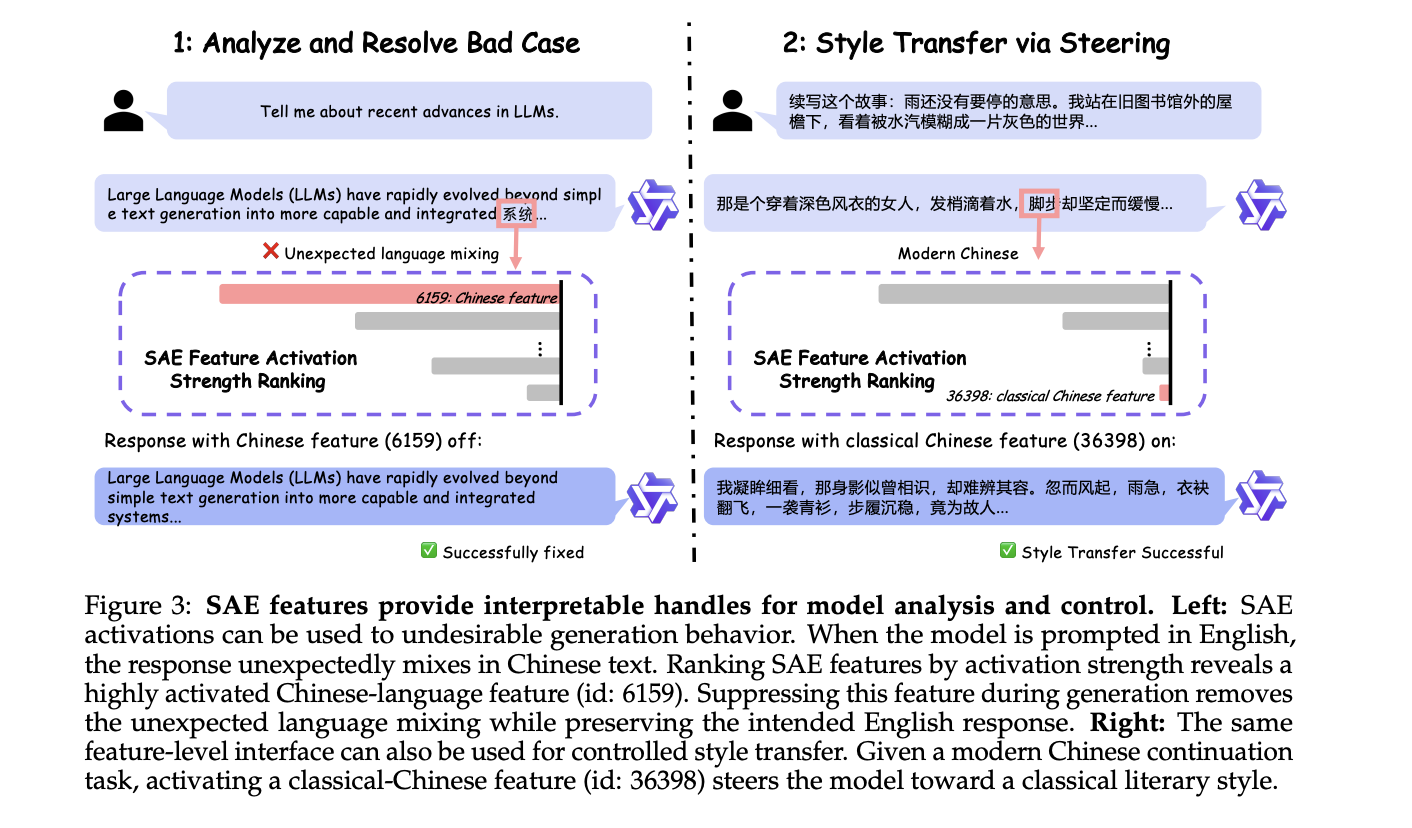
1. Steering Models at Inference Time
The most immediately useful application is steering — shaping model output without touching any model weights. The approach is grounded in a well-supported idea: high-level behaviors correspond to specific directions within the model’s internal representation space. By adding or subtracting a feature direction from the residual stream during inference using the formula h' ← h + αd, where h is the hidden state, d is the SAE feature direction, and α controls the intervention strength, developers can nudge the model toward or away from particular behaviors.
The research team illustrates this with two case studies on Qwen3 models. In the first, a model prompted in English unexpectedly injects Chinese text into its output. Ranking SAE features by activation strength uncovers a highly active Chinese-language feature (id: 6159). Suppressing that feature during generation eliminates the unwanted language mixing entirely. In the second case, activating a classical-Chinese feature (id: 36398) successfully steers a story-continuation task toward a classical literary style. Neither example required any weight updates at all.
2.
