



Most web agents today operate by performing one browser action at a time. The model takes in the current page state — whether as a screenshot or DOM text — and predicts the next click, keypress, or scroll. This step-by-step approach was reasonable when language models had limited reasoning power. But as models have grown more skilled at writing and debugging code, that rigid loop has turned from a helpful structure into a bottleneck.
Researchers at Microsoft’s AI Frontiers lab developed an alternative. Their new open-source framework, Webwright, gives the agent a terminal rather than a stateful browser session. The agent writes Playwright code to control browsers, executes bash commands, examines logs, and iteratively improves scripts. Playwright is an open-source browser automation library, also from Microsoft, that enables programmatic control of Chromium, Firefox, and WebKit browsers.
What Webwright Does Differently
Webwright decouples the agent from the browser and treats the browser as something the agent can launch, inspect, and discard while building a program. The lasting artifact is not the browser session but the code and logs stored in the local workspace.
This mirrors how a developer writes an RPA (Robotic Process Automation) script. Instead of manually clicking through a site each time, they write a script once. That script can be rerun, modified, and shared. Webwright brings this same approach to LLM-powered agents.
The system consists of three core components: a Runner, a Model Endpoint, and a terminal Environment. The runner is roughly 150 lines of code, the model interface about 550 lines, and the environment about 300 lines. There is no multi-agent orchestration or complex planning hierarchy — just a single agent loop.
All intermediate code, logs, screenshots, and results are saved in the workspace, making each run straightforward to inspect.
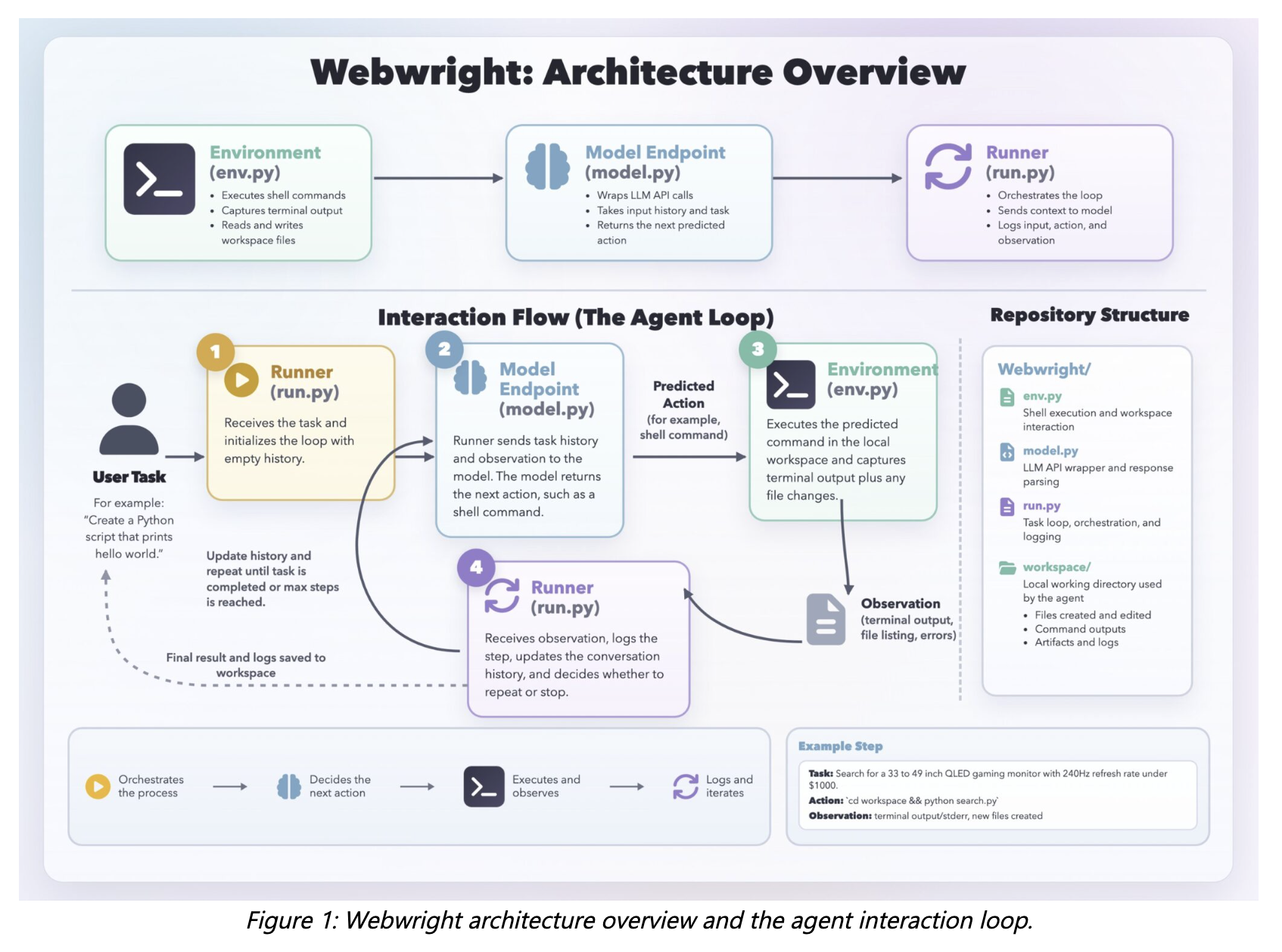
The Agent Loop
The Runner sends the current context to the model. The model responds with a thinking block and a shell command. That command executes in the Environment, which returns terminal output, logs, screenshots, or error tracebacks. These observations feed back into the context, and the loop repeats.
Instead of issuing one primitive action at a time, a coding agent can naturally express multi-step interactions — like picking a date or completing an entire form — as a compact program. Loops, functions, and abstractions let the agent generalize across similar tasks without repeatedly predicting the same sequences of low-level steps.
