



Picture by Writer
# Introduction
You construct an LLM powered function that works completely in your machine. The responses are quick, correct, and every little thing feels clean. Then you definitely deploy it, and all of the sudden, issues change. Responses decelerate. Prices begin creeping up. Customers ask questions you didn’t anticipate. The mannequin offers solutions that look effective at first look however break actual workflows. What labored in a managed setting begins falling aside underneath actual utilization.
That is the place most initiatives hit a wall. The problem will not be getting a language mannequin to work. That half is simpler than ever. The true problem is making it dependable, scalable, and usable in a manufacturing setting the place inputs are messy, expectations are excessive, and errors really matter.
Deployment is not only about calling an API or internet hosting a mannequin. It includes selections round structure, price, latency, security, and monitoring. Every of those elements can have an effect on whether or not your system holds up or quietly fails over time. A number of groups underestimate this hole. They focus closely on prompts and mannequin efficiency, however spend far much less time interested by how the system behaves as soon as actual customers are concerned. Listed here are 7 sensible steps to maneuver from prototype to production-ready LLM techniques.
# Step 1: Defining the Use Case Clearly
Most deployment issues begin earlier than any code is written. If the use case is imprecise, every little thing that follows turns into more durable. You find yourself over-engineering elements of the system whereas lacking what really issues.
Readability right here means narrowing the issue down. As an alternative of claiming “build a chatbot,” outline precisely what that chatbot ought to do. Is it answering FAQs, dealing with assist tickets, or guiding customers by a product? Every of those requires a distinct method.
Enter and output expectations additionally must be clear. What sort of knowledge will customers present? What format ought to the response take — free-form textual content, structured JSON, or one thing else fully? These selections have an effect on the way you design prompts, validation layers, and even your UI.
Success metrics are simply as vital. With out them, it’s arduous to know if the system is working. That could possibly be response accuracy, activity completion charge, latency, and even person satisfaction. The clearer the metric, the better it’s to make tradeoffs later.
A easy instance makes this apparent. A general-purpose chatbot is broad and unpredictable. A structured knowledge extractor, alternatively, has clear inputs and outputs. It’s simpler to check, simpler to optimize, and simpler to deploy reliably. The extra particular your use case, the better every little thing else turns into.
# Step 2: Selecting the Proper Mannequin (Not the Greatest One)
As soon as the use case is obvious, the subsequent resolution is the mannequin itself. It may be tempting to go straight for probably the most highly effective mannequin obtainable. Greater fashions are inclined to carry out higher in benchmarks, however in manufacturing, that is just one a part of the equation. Price is usually the primary constraint. Bigger fashions are dearer to run, particularly at scale. What appears manageable throughout testing can develop into a critical expense as soon as actual visitors is available in.
Latency is one other issue. Greater fashions normally take longer to reply. For user-facing functions, even small delays can have an effect on the expertise. Accuracy nonetheless issues, however it must be seen in context. A barely much less highly effective mannequin that performs effectively in your particular activity could also be a more sensible choice than a bigger mannequin that’s extra common however slower and dearer.
There may be additionally the choice between hosted APIs and open-source fashions. Hosted APIs are simpler to combine and preserve, however you commerce off some management. Open-source fashions offer you extra flexibility and might cut back long-term prices, however they require extra infrastructure and operational effort. In observe, your best option is never the largest mannequin. It’s the one that matches your use case, price range, and efficiency necessities.
# Step 3: Designing Your System Structure
As soon as you progress past a easy prototype, the mannequin is now not the system. It turns into one element inside a bigger structure. LLMs shouldn’t function in isolation. A typical manufacturing setup consists of an API layer that handles incoming requests, the mannequin itself for era, a retrieval layer for grounding responses, and a database for storing knowledge, logs, or person state. Every half performs a job in making the system dependable and scalable.
