



According to RLWRLD, operating in real-world settings means understanding what action to take, keeping track of relevant information over time, and basing decisions on signals tied to the physical world. | Source: RLWRLD
Last week, RLWRLD unveiled RLDX-1, a new foundation model designed with dexterity as its core focus. The company created this model to handle intricate industrial tasks in real-world scenarios using robotic hands with a high number of degrees of freedom (DoF).
According to RLWRLD, current foundation models often fall short of key requirements—such as memory of context or the ability to sense force—needed to operate smoothly in real environments. To close these gaps, RLDX-1 covers the entire robotics workflow. It brings together a scalable approach for collecting data, a flexible architectural blueprint, solid training practices, and streamlined deployment plans, the company stated.
Because of this, RLWRLD says RLDX-1 delivers top-tier performance. The model demonstrates both accuracy and broad generalization in simulated settings as well as real-world industrial use cases.
RLWRLD engineered RLDX-1 from scratch specifically to power dexterous robotic hands. Every part of the system exists to overcome a particular shortcoming encountered during real tasks. The outcome is a single unified model capable of seeing, sensing touch, recalling past information, and adjusting on the fly—and it works across single-arm setups, dual-arm platforms, and humanoid forms equipped with high-DoF hands.
RLWRLD outlines five key dimensions of dexterity
The final hurdle in industrial automation is achieving true dexterity. Robots today still struggle with tasks like pouring coffee as the pot gets lighter, catching a shifting item on a conveyor belt, or gripping and turning a hexagonal nut with just their fingertips, observed RLWRLD, headquartered in Seoul, South Korea.
By analyzing common customer demands, RLWRLD distilled them into DexBench, a testing benchmark organized around five categories that represent specific failure points for current robots.
The five levels are as follows:
- Grasp variety: Having five-fingered hands is the foundational requirement assumed by all other categories below. RLWRLD has conducted tests with over 10 different models in-house. The company uses two distinct data pipelines to expand grasping variety. A synthetic robot-data system supplements recordings from a modest teleoperation dataset, while Human Data captures the refined in-hand manipulations that teleoperation alone cannot achieve.
- Spatial precision: The policy needs to fully understand the surrounding scene so it can make contact at exactly the right spot before touching anything. RLDX-1 boosts this ability with a vision language model (VLM) tailored specifically to robotics, trained using robot visual question-and-answering (VQA) data. The questions are deliberately crafted to probe geometric relationships between the robot’s end-effector and the target object. This training pushes the VLM to more accurately interpret object positions and spatial arrangements essential for making contact in precisely the right place.
- Temporal precision: A policy that acts on only a single snapshot of the scene commits to where objects were located; by the time the hand reaches for it, the item on the conveyor has already moved. To fix this, the Motion Module pulls motion-related features from space-time visual correspondences and condenses multi-frame context into a compact summary. This allows the policy to perceive where objects are headed and how quickly they are traveling.
- Contact precision: A coffee pot becoming lighter looks identical in a video feed; the meaningful data is found at the wrist torque sensor. The Physics Module assigns dedicated streams for tactile input and torque, and it forecasts upcoming contact states along with actions. This enables the policy to predict contact changes before they actually occur.
- Situational awareness: This refers to task-level thinking that wraps around all three precision levels. Without it, even a flawless movement gets stuck at the single step it was originally designed for, RLWRLD noted. The policy must have the ability to remember past context, recover from disruptions, and remain aware of overall progress.
RLDX is built on a multi-stream action transformer framework
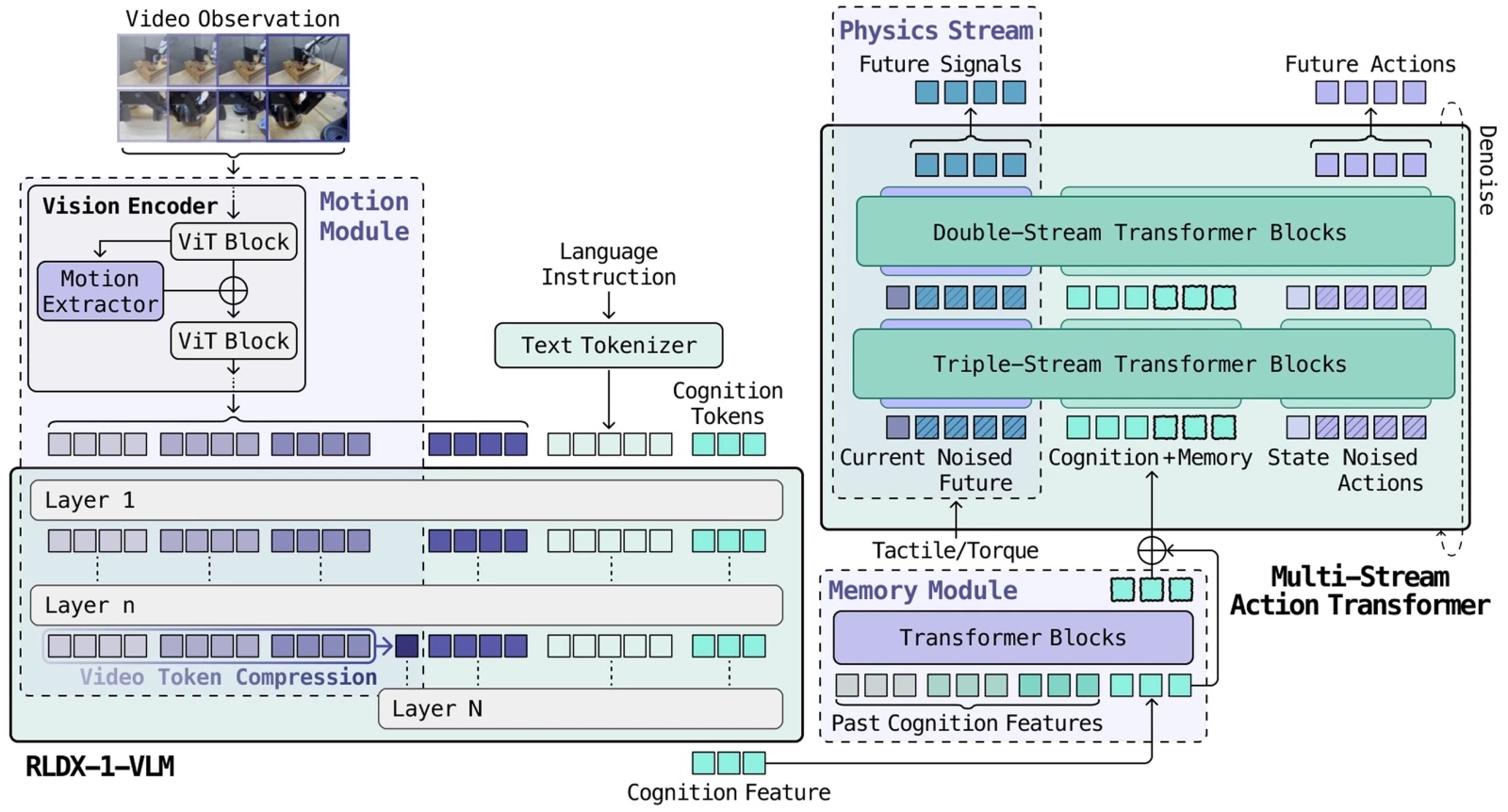
The complete RLDX architecture. | Source: RLWRLD
