



Robbyant, the embodied AI unit inside Ant Group, has open sourced LingBot-World, a big scale world mannequin that turns video era into an interactive simulator for embodied brokers, autonomous driving and video games. The system is designed to render controllable environments with excessive visible constancy, sturdy dynamics and lengthy temporal horizons, whereas staying responsive sufficient for actual time management.
From textual content to video to textual content to world
Most textual content to video fashions generate quick clips that look reasonable however behave like passive motion pictures. They don’t mannequin how actions change the setting over time. LingBot-World is constructed as a substitute as an motion conditioned world mannequin. It learns the transition dynamics of a digital world, in order that keyboard and mouse inputs, along with digicam movement, drive the evolution of future frames.
Formally, the mannequin learns the conditional distribution of future video tokens, given previous frames, language prompts and discrete actions. At coaching time, it predicts sequences as much as about 60 seconds. At inference time, it may well autoregressively roll out coherent video streams that stretch to round 10 minutes, whereas retaining scene construction secure.
Knowledge engine, from internet video to interactive trajectories
A core design in LingBot-World is a unified knowledge engine. It gives wealthy, aligned supervision for a way actions change the world whereas overlaying various actual scenes.
The information acquisition pipeline combines 3 sources:
- Giant scale internet movies of people, animals and autos, from each first individual and third individual views
- Recreation knowledge, the place RGB frames are strictly paired with person controls comparable to W, A, S, D and digicam parameters
- Artificial trajectories rendered in Unreal Engine, the place clear frames, digicam intrinsics and extrinsics and object layouts are all identified
After assortment, a profiling stage standardizes this heterogeneous corpus. It filters for decision and length, segments movies into clips and estimates lacking digicam parameters utilizing geometry and pose fashions. A imaginative and prescient language mannequin scores clips for high quality, movement magnitude and think about kind, then selects a curated subset.
On high of this, a hierarchical captioning module builds 3 ranges of textual content supervision:
- Narrative captions for complete trajectories, together with digicam movement
- Scene static captions that describe setting format with out movement
- Dense temporal captions for brief time home windows that concentrate on native dynamics
This separation lets the mannequin disentangle static construction from movement patterns, which is vital for lengthy horizon consistency.
Structure, MoE video spine and motion conditioning
LingBot-World begins from Wan2.2, a 14B parameter picture to video diffusion transformer. This spine already captures sturdy open area video priors. Robbyant group extends it into a combination of specialists DiT, with 2 specialists. Every knowledgeable has about 14B parameters, so the overall parameter depend is 28B, however just one knowledgeable is energetic at every denoising step. This retains inference price much like a dense 14B mannequin whereas increasing capability.
A curriculum extends coaching sequences from 5 seconds to 60 seconds. The schedule will increase the proportion of excessive noise timesteps, which stabilizes world layouts over lengthy contexts and reduces mode collapse for lengthy rollouts.
To make the mannequin interactive, actions are injected immediately into the transformer blocks. Digital camera rotations are encoded with Plücker embeddings. Keyboard actions are represented as multi sizzling vectors over keys comparable to W, A, S, D. These encodings are fused and handed via adaptive layer normalization modules, which modulate hidden states within the DiT. Solely the motion adapter layers are tremendous tuned, the primary video spine stays frozen, so the mannequin retains visible high quality from pre coaching whereas studying motion responsiveness from a smaller interactive dataset.
Coaching makes use of each picture to video and video to video continuation duties. Given a single picture, the mannequin can synthesize future frames. Given a partial clip, it may well lengthen the sequence. This ends in an inside transition operate that may begin from arbitrary time factors.
LingBot World Quick, distillation for actual time use
The mid-trained mannequin, LingBot-World Base, nonetheless depends on multi step diffusion and full temporal consideration, that are costly for actual time interplay. Robbyant group introduces LingBot-World-Quick as an accelerated variant.
The quick mannequin is initialized from the excessive noise knowledgeable and replaces full temporal consideration with block causal consideration. Inside every temporal block, consideration is bidirectional. Throughout blocks, it’s causal. This design helps key worth caching, so the mannequin can stream frames autoregressively with decrease price.
Distillation makes use of a diffusion forcing technique. The scholar is skilled on a small set of goal timesteps, together with timestep 0, so it sees each noisy and clear latents. Distribution Matching Distillation is mixed with an adversarial discriminator head. The adversarial loss updates solely the discriminator. The scholar community is up to date with the distillation loss, which stabilizes coaching whereas preserving motion following and temporal coherence.
In experiments, LingBot World Quick reaches 16 frames per second when processing 480p movies on a system with 1 GPU node, and, maintains finish to finish interplay latency beneath 1 second for actual time management.
Emergent reminiscence and lengthy horizon habits
Some of the attention-grabbing properties of LingBot-World is emergent reminiscence. The mannequin maintains world consistency with out express 3D representations comparable to Gaussian splatting. When the digicam strikes away from a landmark comparable to Stonehenge and returns after about 60 seconds, the construction reappears with constant geometry. When a automobile leaves the body and later reenters, it seems at a bodily believable location, not frozen or reset.
