



Microsoft has launched Phi-4-reasoning-vision-15B, a 15 billion parameter open-weight multimodal reasoning mannequin designed for picture and textual content duties that require each notion and selective reasoning. It’s a compact mannequin constructed to steadiness reasoning high quality, compute effectivity, and training-data necessities, with specific power in scientific and mathematical reasoning and understanding consumer interfaces.

What the mannequin is constructed on?
Phi-4-reasoning-vision-15B combines the Phi-4-Reasoning language spine with the SigLIP-2 imaginative and prescient encoder utilizing a mid-fusion structure. On this setup, the imaginative and prescient encoder first converts photographs into visible tokens, then these tokens are projected into the language mannequin embedding area and processed by the pretrained language mannequin. This design acts as a sensible trade-off: it preserves robust cross-modal reasoning whereas holding coaching and inference prices manageable in contrast with heavier early-fusion designs.
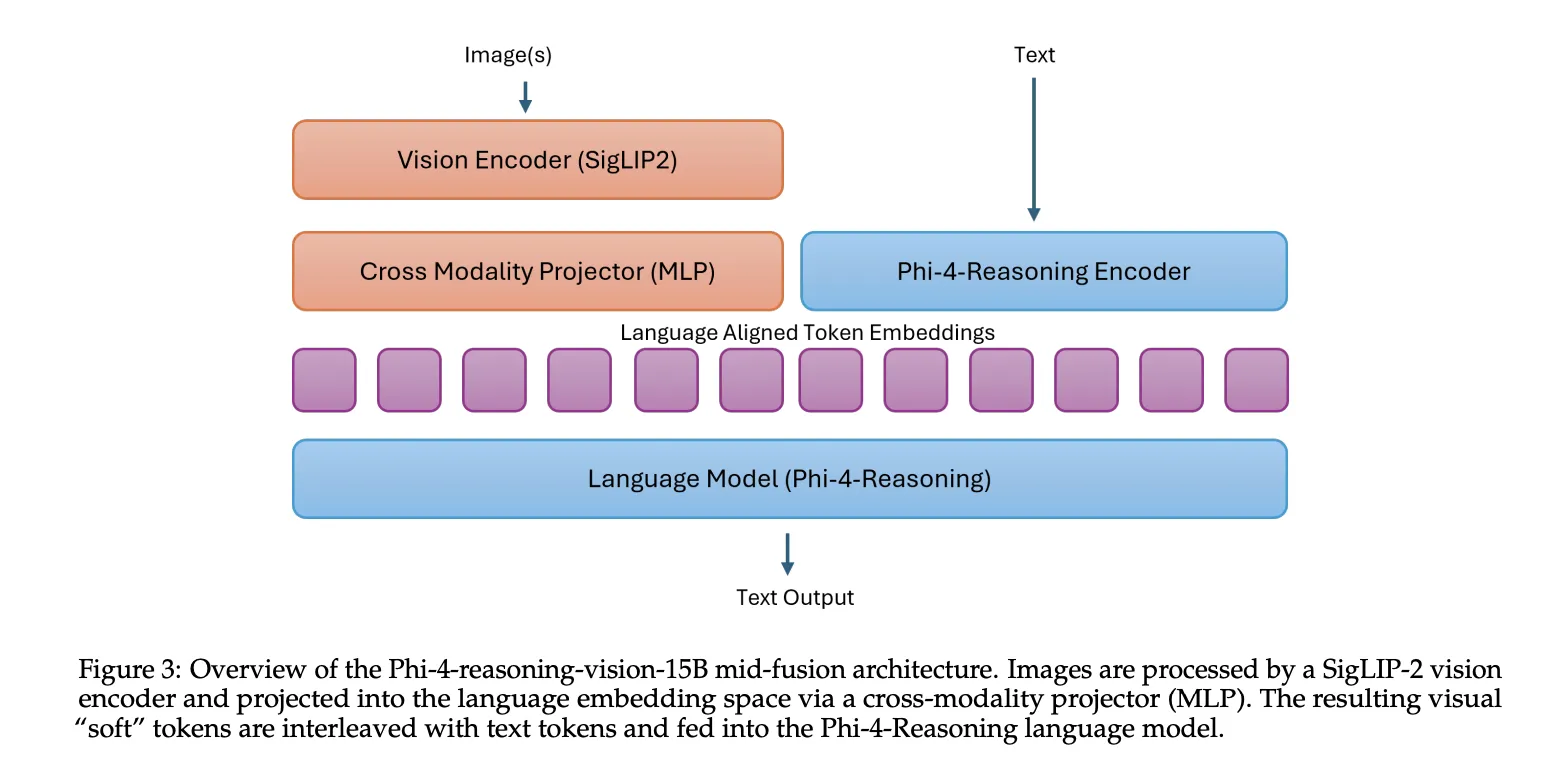
Why Microsoft took the smaller-model route?
