



Miso Labs has officially released MisoTTS, an open-weights text-to-speech model with 8 billion parameters that can generate expressive, natural-sounding speech by drawing from both text input and prior audio context. At the heart of its design is residual vector quantization (RVQ), a technique that dramatically widens the model’s sonic range without inflating its parameter count—avoiding the need to scale up a single flat vocabulary while keeping the network size fixed.
Introducing MisoTTS
MisoTTS is an 8-billion-parameter text-to-speech Transformer built around residual vector quantization, drawing direct inspiration from the Sesame CSM architecture. It pairs a Llama 3.2-style backbone with a compact audio decoder. The model generates Mimi-encoded audio codes from text and, optionally, from prior audio segments. By conditioning on both text and preceding speech, it can adapt to a speaker’s tone and vocal qualities during a conversation.
The text input vocabulary spans 128,256 tokens, and the audio side uses 32 separate codebooks powered by the Mimi audio tokenizer. The maximum supported sequence length is 2,048 tokens, and default inference runs in torch.bfloat16 precision.
Miso Labs reports a latency of just 110ms—significantly faster than the 700ms listed for ElevenLabs and the 300ms for Sesame in comparable benchmarks.
The Challenge of Vocabulary Scaling
Standard Transformer models generate output from a fixed vocabulary of discrete tokens. This assumption holds well when a relatively small vocabulary adequately represents the target domain. Human speech, however, defies this simplification—it varies continuously across dimensions like pitch, rhythm, emphasis, emotion, and accent.
The most straightforward remedy would be to simply expand the audio token vocabulary. But in a conventional Transformer, larger vocabularies demand proportionally more parameters, since each token must be explicitly represented and independently predicted by the model. Miso Labs refers to this as the vocabulary size problem.
A second, related limitation is conditioning. Most existing TTS systems condition only on text, completely ignoring the interlocutor’s tone and speaking style. Miso Labs argues that this omission is a key factor behind the unsettling “uncanny valley” effect that plagues many synthetic voices.
Residual Vector Quantization at the Core
MisoTTS tackles both of these challenges using residual vector quantization (RVQ). Miso Labs traces RVQ’s conceptual roots to research in image generation, noting its subsequent adoption in Sesame’s CSM architecture for audio tasks. Rather than selecting a single token index per audio frame, the model emits a multi-dimensional vector of indices.
Each audio token is represented by 32 codebook indices drawn from 2,048-entry codebooks. The model maintains a distinct codebook for each vector position. During decoding, the looked-up vectors from all positions are summed together, with each successive codebook adding progressively finer refinement to the reconstructed signal.
