



# Introduction
A simple search on Hugging Face pulls up more than 90,000 text-to-image models. That figure gives you a sense of the scale — it’s not a curated shortlist. Many people looking for a free AI image generator default to Midjourney or DALL-E, not realizing that Hugging Face actually hosts the very models that power those platforms — identical architectures, sometimes even the same weights — accessible at no cost through browser-based Spaces demos or available to download and run on your own machine.
This guide narrows down those 90,000+ options to seven models that are genuinely worth exploring in 2026. The picks were made based on output quality that holds up against paid alternatives, truly free access (either in-browser or as a download), ongoing maintenance, and practical value for users of varying experience levels. For each model, you’ll find the Hugging Face link, the license and what it actually allows, what the model excels at, and a candid look at its limitations.
# How to Get Started with Hugging Face for Image Generation
Before diving in, it helps to know that Hugging Face offers two main ways to generate images, and each one fits a different type of user.
- Hugging Face Spaces are free, browser-based demos. You navigate to the Space URL, enter a prompt, and receive an image — no GPU needed, no software installation, no API key, and no account required for most of them. During busy periods, some models may have a short wait in a queue, but the better-maintained Spaces run on dedicated hardware and deliver results quickly. This is the ideal starting point for casual exploration, one-off image creation, and testing a model’s capabilities before investing time in a more involved setup. Every model featured in this article has a linked Space so you can try it out right away.
