



Liquid AI simply launched LFM2.5-VL-450M, an up to date model of its earlier LFM2-VL-450M vision-language mannequin. The brand new launch introduces bounding field prediction, improved instruction following, expanded multilingual understanding, and performance calling help — all inside a 450M-parameter footprint designed to run immediately on edge {hardware} starting from embedded AI modules like NVIDIA Jetson Orin, to mini-PC APUs like AMD Ryzen AI Max+ 395, to flagship cellphone SoCs just like the Snapdragon 8 Elite contained in the Samsung S25 Extremely.
What’s a Imaginative and prescient-Language Mannequin and Why Mannequin Dimension Issues
Earlier than going deeper, it helps to grasp what a vision-language mannequin (VLM) is. A VLM is a mannequin that may course of each pictures and textual content collectively — you possibly can ship it a photograph and ask questions on it in pure language, and it’ll reply. Most giant VLMs require substantial GPU reminiscence and cloud infrastructure to run. That’s an issue for real-world deployment eventualities like warehouse robots, sensible glasses, or retail shelf cameras, the place compute is restricted and latency have to be low.
LFM2.5-VL-450M is Liquid AI’s reply to this constraint: a mannequin sufficiently small to suit on edge {hardware} whereas nonetheless supporting a significant set of imaginative and prescient and language capabilities.
Structure and Coaching
LFM2.5-VL-450M makes use of LFM2.5-350M as its language mannequin spine and SigLIP2 NaFlex shape-optimized 86M as its imaginative and prescient encoder. The context window is 32,768 tokens with a vocabulary dimension of 65,536.
For picture dealing with, the mannequin helps native decision processing as much as 512×512 pixels with out upscaling, preserves non-standard facet ratios with out distortion, and makes use of a tiling technique that splits giant pictures into non-overlapping 512×512 patches whereas together with thumbnail encoding for world context. The thumbnail