



In brief
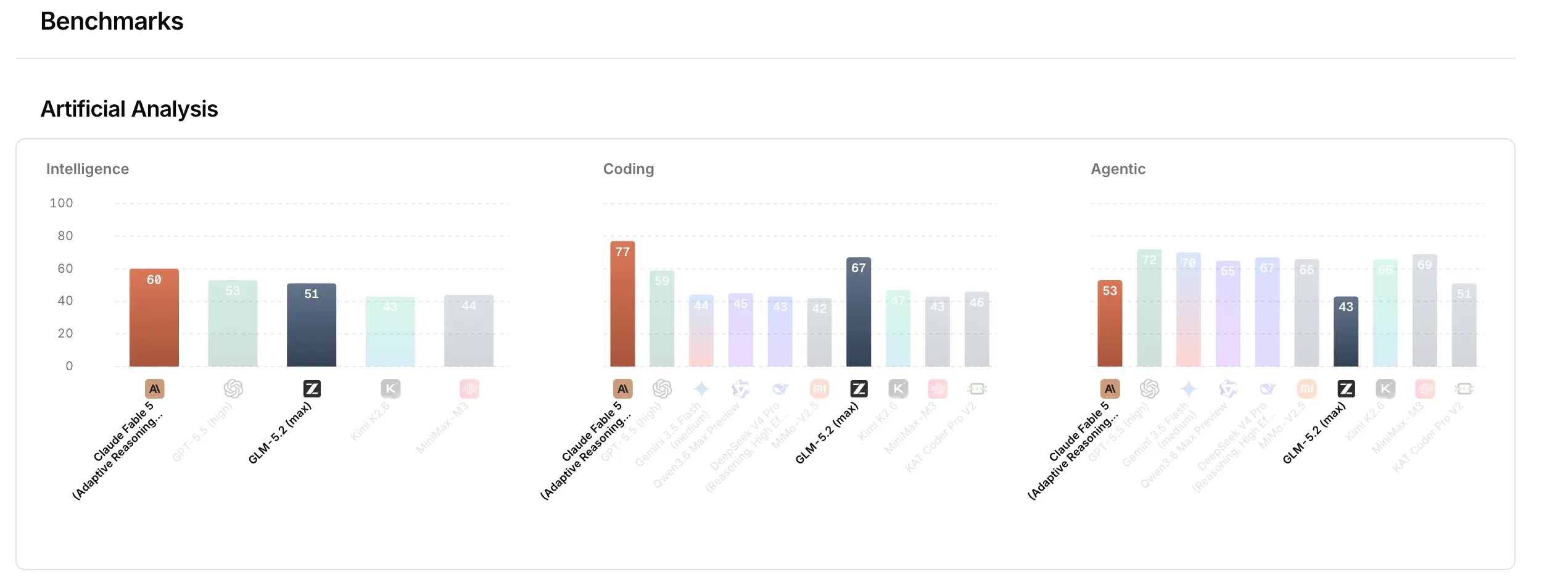
- GLM-5.2 falls just 1% behind Claude Opus 4.8 on FrontierSWE—a benchmark that gauges multi-hour, self-directed engineering tasks—while outperforming GPT-5.5 on the same evaluation. It’s released under an MIT license with no geographic limitations.
- The entire model was trained exclusively on Huawei Ascend processors, with no reliance on NVIDIA hardware whatsoever.
- Unsloth AI has already published 2-bit GGUF quantizations that compress the model from 1.51TB down to 238GB. You’ll still need 256GB of RAM or VRAM—but once you have that, you can actually run it.
Z.ai launched GLM-5.2 on June 16, pledging top-tier performance that surpasses its already capable GLM 5.1.
The Beijing-based research lab, which was added to the U.S. Entity List in January 2025, seems to be capitalizing on mounting unease around America’s AI strategy. Over the past week, the ban on Anthropic’s Claude Fable and the debut of this new model have helped push zAI’s stock up 90%, reaching a record high.