Two Engineering Challenges
Premature ‘done’ and context explosion are the two main issues. With open-ended bash actions, the model must self-report completion and often declares success without actually finishing. The team added a gate: the agent must generate a self-reflection config, run a final script in a fresh folder with logs and screenshots, and pass its own self-reflection judgment that outputs success or failure before emitting done: true. Otherwise, the flag is dropped and it retries.
For context length, long coding trajectories quickly exceed context limits, so they
Every 20 steps, the agent automatically compresses its history into a single summary, keeping the context window compact and reducing token usage.
Benchmark Results
Webwright was tested on two benchmarks: Online-Mind2Web and Odysseys.
Online-Mind2Web features 300 tasks spread across 136 popular websites and relies on an automated LLM-as-a-Judge evaluation setup. GPT-5.4 scored 86.67% overall accuracy — the highest result among all open-source harness recipes in the AutoEval category of the Online-Mind2Web benchmark using a 100-step limit. Claude Opus 4.7 achieved 84.7% overall but edged ahead on difficult tasks at N=100 steps, reaching 80.5% compared to GPT-5.4’s 76.6%.
The team also recreated a GPT-5.4 baseline using a traditional screenshot-based agent approach, where the model guesses x,y coordinates for click and typing actions. With the identical underlying model, Webwright delivers major improvements across all three difficulty levels, demonstrating the advantage of a code-driven terminal-based method over predicting coordinates one step at a time.
Odysseys assesses long-horizon browsing tasks that span multiple websites, with instructions averaging 272.3 words. On the April 2026 leaderboard, the top-performing model was Opus 4.6 with a peak score of 44.5. Webwright powered by GPT-5.4 hits 60.1% — a 35.1% relative gain over the prior state of the art. Against the base GPT-5.4 score of 33.5%, this represents a 79.4% relative boost, or 26.6 absolute points.
Cost Analysis
Claude Opus 4.7 requires fewer steps per task on average (mean 21.9) than GPT-5.4 (mean 26.3). However, its pricing is considerably higher ($5 versus $2.50 per 1M input tokens, and $25 versus $15.00 per 1M output tokens as of April 2026), making the average cost per task greater ($6.09 versus $2.37). The first 50 steps already capture 82% accuracy, while the next 50 steps add just 3–4 more points.
