



Scientists at Meta’s FAIR lab have launched NeuralSet, a Python framework focused on removing an essential bottleneck in Neuro-AI analysis: the tough, fragmented technique of getting neural information into deep studying fashions.
The Downside: Neuroscience Information Stays within the Pre-Deep-Studying Period
Neuroscience boasts glorious, well-proven instruments. Functions like MNE-Python, EEGLAB, FieldTrip, Brainstorm, Nilearn, and fMRIPrep set the gold normal for sign processing in electrophysiology and neuroimaging. The difficulty is that these instruments had been created for a pre-deep-learning period: they rely on loading complete datasets into RAM and lack built-in strategies to temporally align neural time sequence with high-dimensional embeddings from trendy AI instruments like HuggingFace Transformers.
The affect? Researchers make investments huge effort constructing improvised pipelines that require handbook information manipulation, handbook caching, and sophisticated backend setups — largely to pair mind exercise information with, say, GPT-2 textual content embeddings for a single experiment. As public datasets on platforms like OpenNeuro now attain the terabyte scale, and experimental protocols more and more contain steady speech and video, this infrastructure hole is now not simply inconvenient — it’s a critical scientific bottleneck.

What NeuralSet Truly Does
NeuralSet’s core theory is structure–information separation. As a substitute of loading uncooked information prematurely, NeuralSet represents the logical construction of any experiment as light-weight, event-driven metadata — utterly separate from the memory-intensive technique of retrieving precise indicators. The framework is structured round 5 key abstractions: Occasions, Extractors, Segments, Batch Knowledge, and a Backend layer.
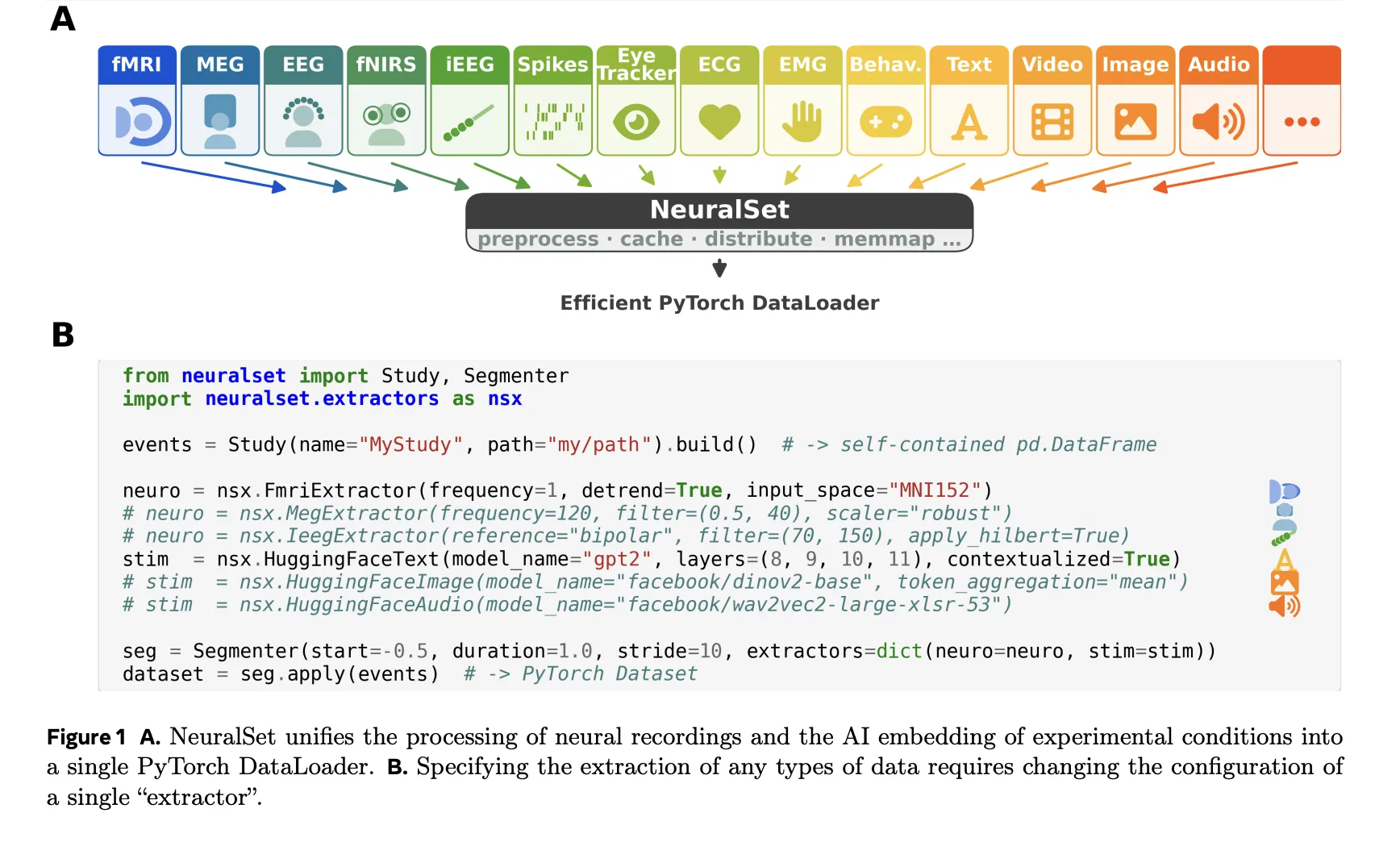
In follow, every little thing within the experiment — an fMRI run, a spoken phrase throughout a activity, a video stimulus — is modeled as an Occasion: a light-weight Python dictionary outlined by a types, begin time, period, and a timeline (a novel identifier for a steady recording session). A Research object collects all occasions in a complete dataset into one pandas DataFrame. Importantly, NeuralSet helps BIDS-compliant datasets, although it isn’t restricted to them. As a result of the DataFrame incorporates solely light-weight metadata — not the uncooked information — builders can filter, discover, and recombine huge datasets with normal pandas operations with out loading any uncooked information into reminiscence.
