



Picture by Creator
# Introduction
You may need launched what appeared to be a profitable experiment: conversions jumped 8%, engagement metrics were trending positively. But shortly after the update went live or a month later, things fell apart.
If this situation rings a bell, you are in good company. The root cause of most A/B test failures is not flawed product ideas but flawed experimentation processes.
The metrics tricked you, the rules for ending the test were not followed, or nobody verified whether the “success” was just random noise mistaken for a meaningful signal. Here’s the hard truth: the systems supporting your experiment matter more than the changes being tested, and most teams handle them poorly.
Let’s dissect the four hidden traps of A/B testing, from misleading data to faulty reasoning, and highlight the rigorous habits that differentiate top performers from everyone else.
Picture by Creator
# When Data Lies: SRM and Data Quality Failures
Pitfall: Many “surprising” test results aren’t insights; they are data-quality issues in disguise.
Sample Ratio Mismatch (SRM) acts as an early warning signal. You expect a 50/50 split but see 52/48. Seems minor. It’s not. SRM suggests problems with randomization, biased traffic routing, or logging errors that quietly distort your findings.
Actual examples: Microsoft showed that SRM points to serious data quality problems that undermine experiment validity, so tests with SRM often lead to flawed rollout decisions. DoorDash noticed SRM after low-engagement users disproportionately left one group due to a bug fix, skewing outcomes and creating false wins.
What to investigate if SRM appears:
Picture by Creator
- Chi-squared test for traffic splits: automate this prior to any analysis.
- User-level vs. session-level logging: inconsistent granularity causes phantom results.
- Time-based bucketing bugs: Monday visitors in control, Friday visitors in treatment = confounded results.
Solution: The fix isn’t statistical finesse. It’s data hygiene. Run SRM checks before metrics. If the experiment fails the ratio check, stop. Investigate. Correct the randomization. No exceptions.
If you want to practice spotting data-quality issues like SRM or logging mismatches, try hands-on SQL data-cleaning and anomaly-detection exercises on StrataScratch. You’ll work with real company datasets to sharpen your debugging and validation abilities.
Most teams skip this step. This is why most “winning” experiments collapse in production.
# End Peeking: The Way Early Detection Harms Validity
Pitfall: Reviewing your results every morning feels productive. It’s not. It’s systematically inflating your rate of false discoveries.
Here’s the reason: each time you check p-values and decide whether to end early, you give randomness another opportunity to mislead you. Peek at a null effect 20 times, and you’ll eventually see p < 0.05 by pure chance. Optimizely‘s research shows that uncorrected peeking can inflate false positives from 5% to over 25%, meaning one out of four “wins” is really noise.
How to spot a naive approach:
- Run the experiment for two weeks.
- Check daily.
- End when p < 0.05.
- Outcome: You’ve conducted 14 separate comparisons without proper adjustment.
Solution: Adopt sequential testing or always-valid inference methods that account for multiple looks.
Real-world approaches:
- Spotify‘s method: Group sequential testing (GST) with alpha spending functions efficiently manage repeated checks by leveraging correlation patterns between interim analyses.
- Optimizely’s tool: Always-valid p-values that support continuous monitoring, enabling safe peeking without inflating error rates.
- Netflix‘s approach: Sequential testing with anytime-valid confidence sequences transitioning from fixed-horizon to continuous monitoring while maintaining Type I error guarantees.
If you must peek, use tools designed for the purpose. Don’t improvise with basic t-tests.
The bottom line: Define your stopping rule before launching. “Stop when it looks good” isn’t a rule; it’s a path to unreliable conclusions.
# Power That Works: CUPED and Modern Variance Reduction
Pitfall: Running longer experiments isn’t the answer. Designing smarter experiments is.
Answer: CUPED (Controlled-experiment Utilizing Pre-Experiment Data) is Microsoft’s approach to noisy metrics. The method uses pre-experiment behavior to forecast post-experiment results, then focuses only on the residual difference. By accounting for predictable variation, you minimize confidence intervals without collecting more data.