- Downloading the model weights and running them locally using the diffusers Python library, ComfyUI, or Forge gives you unlimited generation with no queues, complete control over settings, and full privacy — nothing is sent off your machine. This approach requires a compatible GPU (VRAM requirements are noted for each model in its respective entry below) and a working Python environment.
# 1. FLUX.1 Schnell
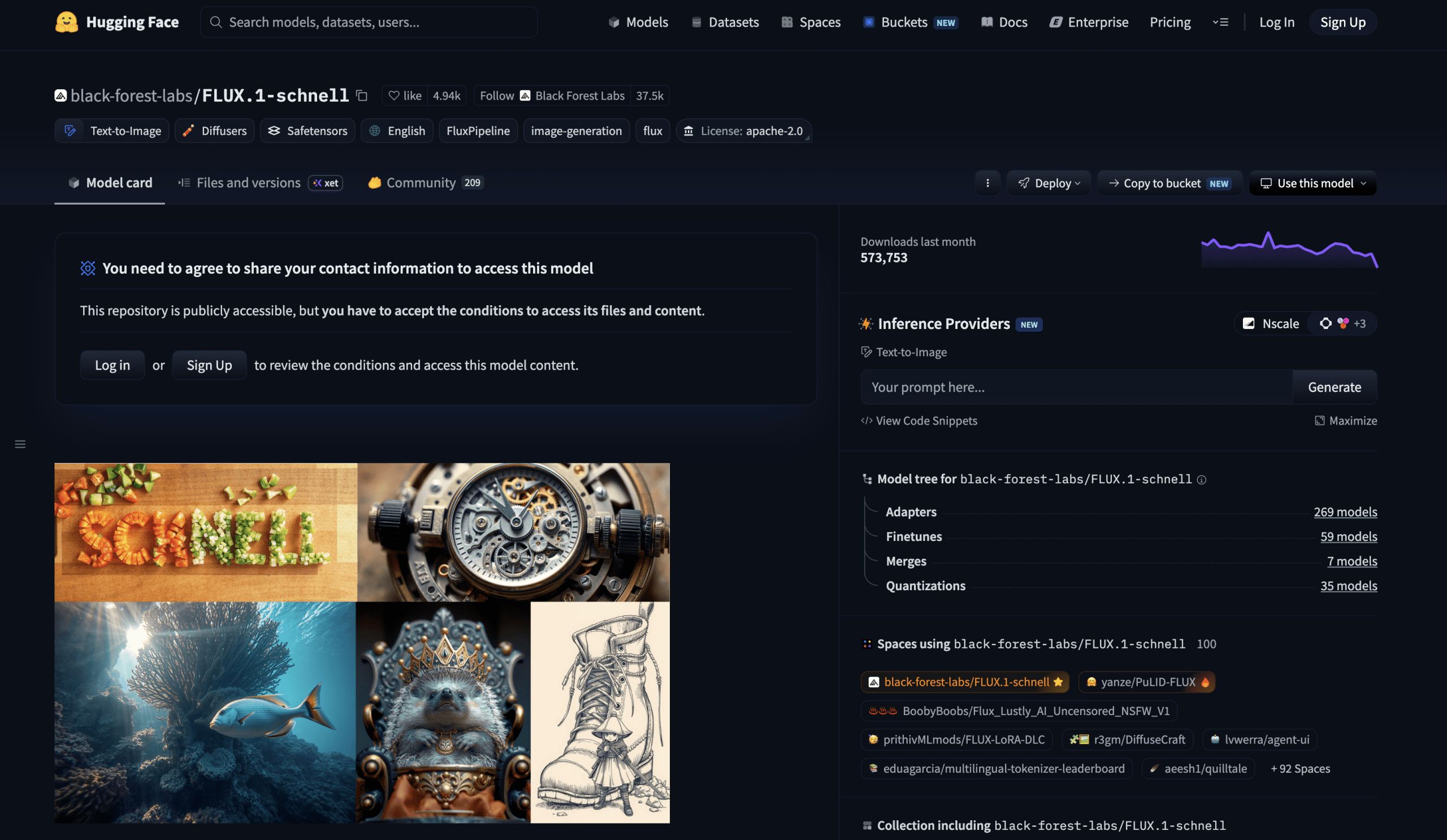
FLUX.1 Schnell Dashboard
| Field | Detail |
|---|---|
| Developer | Black Forest Labs |
| License | Apache 2.0 — personal, scientific, and commercial use |
| Parameters | 12B |
| Architecture | Rectified flow transformer |
| VRAM (local) | ~16 GB (or ~10 GB with CPU offload enabled) |
| Best for | Fast generation, commercial use, building apps |
FLUX.1 Schnell is released under the Apache 2.0 license, which means it’s free to use for personal, scientific, and commercial projects. That single detail sets it apart from every other top-tier model on this list. Apache 2.0 is about as permissive as open-source licenses come — you can build a product around it, sell it commercially, plug it into a workflow, and do all of that without negotiating a license or paying any fees.
Schnell was trained using guidance distillation to produce images in just 1–4 inference steps, compared to the 20–50 steps that traditional diffusion models typically need. The quality it delivers per step is outstanding. It isn’t the highest-quality model that Black Forest Labs offers — that title belongs to FLUX.1 Dev or FLUX.2 — but its output surpasses most models from a year ago, and it generates images at a speed that feels genuinely fast even on consumer-grade hardware.
Where it falls short: scenes that demand the absolute highest level of photorealistic detail above all else. For those cases, FLUX.1 Dev offers a higher quality ceiling, though it doesn’t come with the same Apache 2.0 commercial freedom.