Composable EventsTransform operations can then be chained to counterpoint or filter occasions — for instance, annotating phrases with their sentence context, assigning cross-validation splits, or splitting lengthy audio and video segments into shorter items. A number of Research and Rework steps will also be composed collectively utilizing a Chain, which creates one reproducible, cacheable pipeline object.
Note: The HTML structure and all attributes have been preserved exactly as requested.
NeuralSet employs Extractors to bridge the gap between its metadata layer and the numerical arrays needed for machine learning models. For neural recordings, it harnesses the preprocessing capabilities of specialized libraries: the FmriExtractor uses Nilearn for tasks like signal denoising, spatial smoothing, and region-based mapping. Similarly, the MegExtractor or EegExtractor utilizes MNE-Python for filtering, re-referencing, and resampling signals. This Same unified approach also supports iEEG, fNIRS, EMG, and spike recordings—switching between these data types only requires adjusting a configuration setting, rather than rebuilding the entire pipeline.
Additionally, NeuralSet is seamlessly integrated with the HuggingFace ecosystem for handling experimental stimuli. A single HuggingFaceImage extractor can generate embeddings for stimulus frames using models like DINOv2 or CLIP. Equivalent extractors are available for audio (Wav2Vec, Whisper), text (GPT-2, LLaMA), and video (VideoMAE). A key feature of NeuralSet is its ability to expand a static embedding—such as a single vector representing an image—into a timeseries at any frequency. This ensures that stimulus representations are always perfectly synchronized with neural recordings.
Extractors operate using a three-step process: Configure (validating parameters during setup), Prepare (pre-computing and caching heavy outputs for all events), and Extract (retrieving cached data on-demand during model training). This approach ensures that computationally expensive tasks, such as processing every word in a massive dataset through a large language model, are executed once and reused across multiple experiments. The result of the extraction process is Batch Data: a dictionary of tensors organized by the name of the extractor, complete with corresponding data segments.
Segmenter, DataLoader, and Cluster-Ready Infrastructure
The Segmenter tool organizes the events DataFrame into Segments—contiguous time windows that represent individual training instances—using either a continuous sliding window or by anchoring to specific triggers, such as the onset of an image or a word. The resulting SegmentDataset is a standard PyTorch Dataset, making it fully compatible with DataLoader, PyTorch Lightning, or any other PyTorch-based framework.
NeuralSet is powered by the exca package, which ensures deterministic, hash-based caching, full computational provenance, and hardware-agnostic execution. Altering a single preprocessing parameter automatically invalidates only the relevant downstream cached data, leaving other independent operations untouched. This provenance tracking allows any processed tensor to be traced back to the exact version of the raw data and the specific preprocessing steps used to generate it. Researchers can begin by prototyping on a single subject using their laptop and then scale up to 100 subjects on an HPC cluster running SLURM by changing just one configuration flag.
NeuralSet utilizes Pydantic to implement rigorous schema validation at startup for every configurable object. Since Events, Studies, Extractors, Segmenters, and Transforms are all Pydantic BaseModel subclasses, a misconfigured parameter—like a negative filter frequency or an invalid BIDS directory path—will trigger an immediate and clear error before any job starts, rather than causing a failure hours into a processing run.