Real-world cases: Microsoft found that, for one product team, CUPED delivered results equivalent to increasing experiment traffic by 20%. Netflix achieved variance reductions of around 40% on core engagement metrics. Statsig discovered that CUPED cut variance by 50% or more for most common metrics, meaning experiments reached significance in half the time or with half the sample size.
How it works:
Adjusted_metric = Raw_metric - θ × (Pre_period_metric - Mean_pre_period)Translation: If a user previously spent $100/week, and your experiment cohort averages $90/week pre-test, CUPED adjusts downward for users already spending at higher rates. You’re capturing the treatment effect, not pre-existing differences.
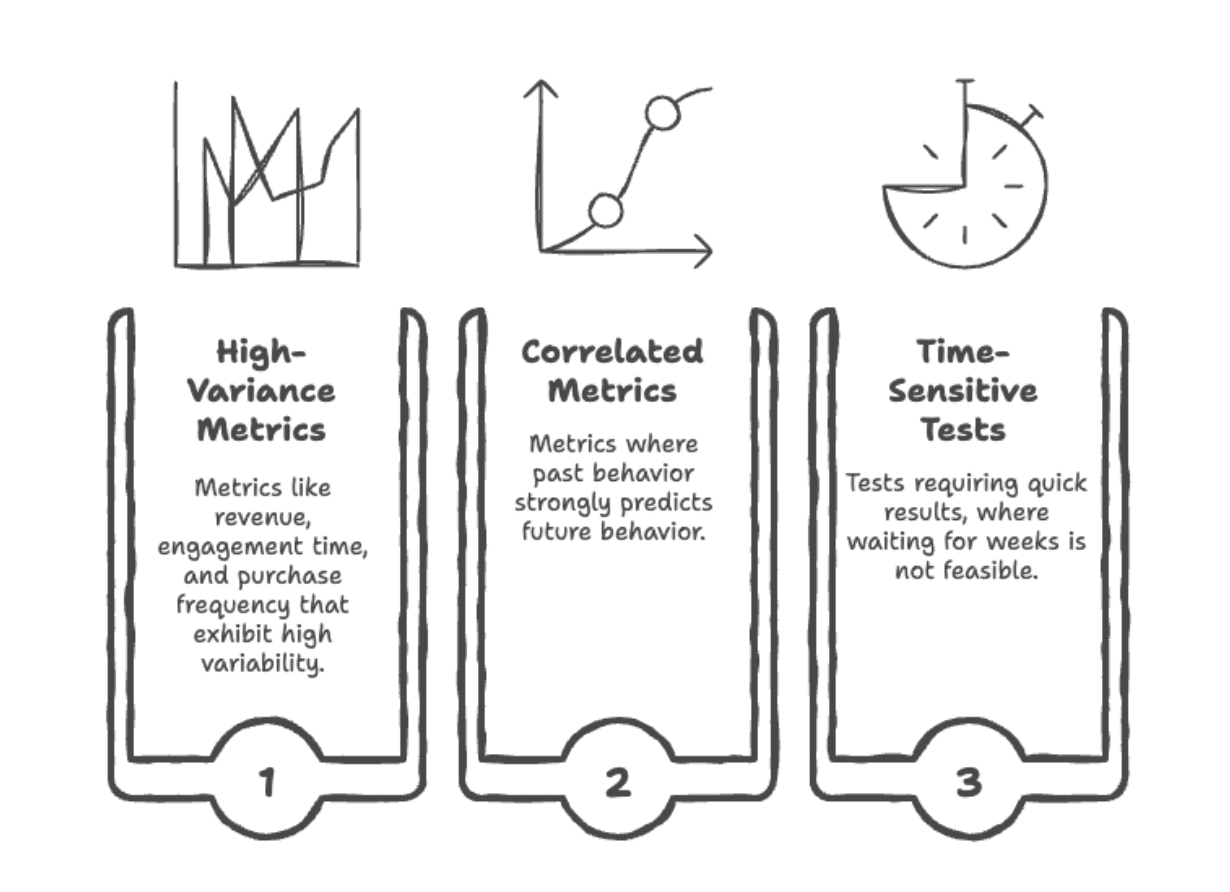
When should you apply CUPED?
