



Can symbolic regression be the important thing to reworking opaque deep studying fashions into interpretable, closed-form mathematical equations? or Say you will have educated your deep studying mannequin. It really works. However have you learnt what it has truly discovered? A crew of College of Cambridge researchers suggest ‘SymTorch’, a library designed to combine symbolic regression (SR) into deep studying workflows. It permits researchers to approximate neural community elements with closed-form mathematical expressions, facilitating practical interpretability and potential inference acceleration.
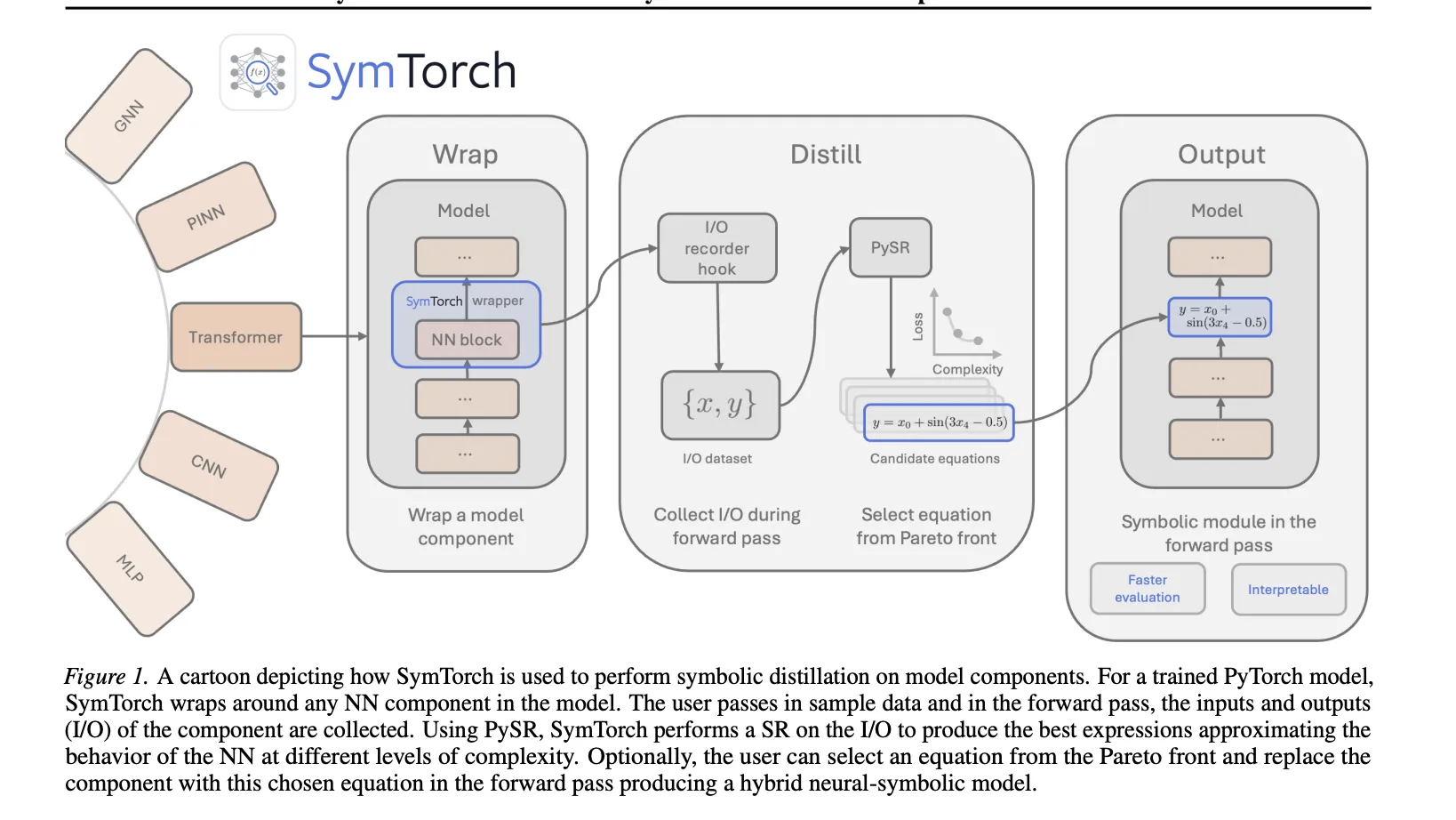
Core Mechanism: The Wrap-Distill-Change Workflow
SymTorch simplifies the engineering required to extract symbolic equations from educated fashions by automating information motion and hook administration.