How It Compares to Current Tools
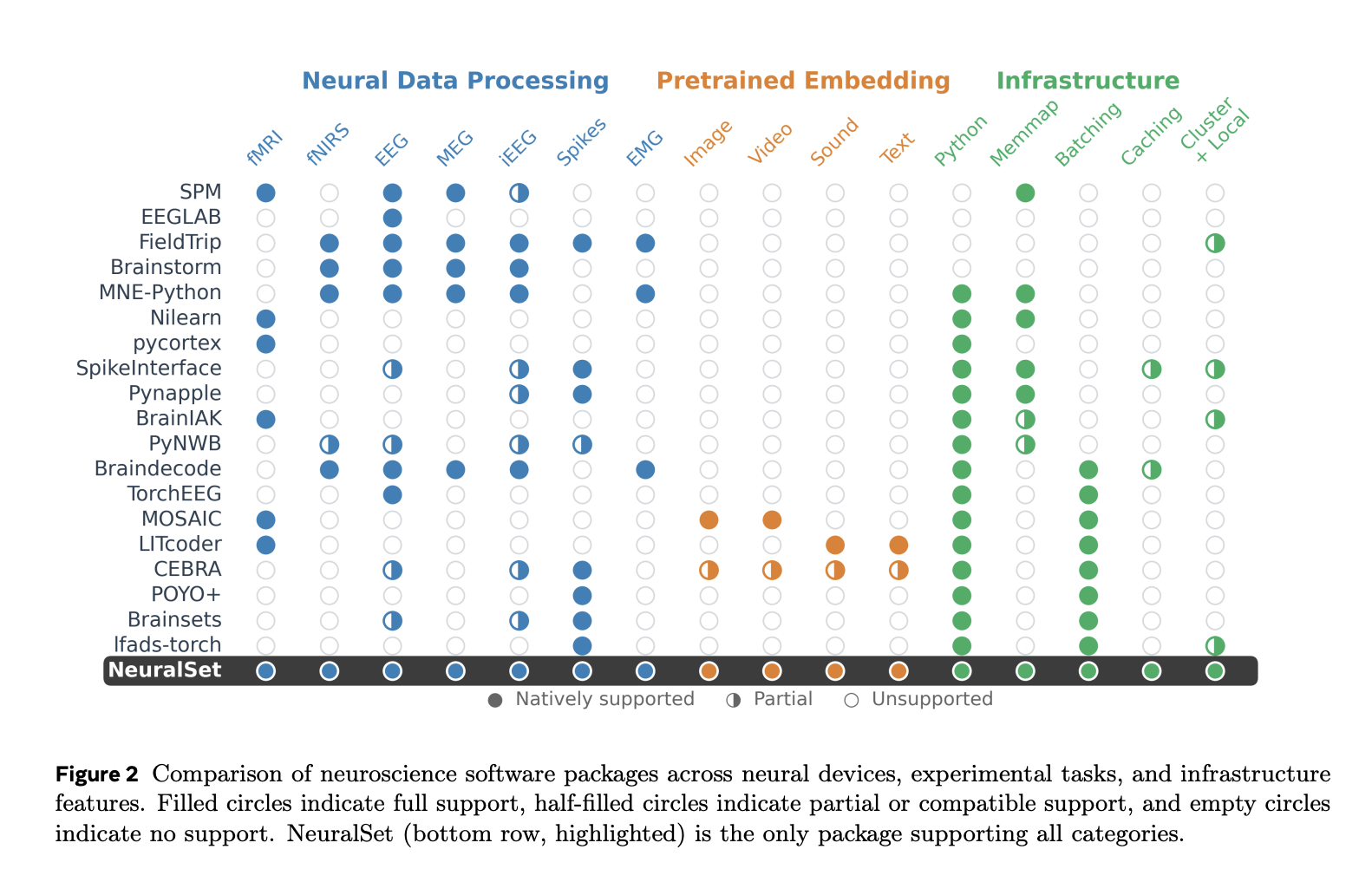
In the accompanying research paper, the team provides a detailed benchmark of NeuralSet against 18 existing neuroscience software packages across different recording devices (fMRI, EEG, MEG, iEEG, spikes, etc.), experimental task categories (images, video, audio, text), and infrastructure
NeuralSet stands out as the only solution in this comparison that delivers comprehensive support across all categories, including Python assist, memory mapping, batching, caching, and cluster execution.
Key Takeaways
- NeuralSet brings together brain data and AI within a single streamlined pipeline. Developed by researchers at Meta FAIR, NeuralSet was designed to connect the dots between various types of neural recordings — such as fMRI, M/EEG, and spike data — and contemporary deep learning frameworks, offering a unified PyTorch-ready DataLoader for all of them.
- Decoupling structure from data removes memory bottlenecks. NeuralSet keeps lightweight event metadata separate from heavy signal extraction, enabling AI developers and researchers to filter and navigate terabyte-scale datasets without ever loading raw data into RAM.
- Switching between recording modalities takes just one config change. A unified Extractor interface integrates MNE-Python, Nilearn, and HuggingFace models — covering fMRI, EEG, MEG, iEEG, fNIRS, EMG, spikes, text, audio, and video — with no need to rewrite any pipeline code.
- Pydantic validation and deterministic caching prevent wasted computation. Configuration mistakes are caught at initialization before any job begins, and a hash-based caching mechanism guarantees that expensive operations like LLM embeddings are computed only once and reused across every experiment.
- The identical codebase runs on a laptop or a SLURM cluster. NeuralSet’s hardware-agnostic backend, powered by the
excapackage, allows researchers and AI developers to scale effortlessly from local prototyping to high-performance cluster execution by toggling a single configuration flag.
Check out the Paper and GitHub Page. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! Are you on Telegram? You can now join us on Telegram as well.
Interested in partnering with us to promote your GitHub Repo, Hugging Face Page, Product Launch, Webinar, or more? Get in touch with us