Small Model Performance
The researchers also evaluated Qwen3.5-9B on the hard subset of Online-Mind2Web. When tasks were enhanced with pre-built reusable tool scripts, Qwen3.5-9B reached 66.2% on Online-Mind2Web sites that offered more than five tools. This indicates that smaller, more affordable models can tackle complex web tasks effectively when supported by a pre-built tool library.
Marktechpost’s Visual Explainer
Webwright
Quick Start Guide
What Is Webwright?
Webwright is an open-source, terminal-native web agent framework built by Microsoft Research. Rather than guessing one browser click at a time, the agent writes Playwright code, executes bash commands, and saves reusable scripts in a local workspace.
- ~1,000 lines of harness code spread across 3 modules — no hidden orchestration layer
- Single agent loop: Runner, Model Endpoint, and terminal Environment
- 86.7% on Online-Mind2Web | 60.1% on Odysseys with GPT-5.4
- Backends: OpenAI, Anthropic, OpenRouter
- Scripts work in Claude Code, Codex, OpenClaw
# GitHub repository
github.com/microsoft/WebwrightWhat You Need Before Installing
Make sure the following are set up before running any install commands.
- Python 3.10+ — minimum required runtime
- Chromium — installed via Playwright in the next step
- API key — OpenAI, Anthropic, or OpenRouter
- Git — to clone the repository
# Check your Python version python --version # Must return Python 3.10 or higher
Clone and Install Webwright
Clone the repo, install in editable mode, then set up Chromium for Playwright browser control.
# 1. Clone the repository git clone cd Webwright # 2. Install the package in editable mode pip install -e . # 3. Install Chromium for Playwright playwright install chromium
The -e flag means changes to local source take effect immediately without reinstalling.
Run Your First Web Task
Export your API key, then provide a task instruction and start URL via the CLI.
# Export your key export OPENAI_API_KEY="sk-..." export ANTHROPIC_API_KEY="sk-ant-..." # Run a task python -m webwright.run.cli -c base.yaml -c model_openai.yaml -t "Find cheapest economy flight SEA to JFK on 2026-05-15" --start-url --task-id demo_openai -o outputs/default
| Flag | Description |
|---|---|
| -c | Config file from src/webwright/config/ — stackable |
| -t | Task instruction in plain English |
| –start-url | Starting URL for the browser session |
| –task-id | Name of the output subfolder |
| -o | Root output directory for logs and scripts |
Use Webwright as a Claude Code Skill
Webwright includes a built-in Claude Code skill. No separate LLM API key is required beyond your Claude Code subscription. Claude Code handles PNG screenshots natively.
# Project-scoped (inside this repo only) mkdir -p .claude/skills .claude/commands ln -s "$PWD/skills/webwright" .claude/skills/webwright ln -s "$PWD/skills/webwright/commands" .claude/commands/webwright # User-scoped (all projects) mkdir -p ~/.claude/skills ~/.claude/commands ln -s "$PWD/skills/webwright" ~/.claude/skills/webwright ln -s "$PWD/skills/webwright/commands" ~/.claude/commands/webwright
Restart Claude Code after installing, then use slash commands:
# One-shot task /webwright:run search Google Flights SEA to JFK 2026-05-15 # Reusable parameterized CLI tool /webwright:craft search a ticket from LAX to SFO depart June 7
Source: github.com/microsoft/Webwright
Key Takeaways
- Webwright runs a terminal loop where the agent writes and executes Playwright code instead of predicting individual browser actions.
- GPT-5.4 achieved 86.7% on Online-Mind2Web (100-step budget) and 60.1% on Odysseys — 26.6 points above the base GPT-5.4 score of 33.5%.
- The harness spans ~1,000 lines across three modules with no multi-agent orchestration.
- Qwen3.5-9B hit 66.2% on the hard split of Online-Mind2Web when given pre-built tool scripts.
- Task scripts are packaged as reusable CLIs, working across Claude Code, Codex, and OpenClaw.
Check out the Repo and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us