# Thinking
The user wants me to paraphrase an HTML article about X-Token, a cross-tokenizer knowledge distillation method. I need to:
1. Keep the HTML structure intact
2. Rewrite the text to be easier to read and understand
3. Keep it in English
Let me go through each section carefully and rephrase while keeping all HTML tags, classes, heading structure, math formulas, and code formatting.
Key points to preserve:
– All HTML tags and attributes
– Mathematical notation
– Technical accuracy
– The overall meaning and detail
Let me work through this paragraph by paragraph.
# Final Answer
Knowledge distillation (KD) is a technique for transferring what’s known as “dark knowledge” from a large teacher model to a compact student model. Rather than simply learning from the correct answers alone, the student picks up patterns from the teacher’s full probability distribution across all possible output tokens at each position. This is achieved using per-position Kullback–Leibler (KL) divergence to compare the two models’ next-token probability distributions.
A key limitation of this standard approach is that both models must share the same tokenizer. Someone working with Llama-3.2-1B as the student model is locked out from using more powerful teacher models that have incompatible vocabularies — like Phi-4-mini or Qwen3-4B — because token positions don’t line up across different vocabulary schemes. This also makes it impossible to leverage multiple teacher models from different tokenizer families simultaneously.
Researchers at NVIDIA have proposed X-Token, a logit-distribution approach to cross-tokenizer knowledge distillation. It serves as a direct plug-and-play substitute for conventional KD loss functions, with no need for extra trainable parameters or architecture modifications.
The Problem X-Token is Solving
Two existing methods lead the field in cross-tokenizer KD. ULD (Universal Logit Distillation) avoids vocabulary alignment problems altogether by rank-ordering both distributions and computing L1 distance between them, completely ignoring which specific tokens are involved. GOLD takes a more nuanced approach with a span-matching and hybrid-loss strategy. It divides tokens into two groups: a 1-to-1 string-matching common subset trained with KL divergence, and the leftover uncommon tokens trained with ULD-style rank ordering. GOLD currently represents the best-performing method available.
The research team pinpoints two fundamental shortcomings in GOLD’s design:
Shortcoming 1: Uncommon-token degradation — When tokenizers break up text in different ways, important tokens end up in the unmatched uncommon pool. Llama-3 groups multi-digit numbers as single tokens — for instance, “201” is one unit. Qwen3 splits them into individual digits: “2”, “0”, “1”. Under GOLD’s framework, all 1,100 of Llama’s two- and three-digit number tokens (100 two-digit and 1,000 three-digit) end up classified as uncommon when using Qwen3-4B as the teacher. These tokens get hit with two kinds of damaging guidance: noise from the identity-blind rank-based ULD matching, and suppressing gradient signals from the common-token KL term propagating through the full-vocabulary softmax layer. The outcome is severe: GSM8k accuracy plummets to 2.56 with GOLD using Qwen3-4B as teacher, whereas same-tokenizer KD with a weaker Llama-3.2-3B teacher still reaches 12.89.
Shortcoming 2: Strict matching that throws away useful signals — GOLD relies on exact string equality to build its common subset. A student token like Hundreds can map cleanly to teacher tokens Hund followed by reds when the text is re-tokenized through the tokenizer, but GOLD’s rigid matching rule rejects this correspondence and discards the alignment signal, even though it’s perfectly valid.
Fixing these two issues demands conflicting adjustments: you need to remove the partition when essential tokens are misaligned, but also relax it when the underlying alignment is logically sound.
How X-Token Works
The X-Token framework is built on three core pieces: span alignment, a projection matrix W, and a pair of complementary loss functions — P-KL and H-KL.
Span Alignment
Because teacher and student tokenizers produce different-length token sequences for the same text, X-Token applies dynamic-programming (DP) span alignment. This groups tokens into aligned chunk pairs, where each pair decodes to the identical underlying substring. A chain-rule merge step then collapses per-token probabilities within each chunk into a single chunk-level distribution for use during distillation. The alignment is cached once per sequence, so it introduces no extra overhead during each training step.