# 2. FLUX.1 Dev
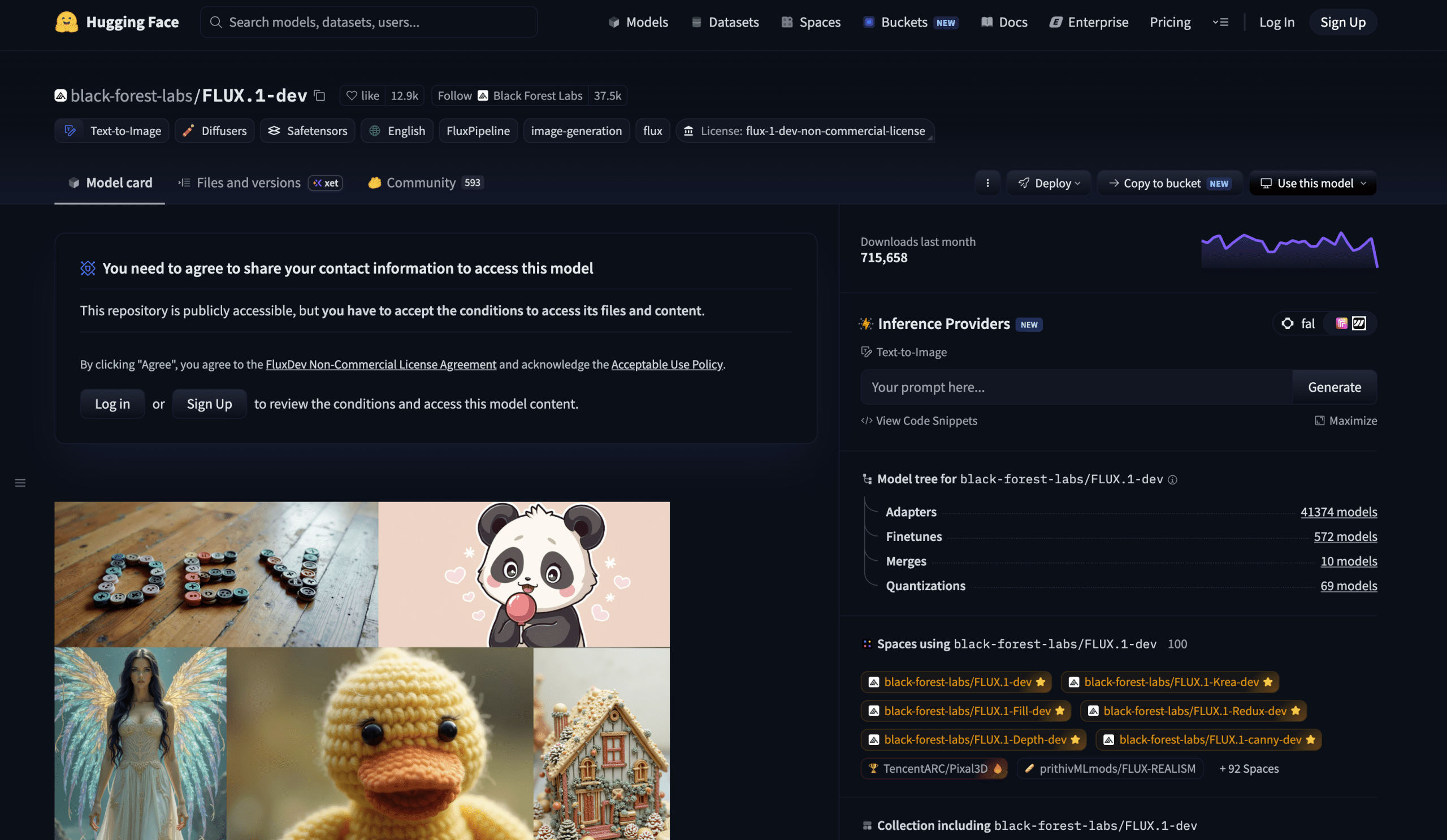
FLUX.1 Dev Dashboard | Image by Author
| Field | Detail |
|---|---|
| Developer | Black Forest Labs |
| License | FLUX.1 Dev Non-Commercial License |
| Parameters | 12B |
| Architecture | Rectified flow transformer |
| VRAM (local) | ~24 GB recommended |
| Best for | Research, artistic projects, high-quality personal use |
FLUX.1 Dev is a 12-billion-parameter rectified flow transformer. It was distilled directly from FLUX.1 Pro, achieving comparable quality and prompt-following ability while being more efficient than a standard model of the same size. For non-commercial purposes, it’s currently the highest-quality freely available model on the platform.
The photorealism it produces in portrait and product photography prompts is in a completely different league compared to what other free tools deliver. Portrait consistency, fine fabric textures, architectural details, and text rendering within images are all noticeably better than the earlier-generation models it has displaced as the community standard.
License clarity matters here. The model weights themselves are restricted to non-commercial use — you can’t take the model and build a paid product on top of it without reaching out to Black Forest Labs. However, the images you generate with FLUX.1 Dev can be used for personal, scientific, and commercial purposes as outlined in the license. The distinction is important: using the model to generate images for your own commercial
The ability to get things done is generally assumed. Deploying the model as the core engine powering a commercial offering or API calls for a separate arrangement with Black Forest Labs.
