



IBM has introduced the discharge of Granite 4.0 3B Imaginative and prescient, a vision-language mannequin (VLM) engineered particularly for enterprise-grade doc information extraction. Departing from the monolithic strategy of bigger multimodal fashions, the 4.0 Imaginative and prescient launch is architected as a specialised adapter designed to deliver high-fidelity visible reasoning to the Granite 4.0 Micro language spine.
This launch represents a transition towards modular, extraction-focused AI that prioritizes structured information accuracy—corresponding to changing complicated charts to code or tables to HTML—over general-purpose picture captioning.
Structure: Modular LoRA and DeepStack Integration
The Granite 4.0 3B Imaginative and prescient mannequin is delivered as a LoRA (Low-Rank Adaptation) adapter with roughly 0.5B parameters. This adapter is designed to be loaded on prime of the Granite 4.0 Micro base mannequin, a 3.5B parameter dense language mannequin. This design permits for a ‘dual-mode’ deployment: the bottom mannequin can deal with text-only requests independently, whereas the imaginative and prescient adapter is activated solely when multimodal processing is required.
Imaginative and prescient Encoder and Patch Tiling
The visible part makes use of the google/siglip2-so400m-patch16-384 encoder. To keep up excessive decision throughout numerous doc layouts, the mannequin employs a tiling mechanism. Enter pictures are decomposed into 384×384 patches, that are processed alongside a downscaled international view of the whole picture. This strategy ensures that wonderful particulars—corresponding to subscripts in formulation or small information factors in charts—are preserved earlier than they attain the language spine.
The DeepStack Spine
To bridge the imaginative and prescient and language modalities, IBM makes use of a variant of the DeepStack structure. This entails deeply stacking visible tokens into the language mannequin throughout 8 particular injection factors. By routing visible options into a number of layers of the transformer, the mannequin achieves a tighter alignment between the ‘what’ (semantic content material) and the ‘where’ (spatial format), which is vital for sustaining construction throughout doc parsing.
Coaching Curriculum: Centered on Chart and Desk Extraction
The coaching of Granite 4.0 3B Imaginative and prescient displays a strategic shift towards specialised extraction duties. Relatively than relying solely on common image-text datasets, IBM utilized a curated combination of instruction-following information centered on complicated doc constructions.
- ChartNet Dataset: The mannequin was refined utilizing ChartNet, a million-scale multimodal dataset designed for strong chart understanding.
- Code-Guided Pipeline: A key technical spotlight of the coaching entails a “code-guided” strategy for chart reasoning. This pipeline makes use of aligned information consisting of the unique plotting code, the ensuing rendered picture, and the underlying information desk, permitting the mannequin to study the structural relationship between visible representations and their supply information.
- Extraction Tuning: The mannequin was fine-tuned on a combination of datasets specializing in Key-Worth Pair (KVP) extraction, desk construction recognition, and changing visible charts into machine-readable codecs like CSV, JSON, and OTSL.
Efficiency and Analysis Benchmarks
In technical evaluations, Granite 4.0 3B Imaginative and prescient has been benchmarked in opposition to a number of industry-standard suites for doc understanding. It is very important notice that datasets like PubTables-v2 and OmniDocBench are utilized as analysis benchmarks to confirm the mannequin’s zero-shot efficiency in real-world situations.
| Process | Analysis Benchmark | Metric |
| KVP Extraction | VAREX | 85.5% Precise Match (Zero-Shot) |
| Chart Reasoning | ChartNet (Human-Verified Check Set) | Excessive Accuracy in Chart2Summary |
| Desk Extraction | TableVQA-Bench & OmniDocBench | Evaluated by way of TEDS and HTML extraction |
The mannequin at the moment ranks third amongst fashions within the 2–4B parameter class on the VAREX leaderboard (as of March 2026), demonstrating its effectivity in structured extraction regardless of its compact dimension.
