



There’s a specific type of tedium that each AI engineer is aware of intimately: the prompt-tuning loop. You write a system immediate, run your agent in opposition to a benchmark, learn the failure traces, tweak the immediate, add a device, rerun. Repeat this a couple of dozen occasions and also you may transfer the needle. It’s grunt work dressed up in Python information. Now, a brand new open-source library known as AutoAgent, constructed by Kevin Gu at thirdlayer.inc, proposes an unsettling various — don’t do this work your self. Let an AI do it.
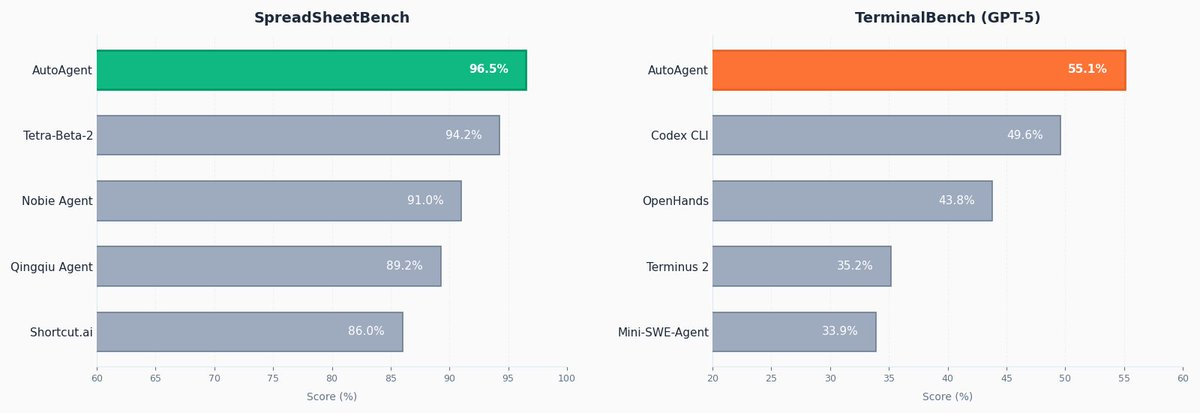
AutoAgent is an open supply library for autonomously bettering an agent on any area. In a 24-hour run, it hit #1 on SpreadsheetBench with a rating of 96.5%, and achieved the #1 GPT-5 rating on TerminalBench with 55.1%.
What Is AutoAgent, Actually?
AutoAgent is described as being ‘like autoresearch but for agent engineering.’ The thought: give an AI agent a activity, let it construct and iterate on an agent harness autonomously in a single day. It modifies the system immediate, instruments, agent configuration, and orchestration, runs the benchmark, checks the rating, retains or discards the change, and repeats.
To grasp the analogy: Andrej Karpathy’s autoresearch does the identical factor for ML coaching — it loops by means of propose-train-evaluate cycles, protecting solely adjustments that enhance validation loss. AutoAgent ports that very same ratchet loop from ML coaching into agent engineering. As a substitute of optimizing a mannequin’s weights or coaching hyperparameters, it optimizes the harness — the system immediate, device definitions, routing logic, and orchestration technique that decide how an agent behaves on a activity.
A harness, on this context, is the scaffolding round an LLM: what system immediate it receives, what instruments it could actually name, the way it routes between sub-agents, and the way duties are formatted as inputs. Most agent engineers hand-craft this scaffolding. AutoAgent automates the iteration on that scaffolding itself.
The Structure: Two Brokers, One File, One Directive
The GitHub repo has a intentionally easy construction. agent.py is your entire harness beneath check in a single file — it comprises config, device definitions, agent registry, routing/orchestration, and the Harbor adapter boundary. The adapter part is explicitly marked as fastened; the remainder is the first edit floor for the meta-agent. program.md comprises directions for the meta-agent plus the directive (what sort of agent to construct), and that is the one file the human edits.
Consider it as a separation of issues between human and machine. The human units the route inside program.md. The meta-agent (a separate, higher-level AI) then reads that directive, inspects agent.py, runs the benchmark, diagnoses what failed, rewrites the related components of agent.py, and repeats. The human by no means touches agent.py instantly.
A crucial piece of infrastructure that retains the loop coherent throughout iterations is outcomes.tsv — an experiment log mechanically created and maintained by the meta-agent. It tracks each experiment run, giving the meta-agent a historical past to be taught from and calibrate what to attempt subsequent. The total undertaking construction additionally contains Dockerfile.base, an optionally available .agent/ listing for reusable agent workspace artifacts like prompts and abilities, a duties/ folder for benchmark payloads (added per benchmark department), and a jobs/ listing for Harbor job outputs.
The metric is whole rating produced by the benchmark’s activity check suites. The meta-agent hill-climbs on this rating. Each experiment produces a numeric rating: preserve if higher, discard if not — the identical loop as autoresearch.
The Process Format and Harbor Integration
Benchmarks are expressed as duties in Harbor format. Every activity lives beneath duties/my-task/ and features a activity.toml for config like timeouts and metadata, an instruction.md which is the immediate despatched to the agent, a exams/ listing with a check.sh entry level that writes a rating to /logs/reward.txt, and a check.py for verification utilizing both deterministic checks or LLM-as-judge. An setting/Dockerfile defines the duty container, and a information/ listing holds reference information mounted into the container. Checks write a rating between 0.0 and 1.0 to the verifier logs. The meta-agent hill-climbs on this.
The LLM-as-judge sample right here is price flagging: as a substitute of solely checking solutions deterministically (like unit exams), the check suite can use one other LLM to guage whether or not the agent’s output is ‘correct enough.’ That is frequent in agentic benchmarks the place right solutions aren’t reducible to string matching.
Key Takeaways
- Autonomous harness engineering works — AutoAgent proves {that a} meta-agent can change the human prompt-tuning loop solely, iterating on
agent.pyin a single day with none human touching the harness information instantly. - Benchmark outcomes validate the method — In a 24-hour run, AutoAgent hit #1 on SpreadsheetBench (96.5%) and the highest GPT-5 rating on TerminalBench (55.1%), beating each different entry that was hand-engineered by people.
- ‘Model empathy’ could also be an actual phenomenon — A Claude meta-agent optimizing a Claude activity agent appeared to diagnose failures extra precisely than when optimizing a GPT-based agent, suggesting same-family mannequin pairing may matter when designing your AutoAgent loop.
- The human’s job shifts from engineer to director — You don’t write or edit
agent.py. You writeprogram.md— a plain Markdown directive that steers the meta-agent. The excellence mirrors the broader shift in agentic engineering from writing code to setting objectives. - It’s plug-and-play with any benchmark — As a result of duties observe Harbor’s open format and brokers run in Docker containers, AutoAgent is domain-agnostic. Any scorable activity — spreadsheets, terminal instructions, or your individual customized area — can turn into a goal for autonomous self-optimization.
Take a look at the Repo and Tweet. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.
Have to associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so on.? Join with us