# 3. FLUX.1 Kontext Dev
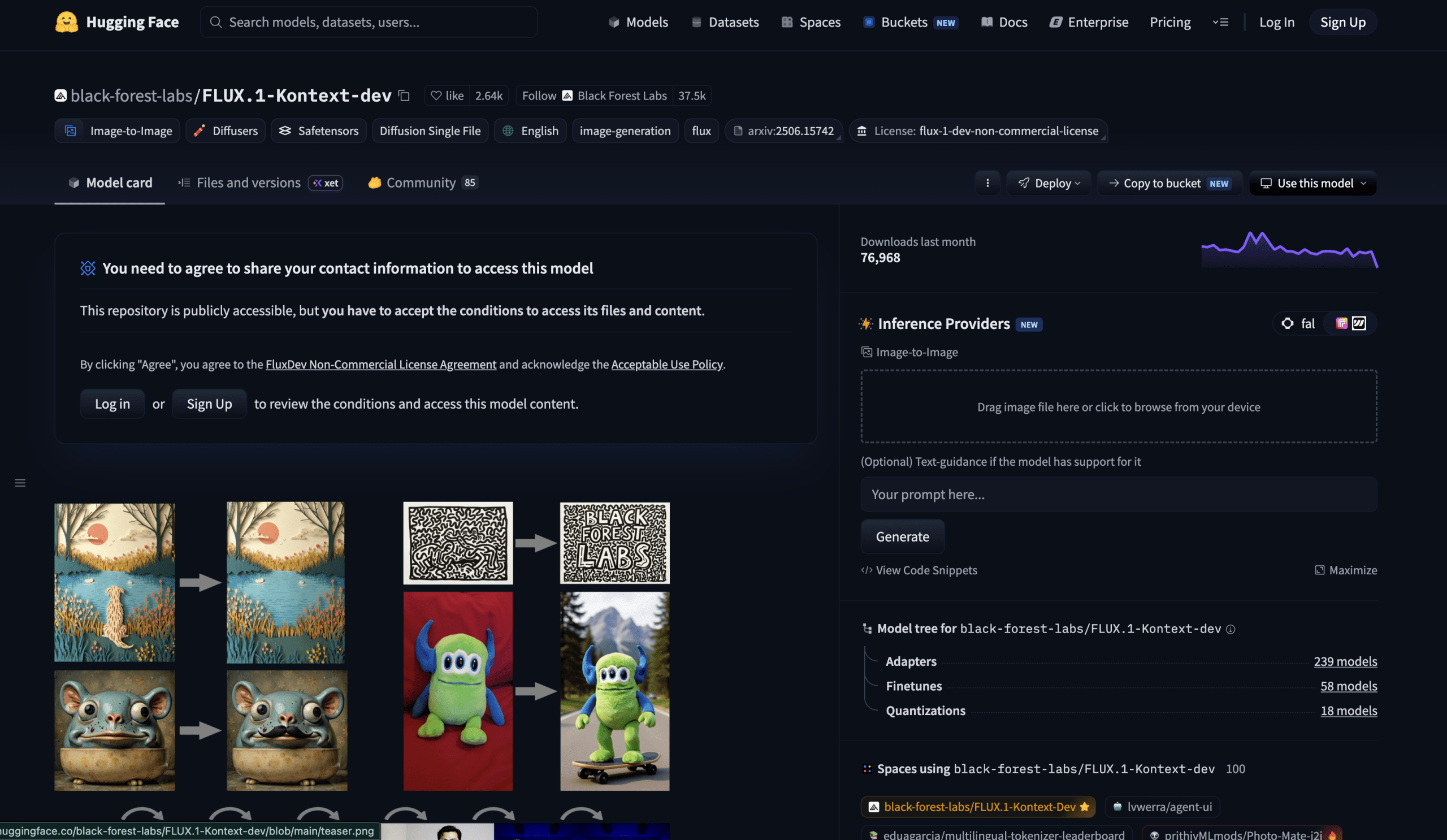
FLUX.1 Kontext Dev Dashboard | Image by Author
| Field | Detail |
|---|---|
| Developer | Black Forest Labs |
| License | FLUX.1 Dev Non-Commercial License |
| Parameters | 12B |
| Released | May 2025 |
| Architecture | Rectified flow transformer with in-context conditioning |
| Best for | Image editing, character consistency, style transfer, iterative refinement |
Every other model on this list accepts a text prompt and produces images from nothing. FLUX.1 Kontext Dev works differently — it takes an existing image and modifies it according to written instructions.