Picture by Creator
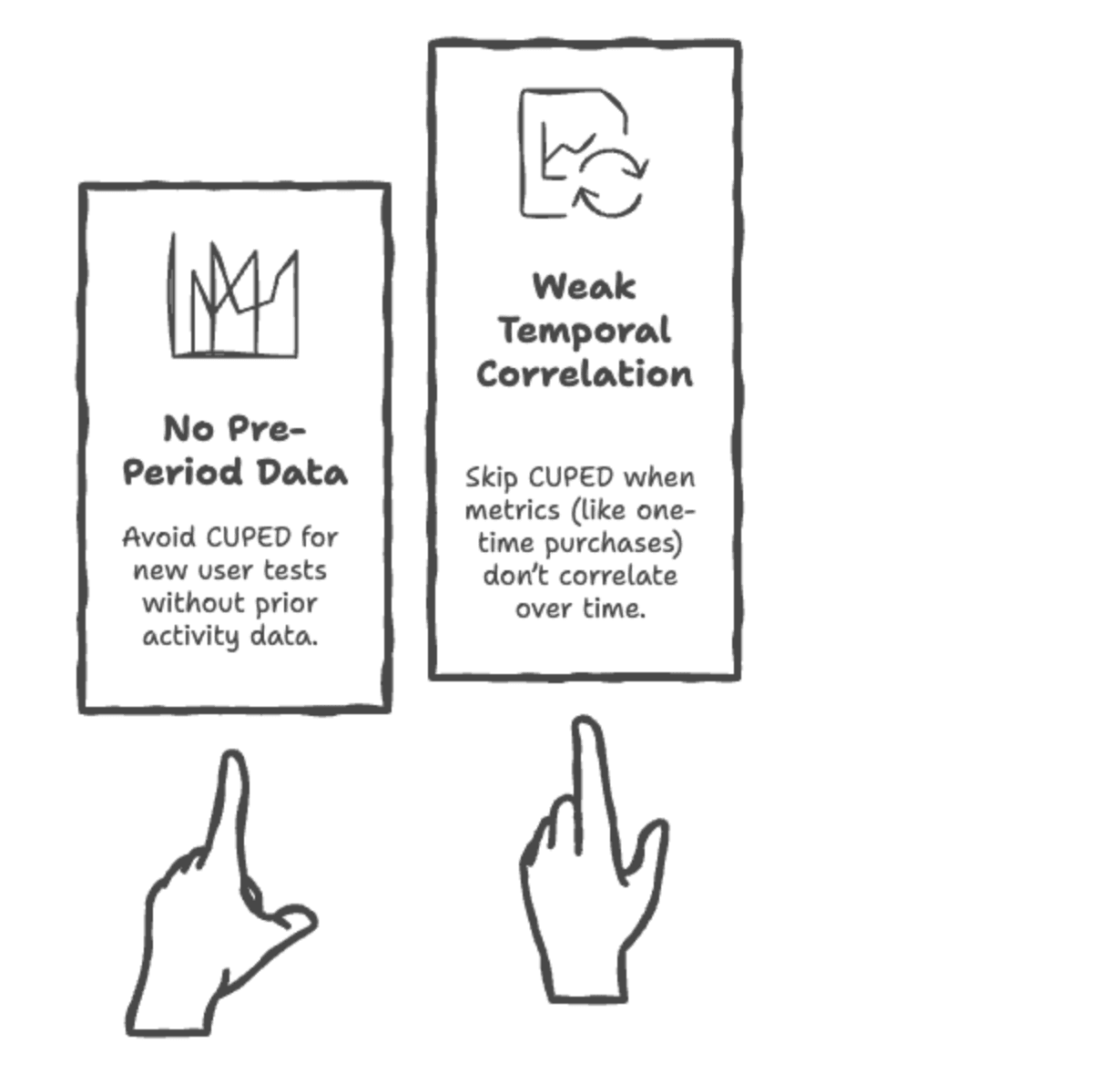
When should you avoid CUPED?