Many latest vision-language fashions have grown in parameter depend and token utilization, which raises each latency and deployment price. Phi-4-reasoning-vision-15B was constructed as a smaller different that also handles frequent multimodal workloads with out counting on extraordinarily massive coaching datasets or extreme inference-time token era. The mannequin was skilled on 200 billion multimodal tokens, constructing on Phi-4-Reasoning, which was skilled on 16 billion tokens, and finally on the Phi-4 base mannequin, which was skilled on 400 billion distinctive tokens. Microsoft contrasts that with the greater than 1 trillion tokens used to coach a number of latest multimodal fashions reminiscent of Qwen 2.5 VL, Qwen 3 VL, Kimi-VL, and Gemma 3.
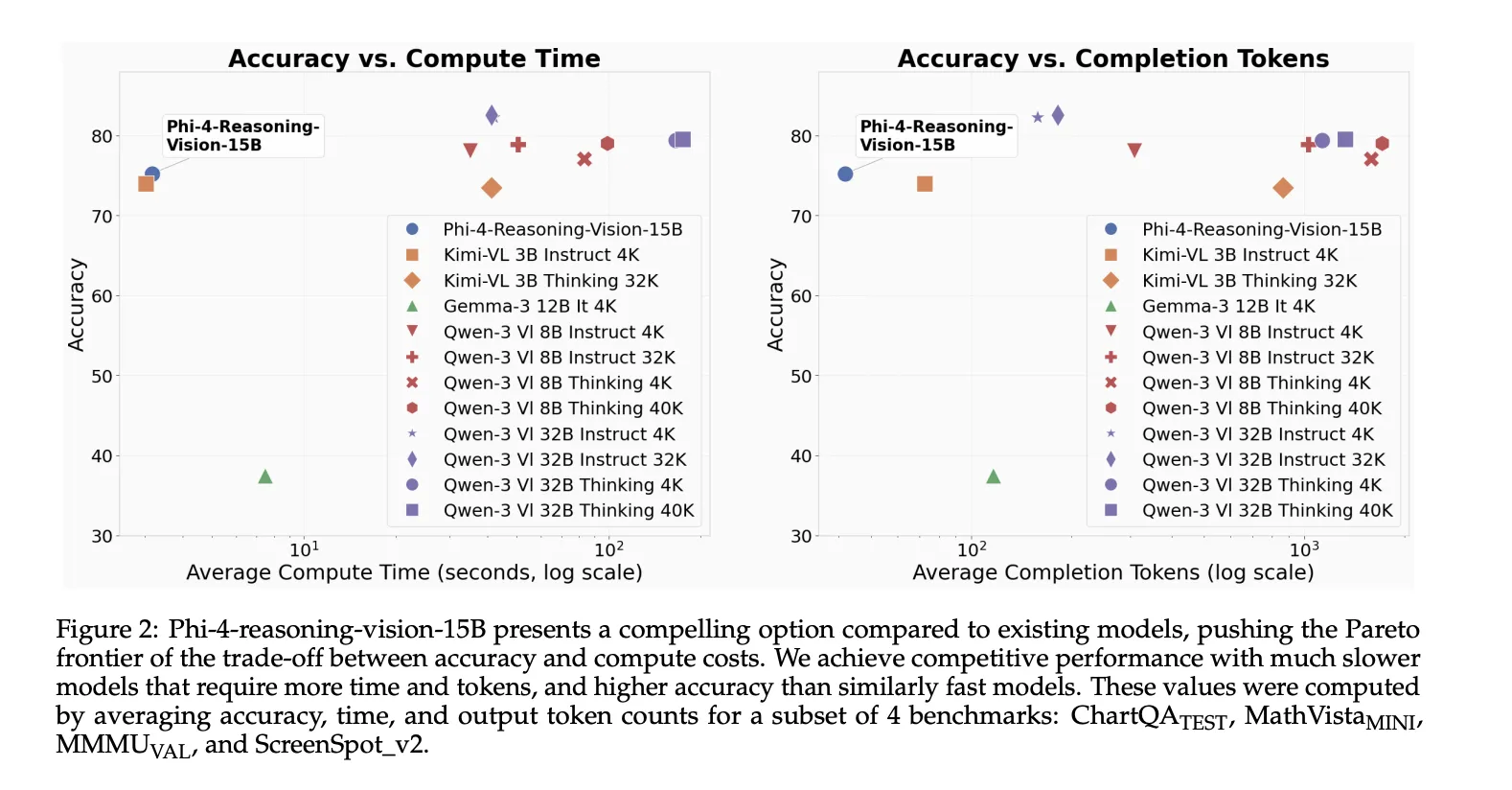
Excessive-resolution notion was a core design selection
Microsoft group explains one of many extra helpful technical classes of their technical report that multimodal reasoning usually fails as a result of notion fails first. Fashions can miss the reply not as a result of they lack reasoning capability, however as a result of they fail to extract the related visible particulars from dense photographs reminiscent of screenshots, paperwork, or interfaces with small interactive parts.