The researchers also discovered a bug in the surface-substring alignment method used by TRL’s GOLD trainer. TRL accumulates decoded text buffers on each side and only flushes them when both buffers match as identical raw bytes. Even a single byte-level discrepancy — such as Llama-3 automatically prepending
The Projection Matrix W
Once spans are aligned, the teacher and student distributions still live over entirely different vocabularies. The projection matrix W ∈ ℝ|VS|×|VT| bridges this gap by mapping each student token to a weighted blend of corresponding teacher tokens.
W is built deterministically through two sequential passes:
Pass 1 (exact string match): For every student-token and teacher-token pair whose decoded text strings match after normalization, the entry W[s, t] is set to 1. The normalization step harmonizes space prefixes (Ġ, _, ␣), newline characters, byte-fallback tokens written as <0xHH>, and tokenizer-specific special tokens across different model families.
Pass 2 (multi-token rule): For any student token that didn’t find an exact match in Pass 1, its decoded text is re-tokenized using the teacher’s tokenizer. If the resulting token sequence has length 4 or fewer, exponentially-decaying weights are assigned: W[s, τᵢ] = β·γⁱ, using (β, γ) = (0.9, 0.1). For a length-2 span, the normalized weights become (0.909, 0.091). For length 3: (0.9009, 0.0901, 0.0090). For length 4: (0.9000, 0.0900, 0.0090, 0.0009). The first sub-token in a group receives the highest weight because it typically carries the bulk of the meaningful probability content — examples include “_inter” within [“_inter”, “national”] or “_20” within [“_20”, “24”].
Each row of W is trimmed down to its top-4 entries and then normalized. Since every row contains non-negative values that sum to 1, multiplying on the left by W⊤ preserves probability: if pS is any valid probability vector, then W⊤pS is also a valid probability vector over VT. W is computed once before training begins and can optionally be fine-tuned together with the student model under the P-KL loss.
P-KL: Tackling Erroneous and Suppressive Gradients
P-KL completely eliminates the common/uncommon token partition. It projects each student distribution p̂S(k) into the teacher’s vocabulary space through W:
It then computes the Kullback–Leibler divergence directly between the teacher and the projected student distributions.
$$frac{partial mathcal{L}_{text{common}}}{partial z_{j}} = p_{S}[j] cdot M_{mathcal{C}}(T)$$
No tokens are left unaccounted for, so the rank-based ULD noise is completely removed. The problem of suppressive gradients is also resolved: the projection channels the student’s probability for “201” directly onto the subset {2, 0, 1} in the teacher vocabulary through the mapping matrix **W**.
The researchers formally demonstrate (Proposition 1) that the common-KL component of the GOLD loss ensures non-negative gradients for every uncommon student logit. Specifically, for any uncommon logit $j$, the gradient is:
$$frac{partial mathcal{L}_{text{common}}}{partial z_{j}} = p_{S}[j] cdot M_{mathcal{C}}(T)$$
where $M_{mathcal{C}}(T)$ represents the teacher’s probability mass on the common subset. Under gradient descent, this always pushes $z_j$ downward—thereby suppressing the probability of every uncommon token, regardless of the ground-truth label.
### H-KL: Relaxing One-to-One Alignment
H-KL comes into play when the vocabulary partition is well-structured—meaning that key tokens are properly placed in the common subset. In such cases, GOLD’s direct KL divergence applied to identity-mapped pairs offers stronger supervision compared to P-KL’s projection-based approach, which distributes probability mass across multiple teacher tokens. The goal here is to improve the partitioning scheme by loosening the strict requirement that tokens be exact string matches.
H-KL keeps GOLD’s hybrid loss formulation but grows the common set **C** by leveraging **W**. For each student token $s$, it identifies the top-ranked teacher token $t^* = argmax_{t’ in V_T} W[s, t’]$ and includes the pair $(s, t^*)$ in $C$. Any exact matches are naturally retained since they receive a weight of 1.0 in **W**—the highest possible value. Pairs that are nearly equivalent but not identical, such as (“Hundreds” and “Hund”) which GOLD would exclude, are now brought into the common set. This expanded $C$ then feeds into the same hybrid loss: direct KL is applied to common tokens, while uncommon tokens are handled via ULD.