FLUX.1 Kontext Dev can revise images based on text commands, supporting references to characters, styles, and subjects without requiring any fine-tuning. Strong consistency allows you to refine an image across several consecutive edits with minimal quality degradation. That final capability is the real technical challenge. Most image editing models suffer from visual drift — after three successive modifications, a character can end up looking like an entirely different person. Kontext preserves identity across repeated edits with a level of stability that no open-source model had achieved before this architecture.
The real-world benefit this enables: create a character, product, or scene once, then keep adjusting — “put sunglasses on them,” “change the background to a sunset over mountains,” “switch the jacket to red,” “add motion blur” — and the core visual identity remains consistent throughout the entire sequence. For product photography, character design, and any iterative creative pipeline, this represents a fundamental leap in what free open-source tools are capable of delivering.
The Space demo is intuitive: upload an image, type your instruction, tweak guidance strength and seed. The interface at huggingface.co/spaces/black-forest-labs/FLUX.1-Kontext-Dev also supports image-to-image generation without requiring a source image for pure text-to-image use.
# 4. Stable Diffusion 3.5 Large

Stable Diffusion 3.5 Large Dashboard | Image by Author
| Field | Detail |
|---|---|
| Developer | Stability AI |
| License | Stability AI Community License (permissive for most uses) |
| Parameters | 8B |
| Architecture | Multimodal diffusion transformer (MMDiT) |
| VRAM (local) | ~10–16 GB |
| Best for | Community fine-tunes, ControlNets, broad customization |
Stable Diffusion 3.5 carries a permissive community license, offers extensive customization options, operates on consumer-grade hardware, and ships with complete inference code available on GitHub. But the license terms and download metrics are not the primary reasons this model made the list.