Picture by Creator
Emerging methods like CUPAC (integrating covariates across multiple metrics) and stratified sampling take this further, but the logic remains the same: reduce noise before analyzing, not after.
Implementation note: Most current experimentation platforms (Optimizely, Eppo, GrowthBook) include CUPED support out of the box. If you’re building internally, incorporate pre-period covariates into your analysis pipeline; the performance boost is well worth
This is where the real engineering effort begins.
# Measuring What Matters: Guardrails and Long-Run Reality Checks
Pitfall: Chasing the wrong metric is more dangerous than having no metric at all.
A classic trap: You launch a feature because it boosted clicks by 12%. Three months later, user retention dropped 8%. What went wrong? You focused on a surface-level metric while ignoring downstream damage.
Solution: Guardrail metrics act as your safety net. These aren’t metrics you try to improve, but they help you spot unintended side effects:
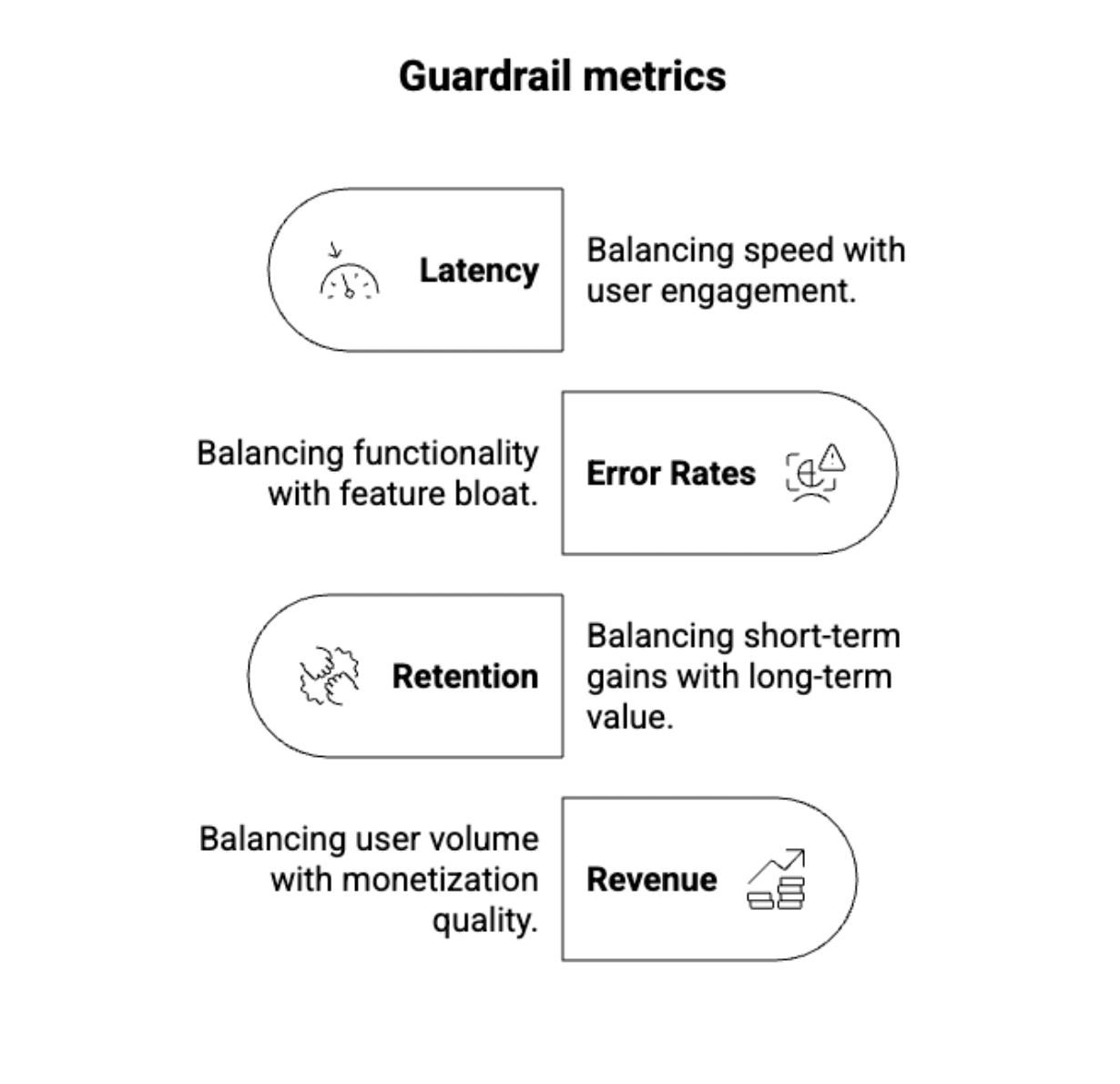
Image by Author
Real-world case: Airbnb discovered that while a certain change increased bookings, it also led to lower review scores. Though more people were booking, overall satisfaction took a hit. Thanks to guardrail metrics, the issue was caught before a full rollout. Out of thousands of monthly tests, Airbnb’s safeguards flag around 25 experiments for review each month, stopping about five potentially harmful launches.
How to set up guardrails:
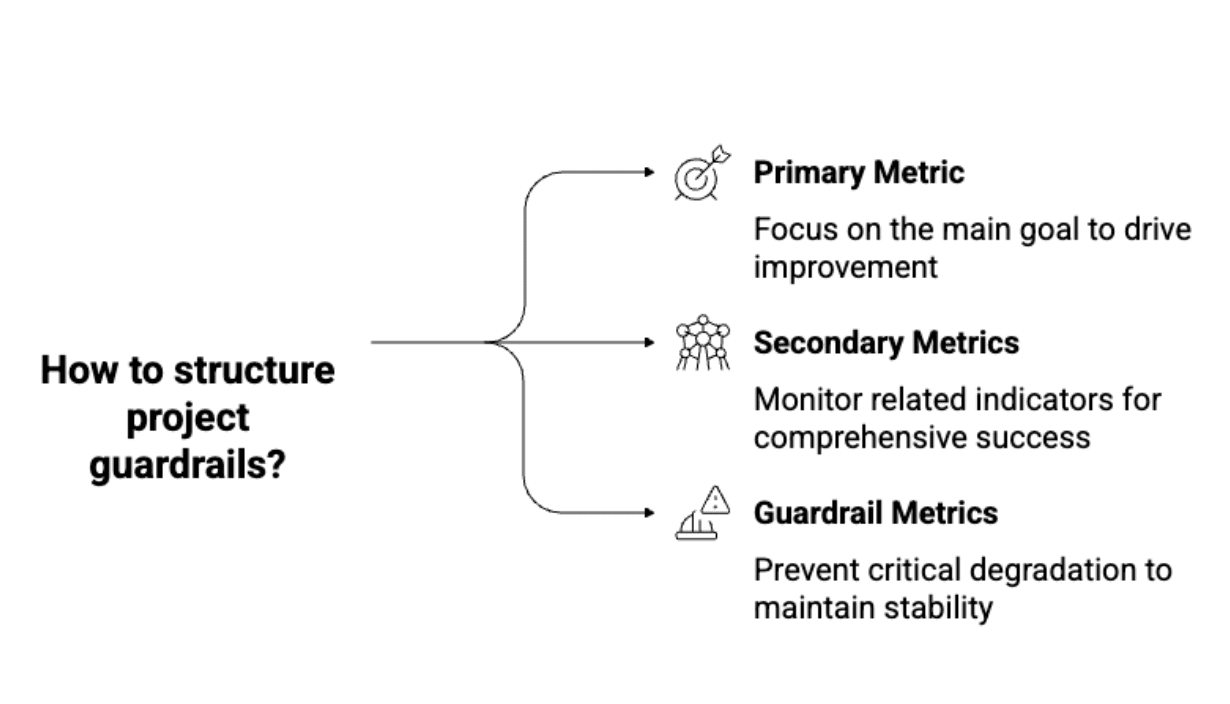
Image by Author
The novelty effect problem: Short-term tests often capture curiosity, not lasting value. Users might click a new button simply because it’s new—not because it’s better. Top companies use holdout groups to see whether the impact lasts, often keeping 5–10% of users in the old experience to monitor long-term behavior.