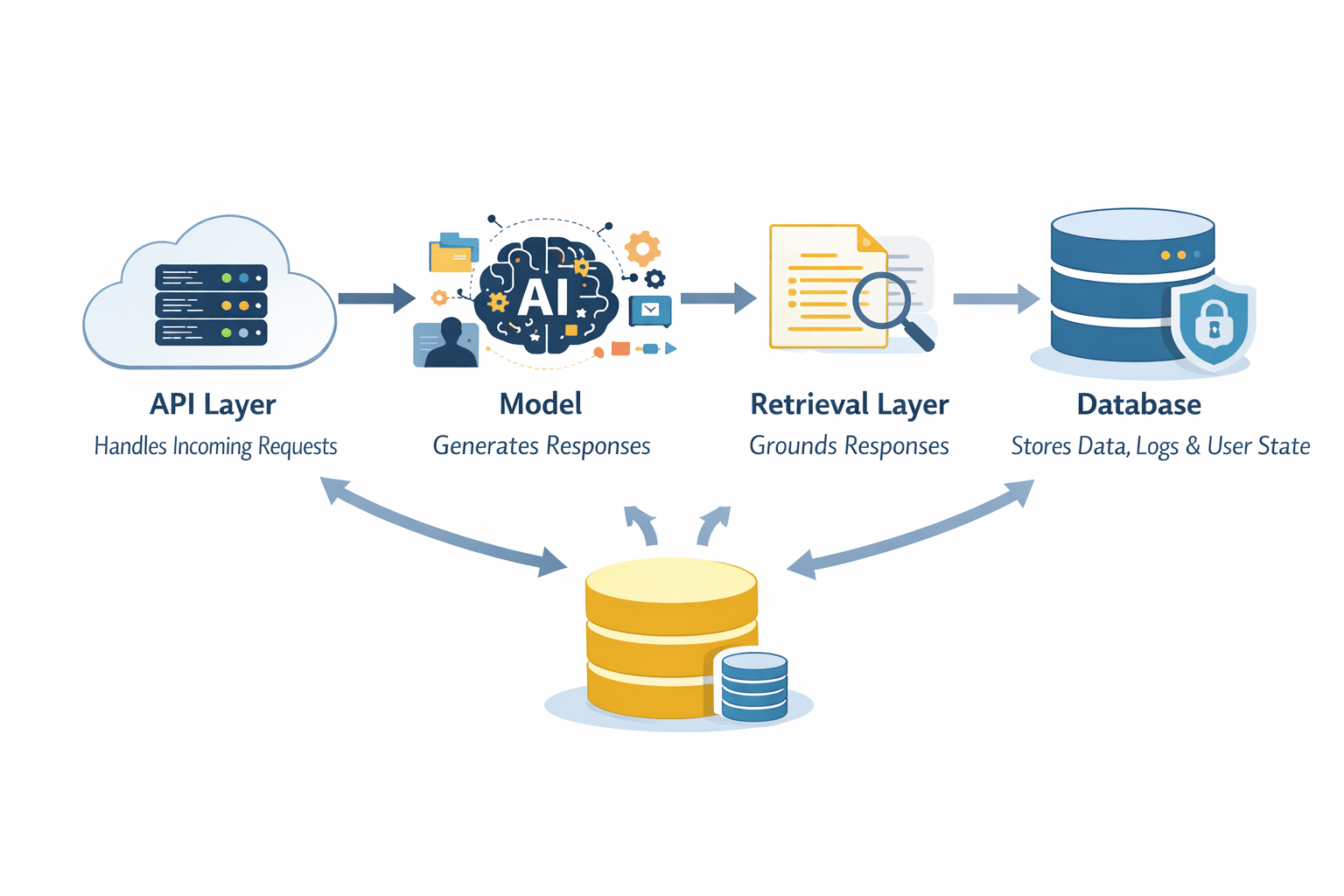
Layers in a System Structure | Picture by Writer
The API layer acts because the entry level. It manages requests, handles authentication, and routes inputs to the correct parts. That is the place you possibly can implement limits, validate inputs, and management how the system is accessed.
The mannequin sits within the center, however it doesn’t need to do every little thing. Retrieval techniques can present related context from exterior knowledge sources, lowering hallucinations and bettering accuracy. Databases retailer structured knowledge, person interactions, and system outputs that may be reused later.
One other vital resolution is whether or not your system is stateless or stateful. Stateless techniques deal with each request independently, which makes them simpler to scale. Stateful techniques retain context throughout interactions, which may enhance person expertise however provides complexity in how knowledge is saved and retrieved.
Pondering when it comes to pipelines helps right here. As an alternative of 1 step that generates a solution, you design a circulate. Enter is available in, passes validation, is enriched with context, is processed by the mannequin, and is dealt with earlier than being returned. Every step is managed and observable.
# Step 4: Including Guardrails and Security Layers
Even with a stable structure, uncooked mannequin output ought to by no means go on to customers. Language fashions are highly effective, however they aren’t inherently secure or dependable. With out constraints, they’ll generate incorrect, irrelevant, and even dangerous responses.
Guardrails are what hold that in test.