encoding is necessary: with out it, tiling would give the mannequin solely native patches with no sense of the general scene. At inference time, customers can tune the utmost picture tokens and tile depend for a velocity/high quality tradeoff with out retraining, which is helpful when deploying throughout {hardware} with completely different compute budgets.
The beneficial era parameters from Liquid AI are temperature=0.1, min_p=0.15, and repetition_penalty=1.05 for textual content, and min_image_tokens=32, max_image_tokens=256, and do_image_splitting=True for imaginative and prescient inputs.
On the coaching aspect, Liquid AI scaled pre-training from 10T to 28T tokens in comparison with LFM2-VL-450M, adopted by post-training utilizing choice optimization and reinforcement studying to enhance grounding, instruction following, and general reliability throughout vision-language duties.
New Capabilities Over LFM2-VL-450M
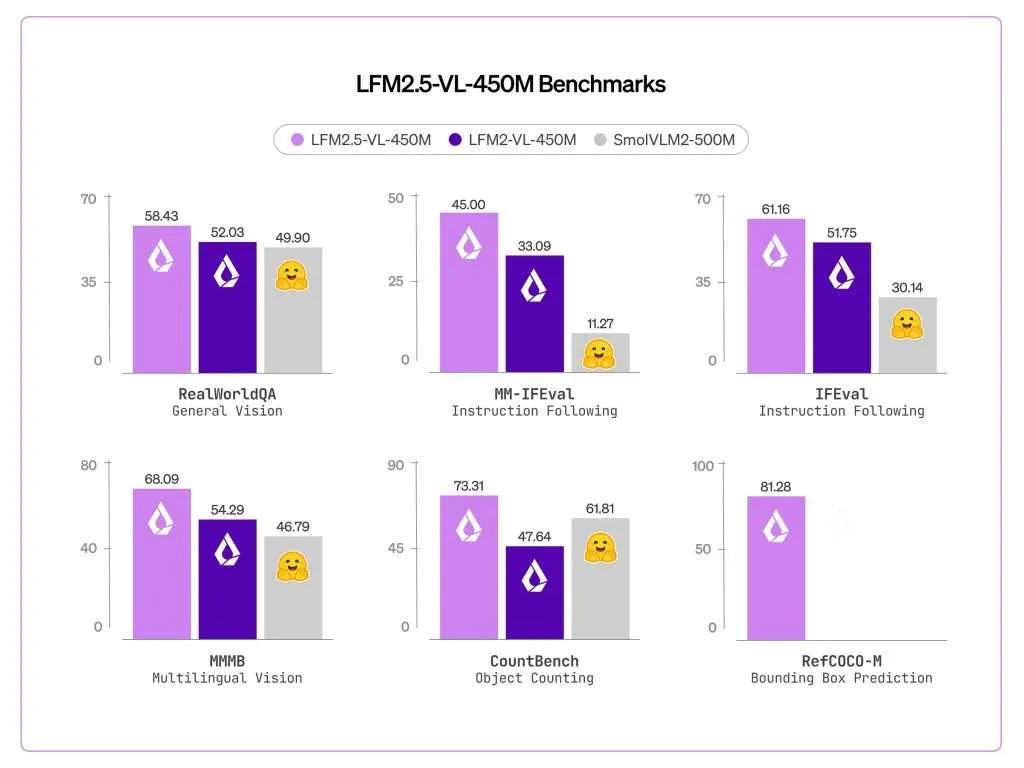
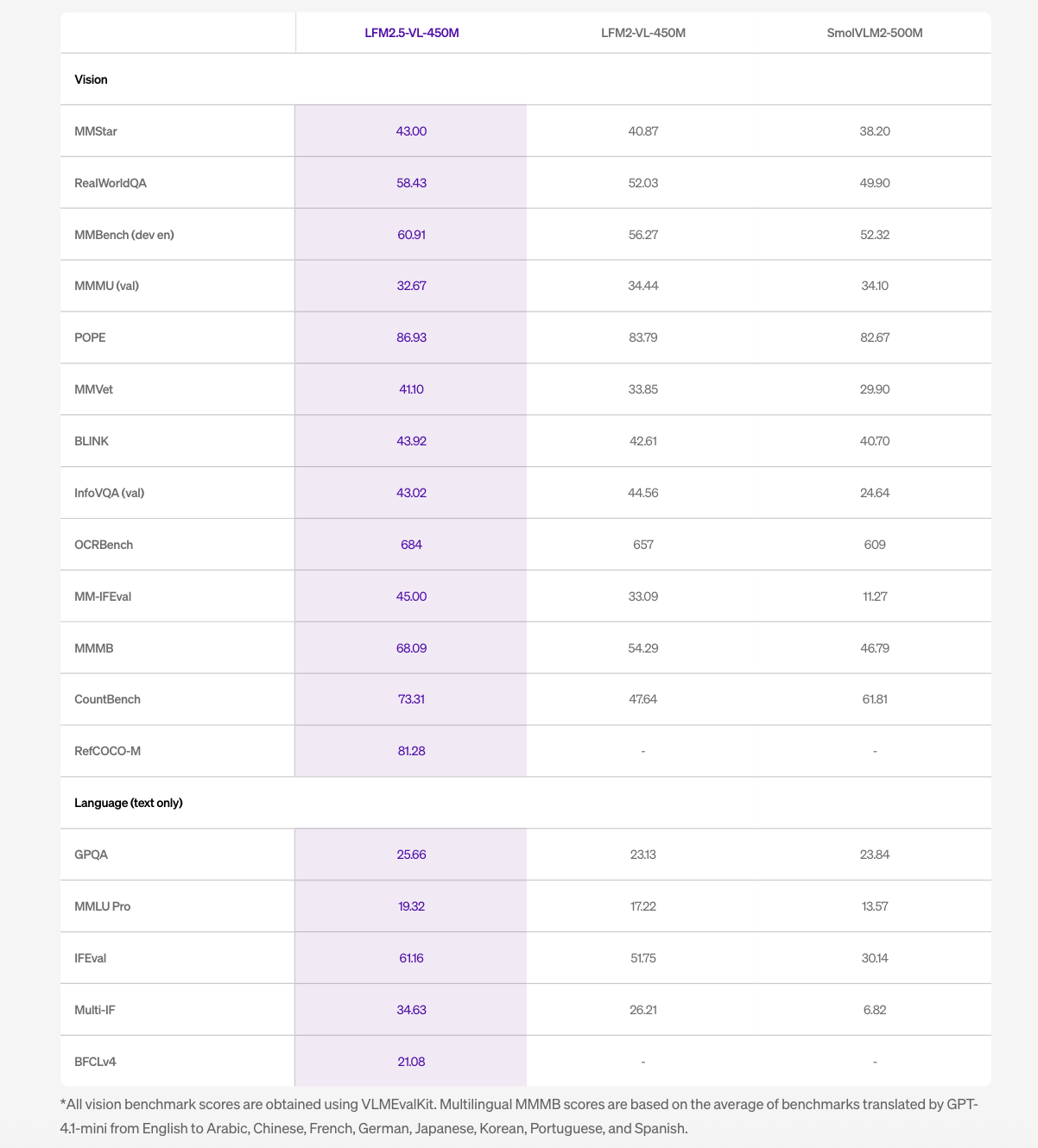
Essentially the most important addition is bounding field prediction. LFM2.5-VL-450M scored 81.28 on RefCOCO-M, up from zero on the earlier mannequin. RefCOCO-M is a visible grounding benchmark that measures how precisely a mannequin can find an object in a picture given a pure language description. In observe, the mannequin outputs structured JSON with normalized coordinates figuring out the place objects are in a scene — not simply describing what’s there, but additionally finding it. That is meaningfully completely different from pure picture captioning and makes the mannequin immediately usable in pipelines that want spatial outputs.
Multilingual help additionally improved considerably. MMMB scores improved from 54.29 to 68.09, overlaying Arabic, Chinese language, French, German, Japanese, Korean, Portuguese, and Spanish. That is related for world deployments the place local-language prompts have to be understood alongside visible inputs, without having separate localization pipelines.