Best practice: Every test needs follow-up beyond the initial results:
- Phase 1: Standard A/B test (1–4 weeks) to assess immediate impact.
- Phase 2: Long-term validation with holdout groups or extended tracking.
If the effect fades during Phase 2, it wasn’t a real improvement—it was noise.
# What Leading Experimenters Do Differently
Top experimentation teams stand out not because of more complex stats, but due to stricter process discipline.
Here’s how companies like Booking.com, Netflix, and Microsoft approach things differently:
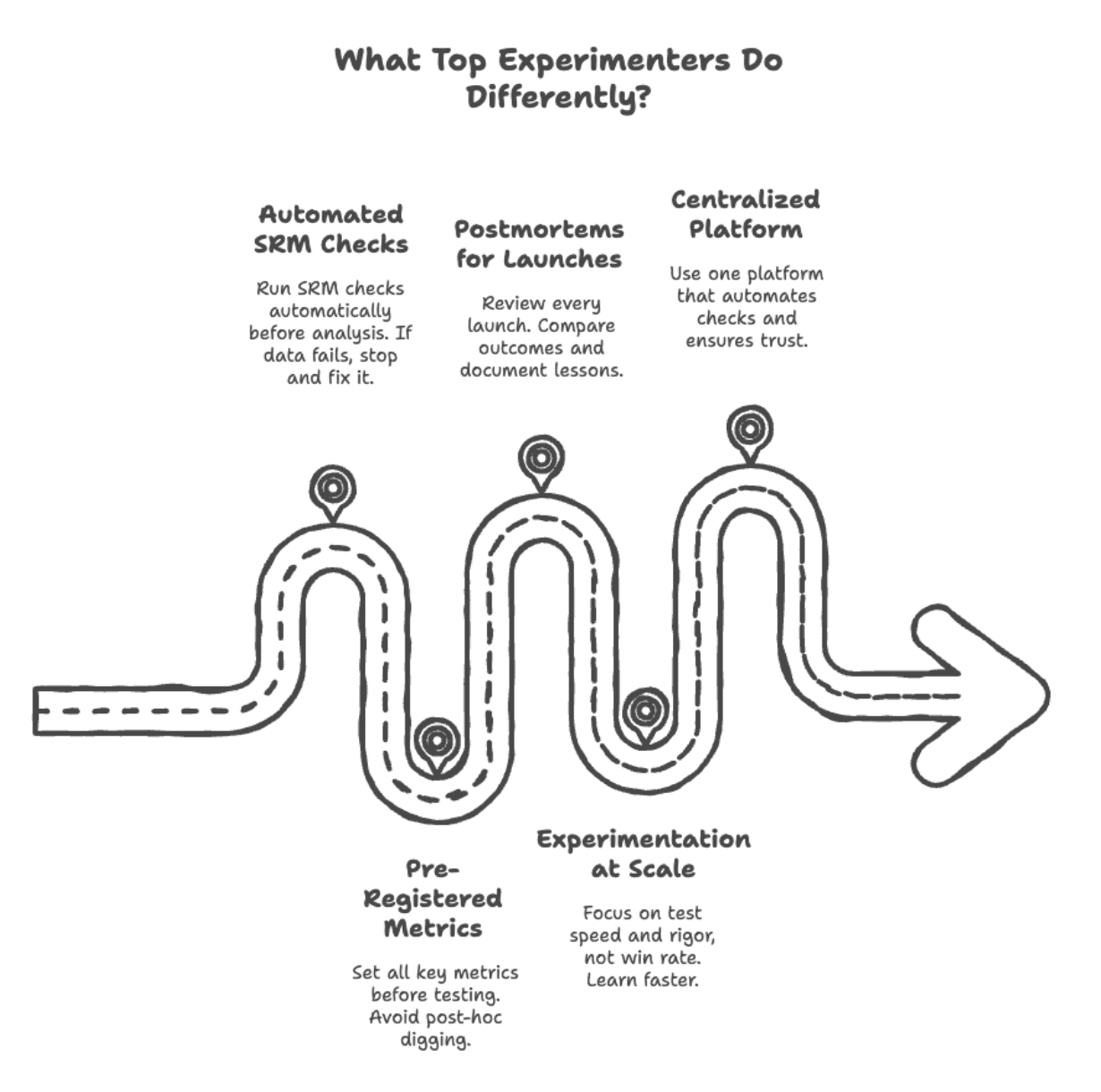
Image by Author
// Automating SRM Checks
Industry norm: Platforms like Optimizely and Statsig now automatically run Sample Ratio Mismatch checks on every test. If something fails, a warning shows up immediately. No overrides. No “we’ll take a look later.” You either fix the issue or don’t push the change.
Booking.com treats data quality seriously and insists that problems be identified before any results are even reviewed—making SRM checks an essential checkpoint.
// Committing to Metrics Ahead of Time
Solid move: Decide ahead of time which metrics are primary, secondary, and guardrails. No hunting around for flattering numbers after the fact. If revenue wasn’t planned as a goal, don’t declare victory based on it later.
Netflix’s method: They define target metrics in advance and include guardrails such as customer support calls, so if something unexpected comes up, it’s noticed early.
// Conducting Post-Launches Reviews
Microsoft’s ExP way: After every rollout, regardless of outcome, teams run postmortems considering:
- Was the predicted effect accurate?
- Did all guardrails stay intact?
- What could we improve next time?