Evaluation Analysis Without Running Models
Assessing large language models usually involves executing numerous inference runs across extensive benchmark datasets — a process that demands significant computational resources and time. Qwen-Scope introduces a more efficient approach: leveraging Sparse Autoencoder (SAE) feature activations as a representation-level stand-in for benchmark evaluation.
The fundamental idea is straightforward: when a model processes a benchmark input, the SAE breaks down its internal activation into a sparse collection of active features, each representing a distinct ‘micro-capability.’ If all samples within a benchmark trigger the same features, that benchmark is redundant. Similarly, if two benchmarks activate largely the same feature sets, they are similar. The team introduces a feature redundancy metric that achieves a Spearman rank correlation of approximately 0.85 with traditional performance-based redundancy measurements across 17 popular benchmarks — including MMLU, GSM8K, MATH, EvalPlus, and GPQA-Diamond — all without conducting a single model evaluation. Their findings also show that 63% of the features activated by GSM8K are already captured by MATH, implying that evaluation suites including MATH can confidently drop GSM8K with little to no loss in diagnostic value.
The framework further extends to measuring similarity between benchmarks: the team quantifies feature overlap between benchmark pairs to assess whether they evaluate the same underlying capabilities. After accounting for general model proficiency by controlling for MMLU scores, the partial Pearson correlation between feature overlap and performance-based similarity across 28 benchmark pairs rises to 75.5%, indicating that feature overlap reflects benchmark-specific capability similarity rather than overall model quality. This carries a clear practical takeaway: benchmarks with minimal feature overlap assess different capabilities and should both be kept, while those with substantial overlap are strong candidates for merging.
3. Data-Centric Workflows: Toxicity Classification and Safety Data Synthesis
SAE features also serve as effective lightweight classifiers. The team constructs a multilingual toxicity classifier spanning 13 languages using a straightforward two-stage process: first, pinpoint SAE features that activate more often on toxic inputs than on clean ones (using a small discovery dataset), then apply a simple OR-rule over those features on unseen test data — no extra classifier head, no gradient-based training required. On English, this method delivers an F1 score exceeding 0.90 on both Qwen3-1.7B and Qwen3-8B. The team further demonstrates that features identified in English transfer effectively to other languages without needing to rediscover them — performance degrades with increasing linguistic distance (strongest transfer for European languages like Russian and French, weaker for Arabic, Chinese, and Amharic), and scaling up to Qwen3-8B enhances both the degree and consistency of cross-lingual transfer. Notably, using just 10% of the original discovery data still recovers roughly 99% of classification performance, highlighting exceptional data efficiency.
On the data generation front, the team presents a feature-driven safety data synthesis pipeline: detect safety-relevant SAE features that are underrepresented in existing training data, create prompt-completion pairs specifically designed to trigger those features, and confirm their presence in feature space. Under equal budget conditions, the feature-driven approach achieves 99.74% coverage of the target safety feature set, far surpassing the coverage obtained through natural sampling or random safety-oriented synthesis. Incorporating 4,000 feature-driven synthetic examples alongside 4,000 real safety examples yields a safety accuracy of 77.75 — rivaling the results of training on 120,000 safety-only examples.
4. Post-Training: Supervised Fine-Tuning and Reinforcement Learning
Perhaps the most technically innovative contribution involves using SAE features as active signals during training, rather than solely at inference time.
For supervised fine-tuning, the team tackles unintended code-switching — a phenomenon where multilingual LLMs unexpectedly generate tokens in a language different from the intended one. Their approach, named Sparse Autoencoder-guided Supervised Fine-Tuning (SASFT), first identifies language-specific features through a monolinguality scoring method, then applies an auxiliary regularization loss that dampens those feature activations during training on data from non-target languages. Across five models from three families — Gemma-2, Llama-3.1, and Qwen3 — and three target languages (Chinese, Russian, and Korean), SASFT reduces the code-switching ratio by over 50% in most experimental setups, with complete elimination in select cases (e.g., Qwen3-1.7B on Korean), all while preserving performance on six multilingual benchmarks.
For reinforcement learning, the team addresses endless repetition — a relatively rare but highly disruptive failure mode where models get stuck in loops of repeated content. Standard online RL seldom encounters repetitive rollouts during training, making it difficult for the model to learn a robust corrective signal. Qwen-Scope solves this by employing SAE feature steering to artificially produce one repetition-biased rollout per training group, which is then added as a rare negative example within the DAPO RL pipeline. The outcome: repetition rates drop sharply and consistently across Qwen3-1.7B, Qwen3-8B, and Qwen3-30B-A3B, while overall benchmark performance stays competitive with standard RL training.
Check out the Paper, Weights, and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and subscribe to our Newsletter. Wait! Are you on Telegram? Now you can join us on Telegram as well.
Need to partner with us for promoting your GitHub repo, Hugging Face page, product release, webinar, or more? Connect with us