GLM 5.2 has the benchmarks to justify the excitement.
On FrontierSWE—a benchmark that tests whether an AI agent can tackle open-ended, hours-long technical projects spanning systems optimization, large-scale code development, and applied ML research, measured by dominance rate—GLM-5.2 scored 74.4 compared to Claude Opus 4.8’s 75.1. It narrowly beat GPT-5.5, which came in at 72.6. On SWE-bench Pro, which evaluates the autonomous resolution of real-world GitHub issues measured as a pass rate, GLM-5.2 posted 62.1 versus GPT-5.5’s 58.6—and significantly outpaced its predecessor GLM-5.1’s 58.4.
The leap in quality makes it the strongest open-source model to date on the Artificial Analysis Intelligence Index, which combines results from 9 different benchmarks to evaluate the overall capability of an AI model. OpenRouter’s benchmarks place it in the same league as the now-banned Claude Fable 5.
The hardware behind this achievement is another fascinating piece of the puzzle. GLM-5.2 was trained entirely on Huawei Ascend chips—with no Nvidia hardware involved at any stage. Emad Mostaque, the founder of Stability AI, pegged the total training cost at roughly $25 million, with 80% of that spent on post-training. That makes it remarkably affordable compared to similar models.
As Decrypt reported earlier this year, Z.ai had already been training image models on Huawei’s Ascend Atlas servers without relying on a single American chip. GLM-5.2 pushes that infrastructure even further—a 744-billion-parameter mixture-of-experts model boasting a true 1 million-token context window, which is five times the 200K cap on GLM-5.1, all released under an MIT license that ensures no government mandate can suddenly revoke access.
Tokens are the segments of text a model can read and produce, while Parameters refer to the internal configurations and values that shape how a model processes information and generates its outputs.
Who it’s for and what it costs
For developers, the context window represents a game-changing improvement. Tasks like navigating entire codebases, refactoring across multiple files, and running long agentic workflows—which previously needed to be broken into smaller pieces—can now be handled in a single API call. API pricing comes in at $1.40 per million input tokens and $4.40 per million output tokens, compared to Claude Opus 4.8’s $5 input and $25 output rates. The Coding Plan starts at approximately $18 per month and integrates directly with Claude Code, Cline, Kilo Code, and most popular agentic development environments.
Running the model locally is also a technical possibility. Unsloth AI released 2-bit GGUF quantizations that shrink the model from 1.51TB down to just 238GB while preserving around 82% of its accuracy.
Hold off on the excitement, though. That still means you’d need 256GB of unified memory or an equivalent RAM/VRAM setup—think a maxed-out M4 Ultra Mac Studio or a workstation with a mid-range GPU paired with 256GB of system RAM using mixture-of-experts offloading. It’s still a significant investment, but at least it’s something you could realistically purchase and run at home if you’re determined enough.
We ran a quick test by asking GLM-5.2 to build our standard game combining typing mechanics with a shooter. The interface wasn’t the most visually polished—other models produced sleeker-looking UIs—but the gameplay experience was the most diverse: different scenarios across waves, shifting enemy types, and bosses showing up later in the run.
It generated a wider variety of game states than anything else we tested for the same task in a zero-shot configuration.