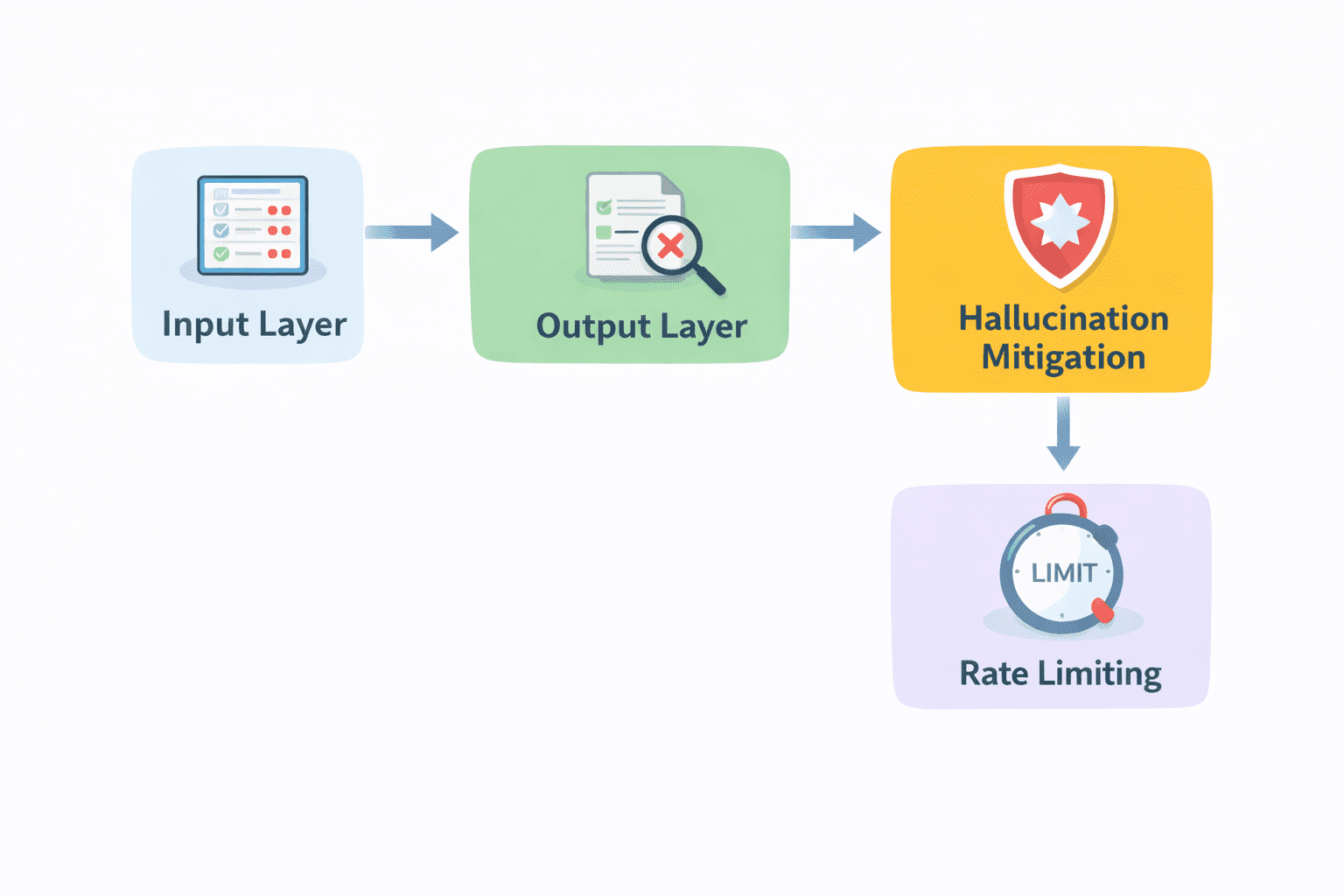
Guardrails and Security Layers | Picture by Writer
- Enter validation is the primary layer. Earlier than a request reaches the mannequin, it needs to be checked. Is the enter legitimate? Does it meet anticipated codecs? Are there makes an attempt to misuse the system? Filtering at this stage prevents pointless or dangerous calls.
- Output filtering comes subsequent. After the mannequin generates a response, it needs to be reviewed earlier than being delivered. This will embrace checking for dangerous content material, imposing formatting guidelines, or validating particular fields in structured outputs.
- Hallucination mitigation can also be a part of this layer. Strategies like retrieval, verification, or constrained era may be utilized right here to scale back the probabilities of incorrect responses reaching the person.