Phi-4-reasoning-vision-15B makes use of a dynamic decision imaginative and prescient encoder with as much as 3,600 visible tokens, which is meant to help high-resolution understanding for duties reminiscent of GUI grounding and fine-grained doc evaluation. The Microsoft group states that high-resolution, dynamic-resolution encoders yield constant enhancements, and explicitly notes that correct notion is a prerequisite for high-quality reasoning.
Blended reasoning as an alternative of forcing reasoning in all places
A second vital design choice is the mannequin’s blended reasoning and non-reasoning coaching technique. Relatively than forcing chain-of-thought-style reasoning for all duties, Microsoft group skilled the mannequin to change between two modes. Reasoning samples embody
The aim of this hybrid setup is to let the mannequin reply immediately on duties the place longer reasoning provides latency with out bettering accuracy, whereas nonetheless invoking structured reasoning on duties reminiscent of math and science. Microsoft group additionally notes an vital limitation: the boundary between these modes is discovered implicitly, so switching is just not at all times optimum. Customers can override the default habits by way of express prompting with
What areas are stronger?
Microsoft group highlights 2 essential software areas. The primary is scientific and mathematical reasoning over visible inputs, together with handwritten equations, diagrams, charts, tables, and quantitative paperwork. The second is computer-use agent duties, the place the mannequin interprets display content material, localizes GUI parts, and helps interplay with desktop, internet, or cellular interfaces.