This layered design is what makes efficient scaling possible. The effective vocabulary size equals the codebook size raised to the vector depth. Crucially, increasing the depth adds zero new parameters to the model. As a result, MisoTTS can address roughly 204832—approximately 10105—unique tokens. Miso Labs points out that achieving comparable coverage through naïve vocabulary scaling would require a vastly larger network.
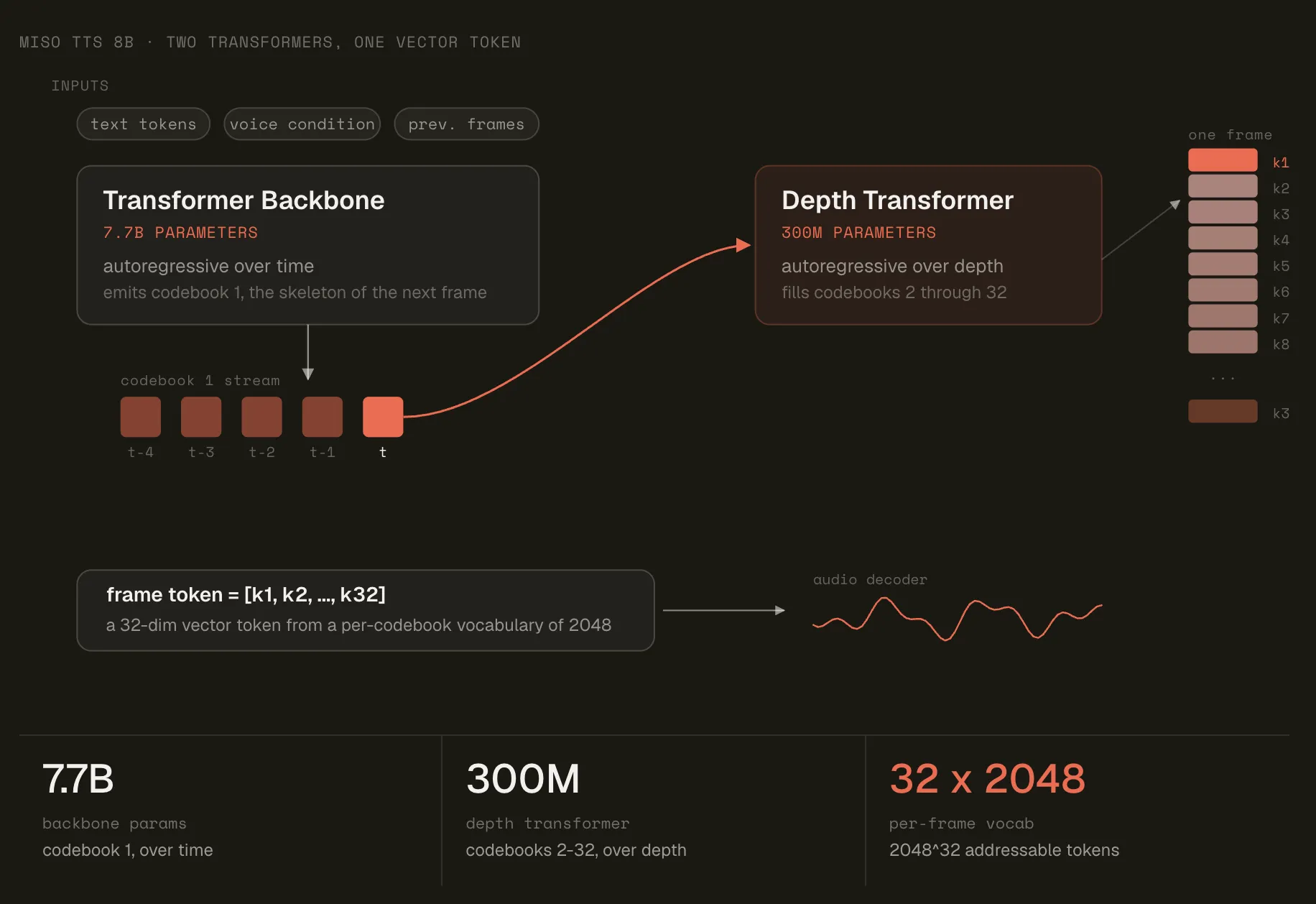
A Two-Stage Transformer Design
The architecture is split into two components: a backbone and a decoder. The backbone is a 7.7-billion-parameter Transformer that operates autoregressively over time, predicting the first codebook index along with a final hidden state for each frame.
A separate 300-million-parameter decoder then runs autoregressively across the depth dimension, predicting the remaining codebook indices one position at a time. Each prediction is conditioned on all previously selected indices within the same frame. The same 300M parameters are shared and reused across every depth position.
Embedding construction follows the same principle. Text tokens use a standard single lookup table. An audio token’s embedding, by contrast, is formed by summing the per-position codebook lookups across all 32 indices. Interleaving text and audio tokens allows the backbone to process full conversation
Strengths and Challenges
Strengths:
- Released as open weights from day one, under a modified MIT license.
- RVQ expands the range of sounds without increasing the number of parameters.
- Uses audio context for conditioning, not just text.
- Local deployment ensures sensitive audio data stays on-premises.
- The architecture and underlying math are explained in a public blog post.
Challenges:
- Supports half-duplex communication only, with no turn-taking capability yet.
- The larger model requires a powerful CUDA-enabled GPU.
- API access has been announced but is not yet live.
- Claims about latency and quality still need independent third-party validation.
Marktechpost’s Visual Explainer
Marktechpost · Model Brief
01 / 09
Key Takeaways
- Miso Labs open-sourced MisoTTS, an 8B text-to-speech model, under a modified MIT license.
- It conditions on both text and audio context, making generations responsive to speaker tone.
- Residual vector quantization (32 codebooks × 2048-way) scales vocabulary to ~2048³² without adding parameters.
- Architecture splits a 7.7B backbone (over time) and a 300M decoder (over depth).
- It is half-duplex and single-turn only today; API access is still pending.
Check out the Model Weights, Repo and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and subscribe to our Newsletter. Wait! Are you on Telegram? Now you can join us on Telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us