- Price limiting is one other sensible safeguard. It protects your system from abuse and helps management prices by limiting how usually requests may be made.
With out guardrails, even a powerful mannequin can produce outcomes that break belief or create danger. With the correct layers in place, you flip uncooked era into one thing managed and dependable.
# Step 5: Optimizing for Latency and Price
As soon as your system is reside, the efficiency stops being a technical element and turns into a user-facing drawback. Gradual responses frustrate customers. Excessive prices restrict how far you possibly can scale. Each can quietly kill an in any other case stable product.
Caching is likely one of the easiest methods to enhance each. If customers are asking comparable questions or triggering comparable workflows, you don’t want to generate a recent response each time. Storing and reusing outcomes can considerably cut back each latency and price.
Streaming responses additionally helps with perceived efficiency. As an alternative of ready for the total output, customers begin seeing outcomes as they’re generated. Even when complete processing time stays the identical, the expertise feels sooner.
One other sensible method is deciding on fashions dynamically. Not each request wants probably the most highly effective mannequin. Easier duties may be dealt with by smaller, cheaper fashions, whereas extra advanced ones may be routed to stronger fashions. This type of routing retains prices underneath management with out sacrificing high quality the place it issues.
Batching is beneficial in techniques that deal with a number of requests directly. As an alternative of processing every request individually, grouping them can enhance effectivity and cut back overhead.
The widespread thread throughout all of that is stability. You aren’t simply optimizing for velocity or price in isolation. You’re discovering a degree the place the system stays responsive whereas staying economically viable.
# Step 6: Implementing Monitoring and Logging
As soon as the system is operating, you want visibility into what is going on as a result of, with out it, you’re working blind. The inspiration is logging. Each request and response needs to be tracked in a approach that permits you to evaluation what the system is doing. This consists of person inputs, mannequin outputs, and any intermediate steps within the pipeline. When one thing goes fallacious, these logs are sometimes the one solution to perceive why.
Error monitoring builds on this. As an alternative of manually scanning logs, the system ought to floor failures mechanically. That could possibly be timeouts, invalid outputs, or surprising conduct. Catching these early prevents small points from turning into bigger issues.
Efficiency metrics are simply as vital. You want to understand how lengthy responses take, how usually requests succeed, and the place bottlenecks exist. These metrics provide help to establish areas that want optimization.
Person suggestions provides one other layer. Typically the system seems to work accurately from a technical perspective however nonetheless produces poor outcomes. Suggestions indicators, whether or not specific scores or implicit conduct, provide help to perceive how effectively the system is definitely acting from the person’s perspective.
# Step 7: Iterating with Actual Person Suggestions
You need to know that deployment will not be the end line. It’s the place the actual work begins. Irrespective of how effectively you design your system, actual customers will use it in methods you didn’t anticipate. They’ll ask completely different questions, present messy inputs, and push the system into edge circumstances that by no means confirmed up throughout testing.
That is the place iteration turns into important. A/B testing is one solution to method this. You may take a look at completely different prompts, mannequin configurations, or system flows with actual customers and examine outcomes. As an alternative of guessing what works, you measure it.
Immediate iteration additionally continues at this stage, however in a extra grounded approach. As an alternative of optimizing in isolation, you refine prompts primarily based on precise utilization patterns and failure circumstances. The identical applies to different elements of the system. Retrieval high quality, guardrails, and routing logic can all be improved over time.
A very powerful enter right here is person conduct. What customers click on, the place they drop off, what they repeat, and what they complain about. These indicators reveal issues that metrics alone may miss, and over time, this creates a loop. Customers work together with the system, the system collects indicators, and people indicators drive enhancements. Every iteration makes the system extra aligned with real-world utilization.

Diagram displaying a easy end-to-end circulate of a manufacturing LLM system | Picture by Writer
# Wrapping Up
By the point you attain manufacturing, it turns into clear that deploying language fashions is not only a technical step. It’s a design problem. The mannequin issues, however it is just one piece. What determines success is how effectively every little thing round it really works collectively. The structure, the guardrails, the monitoring, and the iteration course of all play a job in shaping how dependable the system turns into.
Sturdy deployments concentrate on reliability first. They make sure the system behaves persistently underneath completely different situations. They’re constructed to scale with out breaking as utilization grows. And they’re designed to enhance over time by steady suggestions and iteration, and that is what separates working techniques from fragile ones.
Shittu Olumide is a software program engineer and technical author captivated with leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying advanced ideas. You can too discover Shittu on Twitter.