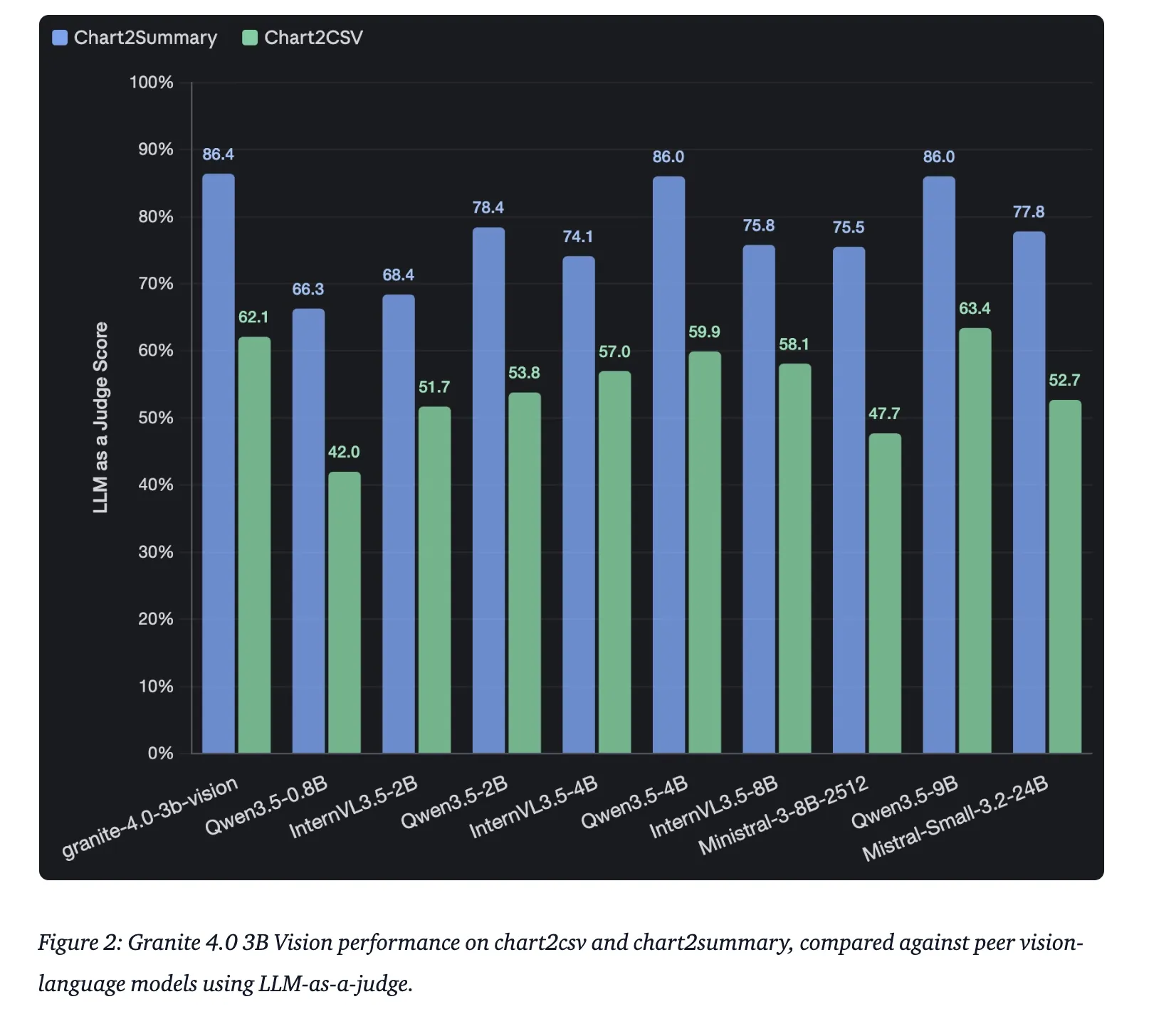
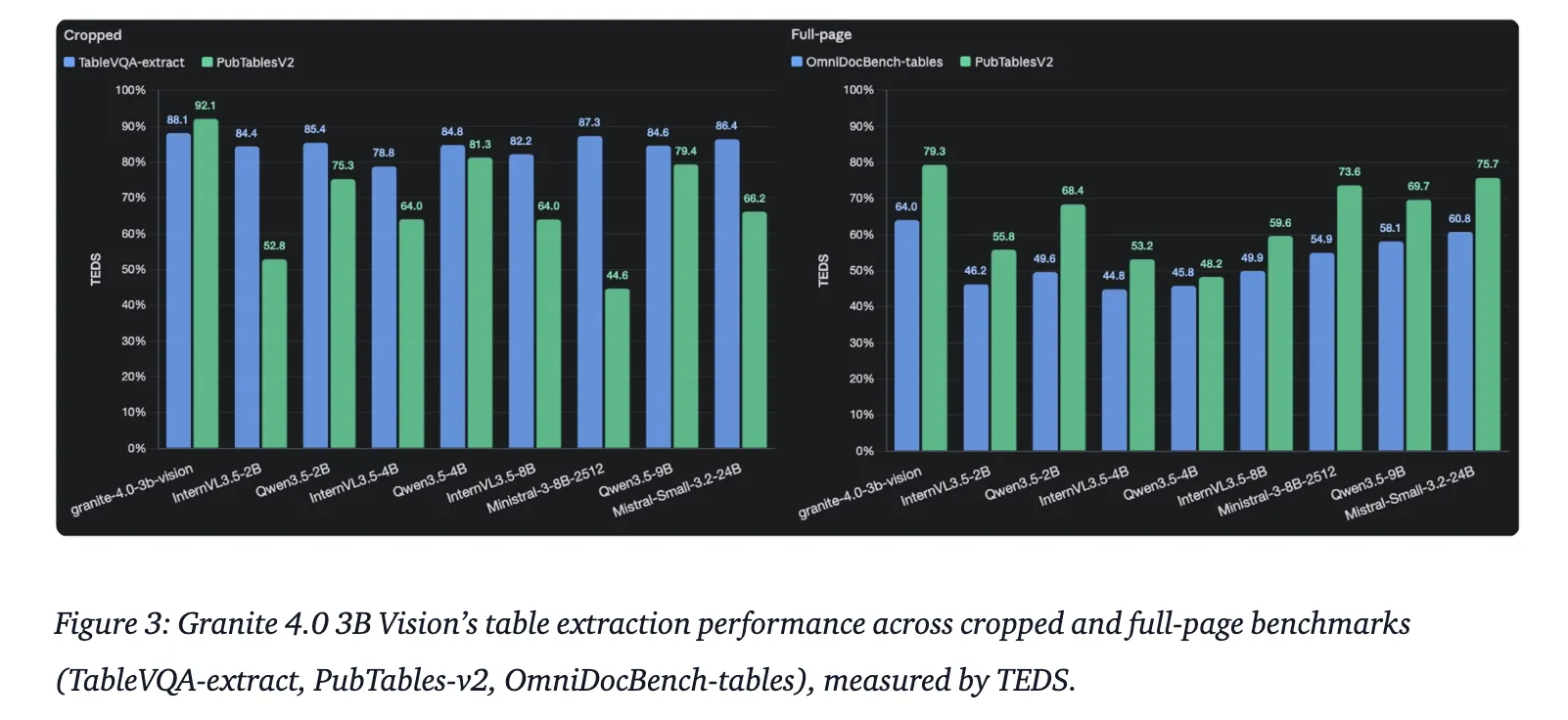
Key Takeaways
- Modular LoRA Structure: The mannequin is a 0.5B parameter LoRA adapter that operates on the Granite 4.0 Micro (3.5B) spine. This design permits a single deployment to deal with text-only workloads effectively whereas activating imaginative and prescient capabilities solely when wanted.
- Excessive-Decision Tiling: Using the google/siglip2-so400m-patch16-384 encoder, the mannequin processes pictures by tiling them into 384×384 patches alongside a world downscaled view, making certain that wonderful particulars in complicated paperwork are preserved.
- DeepStack Injection: To enhance format consciousness, the mannequin makes use of a DeepStack strategy with 8 injection factors. This routes semantic options to earlier layers and spatial particulars to later layers, which is vital for correct desk and chart extraction.
- Specialised Extraction Coaching: Past common instruction following, the mannequin was refined utilizing ChartNet and a ‘code-guided’ pipeline that aligns plotting code, pictures, and information tables to assist the mannequin internalize the logic of visible information constructions.
- Developer-Prepared Integration: The discharge is Apache 2.0 licensed and options native help for vLLM (by way of a customized mannequin implementation) and Docling, IBM’s device for changing unstructured PDFs into machine-readable JSON or HTML.
Take a look at the Technical particulars and Mannequin Weight. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.