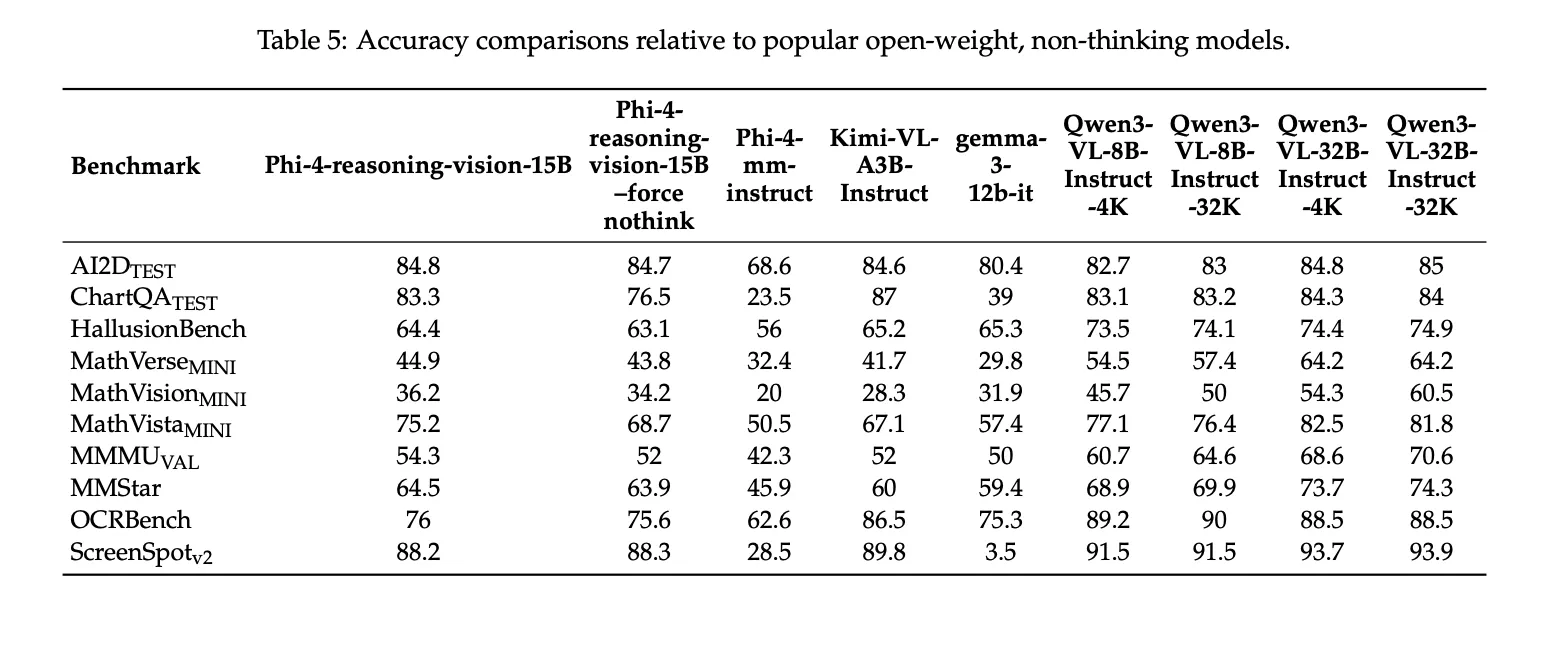
Benchmark outcomes
Microsoft group reviews the next benchmark scores for Phi-4-reasoning-vision-15B: 84.8 on AI2DTEST, 83.3 on ChartQATEST, 44.9 on MathVerseMINI, 36.2 on MathVisionMINI, 75.2 on MathVistaMINI, 54.3 on MMMUVAL, 64.5 on MMStar, 76.0 on OCRBench, and 88.2 on ScreenSpotv2. The technical report additionally notes that these outcomes had been generated utilizing Eureka ML Insights and VLMEvalKit, with mounted analysis settings, and that Microsoft group presents them as comparability outcomes somewhat than leaderboard claims.
Key Takeaways
- Phi-4-reasoning-vision-15B is a 15B open-weight multimodal mannequin constructed by combining Phi-4-Reasoning with the SigLIP-2 imaginative and prescient encoder in a mid-fusion structure.
- Microsoft group designed the mannequin for compact multimodal reasoning, with a deal with math, science, doc understanding, and GUI grounding, somewhat than scaling to a a lot bigger parameter depend.
- Excessive-resolution visible notion is a core a part of the system, with help for dynamic decision encoding and as much as 3,600 visible tokens, which helps on dense screenshots, paperwork, and interface-heavy duties.
- The mannequin makes use of blended reasoning and non-reasoning coaching, permitting it to change between
- Microsoft’s reported benchmarks present robust efficiency for its measurement, together with outcomes on AI2DTEST, ChartQATEST, MathVistaMINI, OCRBench, and ScreenSpotv2, which helps its positioning as a compact however succesful vision-language reasoning mannequin.
Take a look at the Paper, Repo and Mannequin Weights. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be part of us on telegram as nicely.