The real reason SD 3.5 matters is the ecosystem surrounding it. Thousands of fine-tuned models on Hugging Face, hundreds of LoRAs trained on specific artistic styles and subjects, ControlNet variants for guided generation (canny edges, depth maps, pose control), and a toolchain ecosystem — AUTOMATIC1111, ComfyUI, and Forge — that has been developed and polished over the course of years. No other model architecture yet has that level of community-driven infrastructure.
SD 3.5 Medium is also worth highlighting: the smaller variant fits more easily on 8–10 GB VRAM and generates faster, trading peak image quality for broader accessibility. Both variants are free. For anyone looking to train a model on their own data, build custom ControlNet workflows, or tap into the widest library of community art styles, Stable Diffusion 3.5 is the architecture to work with.
# 5. FLUX.2 Dev
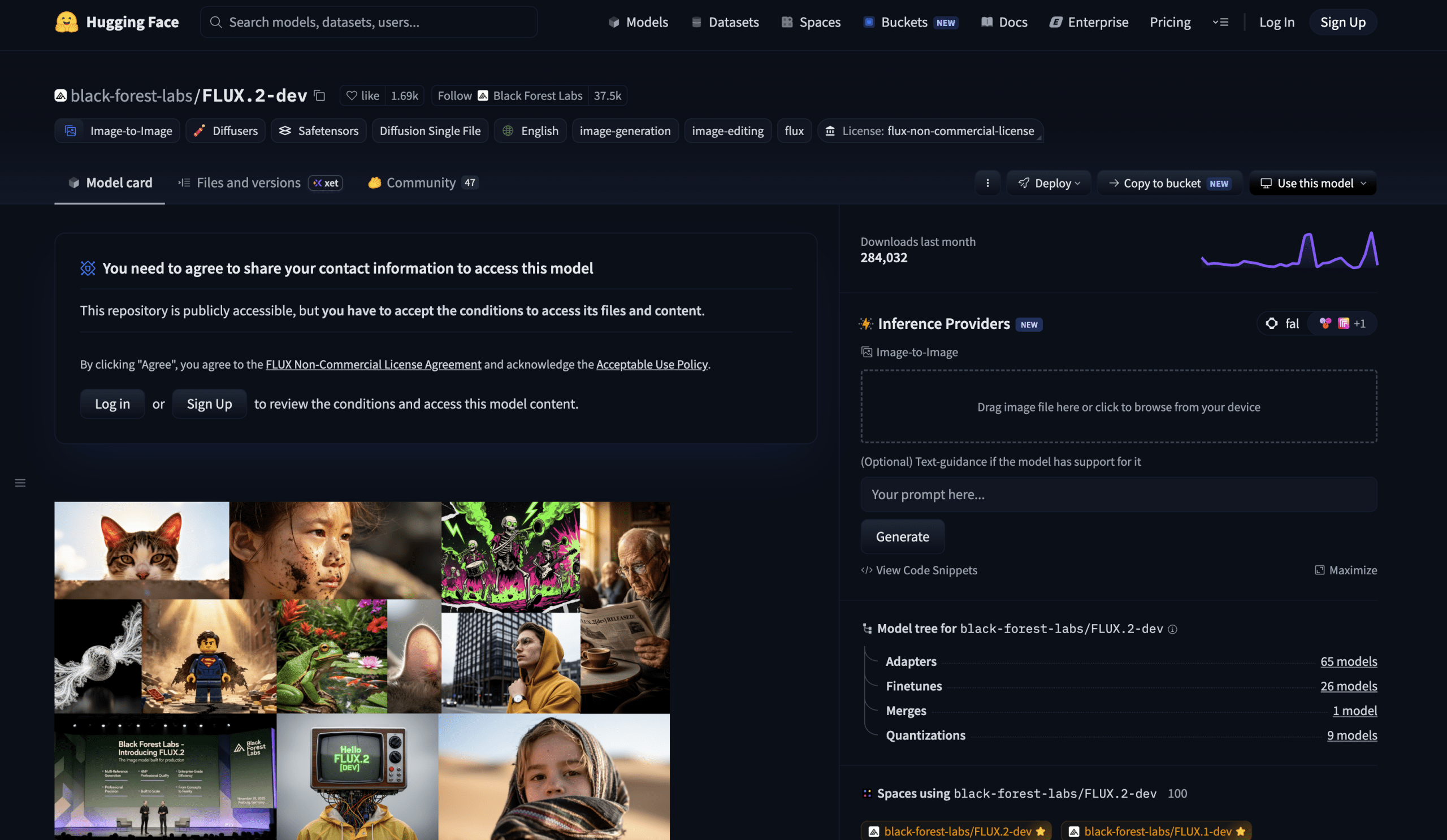
FLUX.2 Dev Dashboard | Image by Author
| Field | Detail |
|---|---|
| Developer | Black Forest Labs |
| License | FLUX.2-dev Non-Commercial; 4B variants = Apache 2.0 |
| Parameters | 32B (full dev); 4B (smaller variants) |
| Architecture | Improved DiT (Diffusion Transformer) backbone |
| Released | November 2025 |
| Best for |
Launched in November 2025 by Black Forest Labs, FLUX.2 represents a significant step forward — moving beyond experimental image generation into the realm of production-ready visual content. The 2026 version delivers native 4-megapixel resolution and features a substantially upgraded diffusion transformer (DiT) architecture. One of its most notable capabilities is native multi-reference support, meaning it can draw from several input images at once during the generation process.
The hardware demands are worth being upfront about. The full FLUX.2 Dev model needs significant VRAM — an H100-class GPU for the 32B parameter version. To make it more accessible, Black Forest Labs has teamed up with Hugging Face to offer quantized versions that can run on consumer-grade hardware, including setups using an RTX 4090 paired with a remote text encoder. For most developers without access to datacenter resources, the 4B variants under the Apache 2.0 license represent the practical starting point.