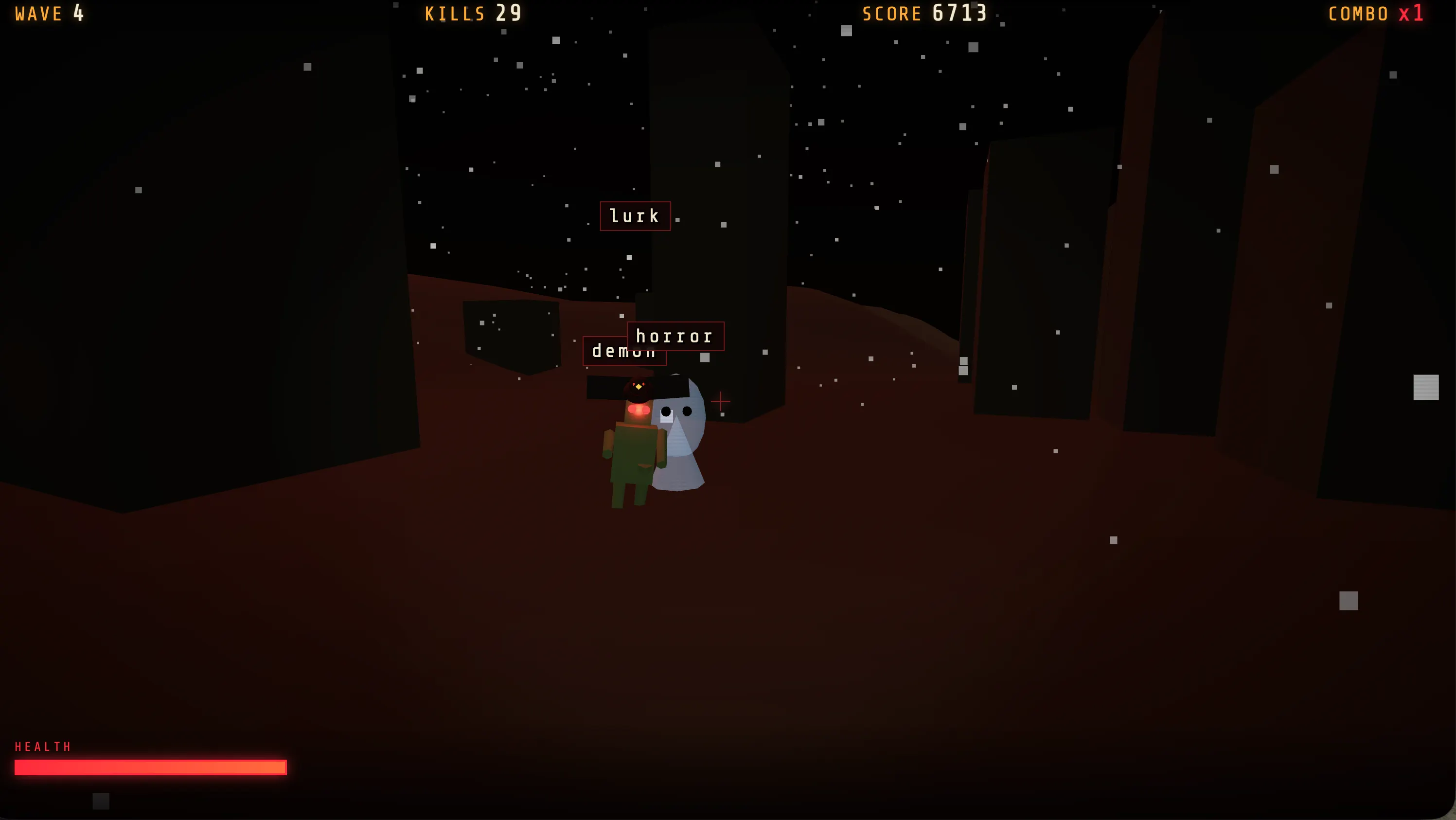
If you’re eager to try it out, it’s already available on our Itch.io page.
That difference highlights where GLM-5.2 delivers the best value for money. For batch generation setups and agent-driven workflows where variety matters more than refinement, the numbers at open-source pricing are tough to beat. For the most demanding long-haul tasks—SWE-Marathon, where it earns 13.0 versus Opus 4.8’s 26.0—the distance from the top-tier proprietary models remains significant, a full 13 points apart.
The open-source model weights are up on HuggingFace under the MIT license. Quantized versions are there as well. GLM Coding Plan users can swap to it right away using the model identifier GLM-5.2, and it’s also free to test on z.AI within certain usage limits.
Daily Debrief Newsletter
Kick off your mornings with the biggest stories of the day, along with exclusive features, a podcast, videos, and plenty more.