This isn’t just paperwork—it’s building institutional memory.
// Scaling Up Experimentation
Booking.com’s output: Running over a thousand tests simultaneously has shown them that most experiments—around 90%—won’t move the needle. But that’s expected; it’s all part of learning faster than competitors.
Teams aren’t judged purely by wins but rather by:
- Test speed (how many experiments per quarter).
- Data integrity (keeping sample ratios honest).
- Follow-through rates (what percentage of valid results actually make it to launch).
This keeps people from gaming the system and rewards true rigor.
// Centralizing Experiment Infrastructure
Strong teams avoid letting individual engineers create ad hoc tests; instead, they rely on centralized platforms which enforce consistency in randomization, auto-calculate required sample sizes, perform SRM checks by default, and timestamp decisions for audit purposes.
Why does this matter? More data doesn’t guarantee better results—rigorous process does. Automation turns discipline into routine.
# Conclusion
The hardest truth in scaling experimentation has less to do with formulas and more to do with culture. You might know every statistical trick in the book, but if your organization peeks at data prematurely, brushes off SRM warnings, or launches “wins” without proper validation, your progress will stall.
Ultimately, what separates teams that grow from those that struggle with endless false leads—isn’t raw talent; it’s enforced rigor, automated checks, and shared skepticism toward anything that “looks promising” too soon.
Next time you’re tempted to peek early or ignore an SRM alert—remember: convincing yourself things are clear when they aren’t is the most expensive mistake you can make in experimentation.