Instruction following improved as nicely. MM-IFEval scores went from 32.93 to 45.00, which means the mannequin extra reliably adheres to specific constraints given in a immediate — for instance, responding in a selected format or proscribing output to particular fields.
Perform calling help for text-only enter was additionally added, measured by BFCLv4 at 21.08, a functionality the earlier mannequin didn’t embody. Perform calling permits the mannequin for use in agentic pipelines the place it must invoke exterior instruments — as an illustration, calling a climate API or triggering an motion in a downstream system.
Benchmark Efficiency
Throughout imaginative and prescient benchmarks evaluated utilizing VLMEvalKit, LFM2.5-VL-450M outperforms each LFM2-VL-450M and SmolVLM2-500M on most duties. Notable scores embody 86.93 on POPE, 684 on OCRBench, 60.91 on MMBench (dev en), and 58.43 on RealWorldQA.
Two benchmark good points stand out past the headline numbers. MMVet — which exams extra open-ended visible understanding — improved from 33.85 to 41.10, a considerable relative acquire. CountBench, which evaluates the mannequin’s capability to depend objects in a scene, improved from 47.64 to 73.31, one of many largest relative enhancements within the desk. InfoVQA held roughly flat at 43.02 versus 44.56 on the prior mannequin.
On language-only benchmarks, IFEval improved from 51.75 to 61.16 and Multi-IF from 26.21 to 34.63. The mannequin doesn’t outperform on all duties — MMMU (val) dropped barely from 34.44 to 32.67 — and Liquid AI notes the mannequin shouldn’t be well-suited for knowledge-intensive duties or fine-grained OCR.
Edge Inference Efficiency
LFM2.5-VL-450M with Q4_0 quantization runs throughout the total vary of goal {hardware}, from embedded AI modules like Jetson Orin to mini-PC APUs like Ryzen AI Max+ 395 to flagship cellphone SoCs like Snapdragon 8 Elite.
The latency numbers inform a transparent story. On Jetson Orin, the mannequin processes a 256×256 picture in 233ms and a 512×512 picture in 242ms — staying nicely beneath 250ms at each resolutions. This makes it quick sufficient to course of each body in a 4 FPS video stream with full vision-language understanding, not simply detection. On Samsung S25 Extremely, latency is 950ms for 256×256 and a couple of.4 seconds for 512×512. On AMD Ryzen AI Max+ 395, it’s 637ms for 256×256 and 944ms for 512×512 — beneath one second for the smaller decision on each client gadgets, which retains interactive functions responsive.
Actual-World Use Circumstances
LFM2.5-VL-450M is particularly nicely suited to real-world deployments the place low latency, compact structured outputs, and environment friendly semantic reasoning matter most, together with settings the place offline operation or on-device processing is necessary for privateness.
In industrial automation, compute-constrained environments reminiscent of passenger autos, agricultural equipment, and warehouses usually restrict notion fashions to bounding-box outputs. LFM2.5-VL-450M goes additional, offering grounded scene understanding in a single move — enabling richer outputs for settings like warehouse aisles, together with employee actions, forklift motion, and stock circulation — whereas nonetheless becoming current edge {hardware} like a Jetson Orin.
For wearables and always-on monitoring, gadgets reminiscent of sensible glasses, body-worn assistants, dashcams, and safety or industrial screens can’t afford giant notion stacks or fixed cloud streaming. An environment friendly VLM can produce compact semantic outputs domestically, turning uncooked video into helpful structured understanding whereas preserving compute calls for low and preserving privateness.
In retail and e-commerce, duties like catalog ingestion, visible search, product matching, and shelf compliance require greater than object detection, however richer visible understanding is commonly too costly to deploy at scale. LFM2.5-VL-450M makes structured visible reasoning sensible for these workloads.
Key Takeaways
- LFM2.5-VL-450M provides bounding field prediction for the primary time, scoring 81.28 on RefCOCO-M versus zero on the earlier mannequin, enabling the mannequin to output structured spatial coordinates for detected objects — not simply describe what it sees.
- Pre-training was scaled from 10T to 28T tokens, mixed with post-training through choice optimization and reinforcement studying, driving constant benchmark good points throughout imaginative and prescient and language duties over LFM2-VL-450M.
- The mannequin runs on edge {hardware} with sub-250ms latency, processing a 512×512 picture in 242ms on NVIDIA Jetson Orin with Q4_0 quantization — quick sufficient for full vision-language understanding on each body of a 4 FPS video stream with out cloud offloading.
- Multilingual visible understanding improved considerably, with MMMB scores rising from 54.29 to 68.09 throughout Arabic, Chinese language, French, German, Japanese, Korean, Portuguese, and Spanish, making the mannequin viable for world deployments with out separate localization fashions.
Take a look at the Technical particulars and Mannequin Weight. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as nicely.
Have to accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so forth.? Join with us