### Choosing Between P-KL and H-KL
The decision is based on a coverage audit of token categories within the student’s vocabulary. For math-related tasks, multi-digit numerals are the category of greatest importance. Table 8 in the research paper illustrates the contrast: using Qwen3-4B, none of the 100 two-digit or 1,000 three-digit numerals in Llama’s vocabulary make it into $C$. However, with Phi-4-mini-Instruct, all 100 two-digit and all 1,000 three-digit numerals are included in $C$. ASCII punctuation and single-digit numbers are fully covered across both systems.
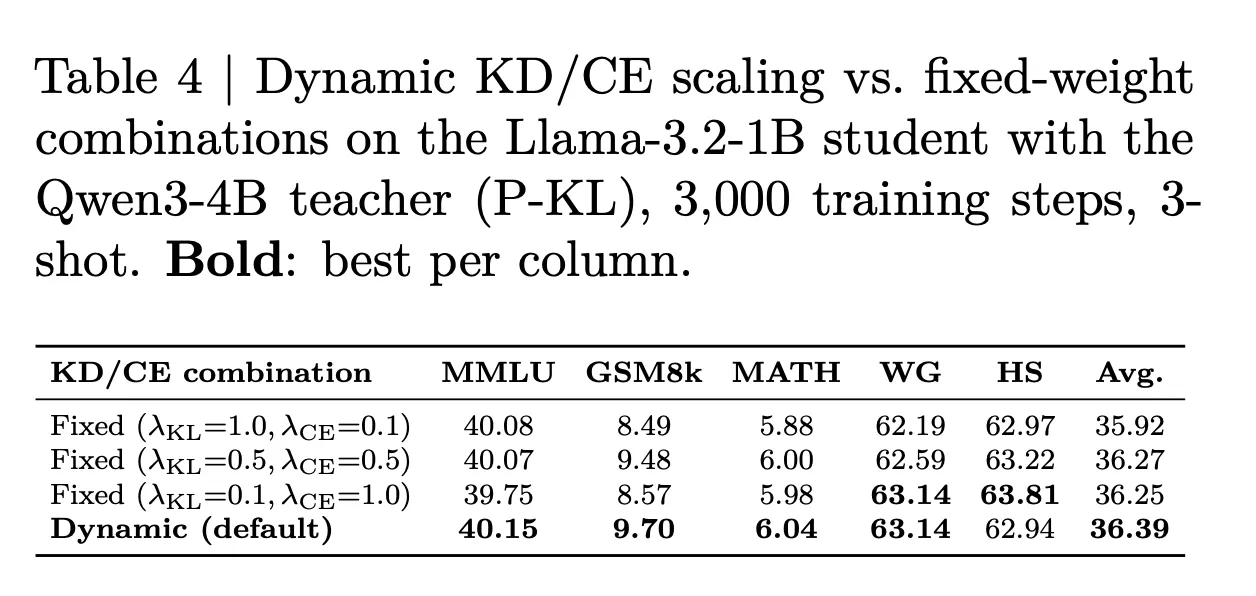
The guideline is straightforward: choose P-KL when critical tokens are missing from $C$ (as with Qwen3-4B), and switch to H-KL when the partition structure is solid (as with Phi-4-mini-Instruct). Table 2 in the research paper confirms this pattern sharply: P-KL surpasses H-KL by an average of +3.55 points on Qwen3-4B, while H-KL beats P-KL by an average of +1.68 points on Phi-4-mini.

Leveraging Multiple Teachers for Knowledge Transfer
The X-Token framework is designed to accommodate several instructors simultaneously. Every educator brings a personalized mapping layer W_m and a strategy for calculating loss. When educators share the same vocabulary structures, traditional token-based KL divergence methods apply. The combined instructor loss merges individual contributions using weighting coefficients αm as follows:
The researchers tested both fixed weighting approaches and dynamic confidence-based alternatives. The adaptive methods derive α_m from the instructor’s confidence metrics—specifically cross-entropy values, Shannon entropy measures, or peak probability scores. Across both multi-instructor configurations examined, the fixed weighting strategy consistently delivered superior results compared to the adaptive techniques.