- Wrap: Customers apply the
SymbolicModelwrapper to anynn.Moduleor callable operate. - Distill: The library registers ahead hooks to file enter and output activations throughout a ahead move. These are cached and transferred from the GPU to the CPU for symbolic regression by way of PySR.
- Change: As soon as distilled, the unique neural weights might be changed with the found equation within the ahead move utilizing
switch_to_symbolic.
The library interfaces with PySR, which makes use of a multi-population genetic algorithm to seek out equations that stability accuracy and complexity on a Pareto entrance. The ‘best’ equation is chosen by maximizing the fractional drop in log imply absolute error relative to a rise in complexity.
Case Examine: Accelerating LLM Inference
A main software explored on this analysis is changing Multi-Layer Perceptron (MLP) layers in Transformer fashions with symbolic surrogates to enhance throughput.
Implementation Particulars
Because of the excessive dimensionality of LLM activations, the analysis crew employed Principal Element Evaluation (PCA) to compress inputs and outputs earlier than performing SR. For the Qwen2.5-1.5B mannequin, they chose 32 principal elements for inputs and eight for outputs throughout three focused layers.
Efficiency Commerce-offs
The intervention resulted in an 8.3% improve in token throughput. Nonetheless, this achieve got here with a non-trivial improve in perplexity, primarily pushed by the PCA dimensionality discount reasonably than the symbolic approximation itself.
| Metric | Baseline (Qwen2.5-1.5B) | Symbolic Surrogate |
| Perplexity (Wikitext-2) | 10.62 | 13.76 |
| Throughput (tokens/s) | 4878.82 | 5281.42 |
| Avg. Latency (ms) | 209.89 | 193.89 |
GNNs and PINNs
SymTorch was validated on its capability to get better recognized bodily legal guidelines from latent representations in scientific fashions.
- Graph Neural Networks (GNNs): By coaching a GNN on particle dynamics, the analysis crew used SymTorch to get better empirical pressure legal guidelines, equivalent to gravity (1/r2) and spring forces, instantly from the sting messages.
- Physics-Knowledgeable Neural Networks (PINNs): The library efficiently distilled the 1-D warmth equation’s analytic answer from a educated PINN. The PINN’s inductive bias allowed it to realize a Imply Squared Error (MSE) of seven.40 x 10-6.
- LLM Arithmetic Evaluation: Symbolic distillation was used to examine how fashions like Llama-3.2-1B carry out 3-digit addition and multiplication. The distilled equations revealed that whereas the fashions are sometimes appropriate, they depend on inner heuristics that embrace systematic numerical errors.
Key Takeaways
- Automated Symbolic Distillation: SymTorch is a library that automates the method of changing complicated neural community elements with interpretable, closed-form mathematical equations by wrapping elements and gathering their input-output habits.
- Engineering Barrier Elimination: The library handles important engineering challenges that beforehand hindered the adoption of symbolic regression, together with GPU-CPU information switch, input-output caching, and seamless switching between neural and symbolic ahead passes.
- LLM Inference Acceleration: A proof-of-concept demonstrated that changing MLP layers in a transformer mannequin with symbolic surrogates achieved an 8.3% throughput enchancment, although with some efficiency degradation in perplexity.
- Scientific Legislation Discovery: SymTorch was efficiently used to get better bodily legal guidelines from Graph Neural Networks (GNNs) and analytic options to the 1-D warmth equation from Physics-Knowledgeable Neural Networks (PINNs).
- Purposeful Interpretability of LLMs: By distilling the end-to-end habits of LLMs, researchers may examine the express mathematical heuristics used for duties like arithmetic, revealing the place inner logic deviates from precise operations.
Try the Paper, Repo and Mission Web page. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be a part of us on telegram as properly.
Max is an AI analyst at MarkTechPost, primarily based in Silicon Valley, who actively shapes the way forward for expertise. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI day by day to translate complicated tech developments into clear, comprehensible insights