The mannequin may maintain extremely lengthy sequences. The analysis group reveals coherent video era that extends as much as 10 minutes, with secure format and narrative construction.]
VBench outcomes and comparability to different world fashions
For quantitative analysis, the analysis group used VBench on a curated set of 100 generated movies, every longer than 30 seconds. LingBot-World is in comparison with 2 current world fashions, Yume-1.5 and HY-World-1.5.
On VBench, LingBot World stories:
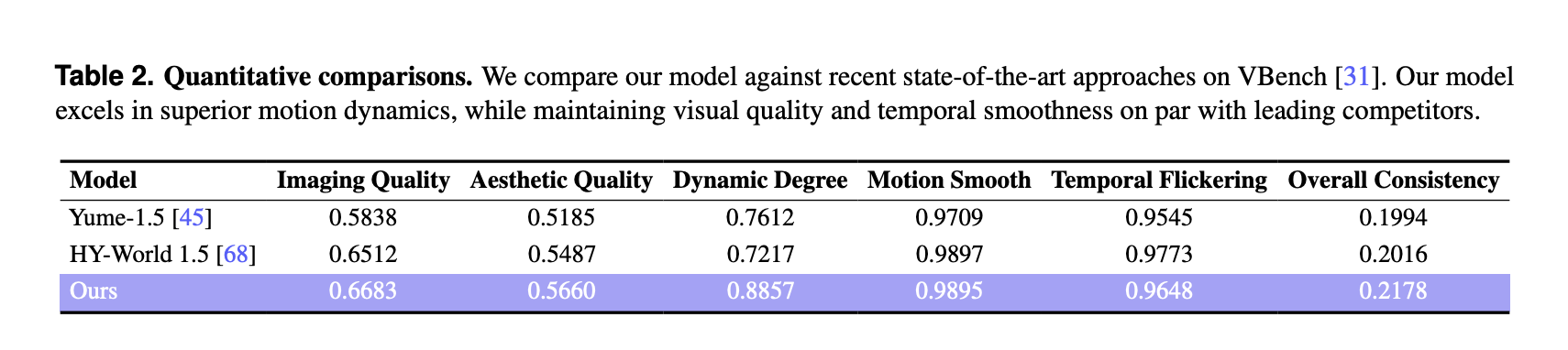
These scores are increased than each baselines for imaging high quality, aesthetic high quality and dynamic diploma. The dynamic diploma margin is giant, 0.8857 in comparison with 0.7612 and 0.7217, which signifies richer scene transitions and extra complicated movement that reply to person inputs. Movement smoothness and temporal flicker are akin to the most effective baseline, and the tactic achieves the most effective total consistency metric among the many 3 fashions.
A separate comparability with different interactive techniques comparable to Matrix-Recreation-2.0, Mirage-2 and Genie-3 highlights that LingBot-World is without doubt one of the few absolutely open sourced world fashions that mixes basic area protection, lengthy era horizon, excessive dynamic diploma, 720p decision and actual time capabilities.

Functions, promptable worlds, brokers and 3D reconstruction
Past video synthesis, LingBot-World is positioned as a testbed for embodied AI. The mannequin helps promptable world occasions, the place textual content directions change climate, lighting, fashion or inject native occasions comparable to fireworks or transferring animals over time, whereas preserving spatial construction.
It may additionally prepare downstream motion brokers, for instance with a small imaginative and prescient language motion mannequin like Qwen3-VL-2B predicting management insurance policies from pictures. As a result of the generated video streams are geometrically constant, they can be utilized as enter to 3D reconstruction pipelines, which produce secure level clouds for indoor, outside and artificial scenes.
Key Takeaways
- LingBot-World is an motion conditioned world mannequin that extends textual content to video into textual content to world simulation, the place keyboard actions and digicam movement immediately management lengthy horizon video rollouts as much as round 10 minutes.
- The system is skilled on a unified knowledge engine that mixes internet movies, recreation logs with motion labels and Unreal Engine trajectories, plus hierarchical narrative, static scene and dense temporal captions to separate format from movement.
- The core spine is a 28B parameter combination of specialists diffusion transformer, constructed from Wan2.2, with 2 specialists of 14B every, and motion adapters which are tremendous tuned whereas the visible spine stays frozen.
- LingBot-World-Quick is a distilled variant that makes use of block causal consideration, diffusion forcing and distribution matching distillation to realize about 16 frames per second at 480p on 1 GPU node, with reported finish to finish latency beneath 1 second for interactive use.
- On VBench with 100 generated movies longer than 30 seconds, LingBot-World stories the very best imaging high quality, aesthetic high quality and dynamic diploma amongst Yume-1.5 and HY-World-1.5, and the mannequin reveals emergent reminiscence and secure lengthy vary construction appropriate for embodied brokers and 3D reconstruction.
Try the Paper, Repo, Venture web page and Mannequin Weights. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be part of us on telegram as properly.