# 6. Playground v2.5

Playground v2.5 Dashboard | Image by Author
| Field | Detail |
|---|---|
| Developer | Playground AI |
| License | Playground v2.5 Community License |
| Resolution | 1024px native |
| Architecture | SDXL-based with CLIP-L + OpenCLIP-G text encoders |
| Best for | Artistic compositions, human-centric imagery, aesthetic-first generation |
Where FLUX models excel at photorealism and following prompts precisely, Playground v2.5 excels at something else entirely — creating outputs that feel like deliberate artistic choices rather than machine-generated images.
It was fine-tuned specifically for aesthetic quality: human figures with natural body proportions, compositions that adhere to established design principles, and color palettes that appear purposeful rather than random. If you need reference images for creative projects, mood boards, character designs, or any scenario where “looks stunning” is the top priority, Playground v2.5 consistently delivers results that are harder to tell apart from intentional design work than from a text-prompted generation.
The community license allows commercial use under certain conditions — be sure to review the full license on the model card before deploying in production. Since the model is built on SDXL infrastructure, it works seamlessly with the extensive ecosystem of SDXL fine-tunes and compatible tools.
# 7. Kolors

Kolors | Image by Author
| Field | Detail |
|---|---|
| Developer | Kuaishou Kolors Team |
| License | Apache 2.0 — fully free for commercial use |
| Training | Billions of text-image pairs |
| Architecture | Latent diffusion with GLM text encoder |
| Best for | Chinese-English bilingual content, text rendering in images, high photorealism |
Kolors is a large-scale text-to-image model trained on billions of text-image pairs. It demonstrates clear strengths in visual fidelity, accurate interpretation of complex prompts, and rendering legible text in both Chinese and English. It is powered by the General Language Model (GLM), which deepens its understanding of both languages.
The GLM backbone is what sets it apart. Most Western open-source models rely on T5 or CLIP as their text encoders — architectures that weren’t built with deep Chinese language comprehension in mind. Kolors was designed from the ground up with native Chinese-English bilingual support, which leads to noticeably better results when prompting in Chinese or creating content involving Chinese text, cultural references, or mixed-language scenes.
Its ability to render text within images is also particularly impressive. Producing readable text inside generated images has long been a weak spot for diffusion models. The Apache 2.0 license imposes no restrictions on commercial use. If your product or content targets Chinese-English audiences, this is the model that genuinely handles your needs — something most English-focused articles on this subject tend to overlook.
# Which Model Should You Use?
Picking the right model isn’t about finding the single “best” option — it’s about matching the tool to your specific requirements.
If you need Apache 2.0 commercial freedom along with fast generation speeds, FLUX.1 Schnell is the clear choice. It’s the only flagship-tier model that comes with completely unrestricted commercial rights.
If achieving the highest possible quality is your sole concern and you’re working on personal or research projects, FLUX.1 Dev delivers the best output per prompt among non-commercial models. The Space demo will quickly show you whether its quality level justifies the non-commercial license restrictions for your particular use case.
If your workflow centers on editing and refining existing images rather than creating from a blank canvas, FLUX.1 Kontext Dev is the model that makes that process practical without requiring fine-tuning.
If you want the richest ecosystem — fine-tunes, LoRAs, ControlNets, and compatible tooling — Stable Diffusion 3.5 is the foundation to build on. While newer models have surpassed it at the cutting edge in raw quality, nothing else matches its community infrastructure.
If your content targets Chinese-English bilingual audiences or requires legible text rendered within the generated image, Kolors — backed by its Apache 2.0 license — is the purpose-built solution that most English-centric coverage of this topic simply fails to mention.
# Conclusion
Hugging Face has established itself as the go-to platform for serious open-source image generation. The 90,000+ models available may sound daunting, but the ones that truly matter in 2026 can be counted on one hand — and every single one is free. The FLUX family from Black Forest Labs now spans the entire range — from fully commercial Apache 2.0 generation (Schnell) to non-commercial peak quality (Dev) to instruction-driven editing (Kontext). Stable Diffusion 3.5 remains the backbone of the community ecosystem that has been growing for three years. Kolors addresses the multilingual gap that Western-centric models leave behind.
All seven models have browser-based Spaces you can try right now with no installation required. Begin with the Space URL for each model before investing time in a local setup. Within five prompts, you’ll have a clear sense of whether a model’s output style aligns with what you’re trying to create.
Shittu Olumide is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.