Each dexterity category feeds into the model as a fundamentally different type of data. Torque arrives as a rapid, continuous signal; video comes as sparse but information-dense frames; and memory maintains an ongoing internal state. In a single standard transformer, whichever signal type dominates the learning process ends up consuming all available capacity, while the others lose their influence.
The solution lies in the Multi-Stream Action Transformer (MSAT). Each data type has its own assigned processing pathway, and cognitive tokens compress the VLM’s output into a standardized interface. What follows breaks down each layer—the architecture that binds these data types together, the data engine powering its training, and the post-training refinements that make deployment practical.
RLDX is built on MSAT, a framework where every data type receives its own dedicated processing pathway, connected through joint self-attention so the streams can interact naturally.
Current vision-language-action models (VLAs) merge different data types inside a single transformer stream, where the dominant one absorbs all the model’s capacity. MSAT instead gives each data type its own dedicated channel, then allows the channels to exchange information through joint self-attention—without forcing them too early into one shared representation.
In the early stages, the data types remain in parallel channels; in the deeper layers, they merge to generate the final actions, RLWRLD explained.
RLDX-1 leverages a VLM customized for robotics
While general-purpose VLMs excel at broad visual reasoning, they don’t inherently understand what matters for robotic control, RLWRLD pointed out. To bridge this gap, RLDX-1 fine-tunes Qwen3-VL 8B on a robot-trajectory VQA dataset targeting three action-critical abilities.
The first is spatial reasoning: understanding the geometric relationship between the robot’s end-effector and target objects. The second is task comprehension: recognizing the intermediate subtask prompted by the current observation. The third is action grounding
RLDX-1’s Motion Module: Seeing Movement Before It Happens
The fine-tuned RLDX-1-VLM model acts as the visual brain behind action planning, delivering a +3.42%p improvement over the standard VLM on the RoboCasa benchmark.
According to RLWRLD, a policy that only looks at a single frame is always a step behind reality — by the time the robot’s hand reaches a target, the object on the conveyor has already shifted. To solve this, the Motion Module is built from two synergistic components.
A video token compression layer processes multiple consecutive frames through the VLM, using average pooling to collapse past frames into compact motion tokens, giving the model an efficient sense of where things are headed. Meanwhile, a motion learning layer within the vision encoder captures spatio-temporal self-similarities (STSS), directly extracting rotation, velocity, and interaction dynamics from raw visual input.
Combined, these components deliver a +37.5%p improvement over GR00T N1.6 and π₀.₅ on a conveyor belt pick-and-place task.
RLDX-1’s Physics Module: Feeling the Physical World
The Physics Module brings tactile and torque feedback into RLDX as first-class input modalities. These physical signals are essential for contact-heavy manipulation tasks and serve two primary roles: weight estimation and contact detection.
For weight estimation, when a robot pours a liquid, the module tracks weight changes across both hands to tell RLDX exactly when to stop. For contact detection, the robot must pinpoint the precise moment of contact to switch from approaching to grasping. Joint angles give ambiguous timing cues, but torque signals produce sharp, unmistakable spikes at the instant of contact.
To make the most of this, RLDX uses a dedicated processing stream that not only interprets these signals but also forecasts future torque states, equipping the policy with rich physical embeddings. And when such sensors aren’t available, the sensory stream automatically shuts off, gracefully falling back to vision-only operation — meaning one model works across different hardware configurations.
Inside RLDX-1’s Cognition Interface and Memory Module
The VLM generates a detailed understanding of the scene, but feeding every token to the action model is slow and inefficient, RLWRLD explained.
The Cognition Interface attaches 64 learnable cognition tokens to the VLM’s input. Through attention, these tokens distill the entire sequence into a compact, fixed-size representation carrying precisely the information the action model requires. The result: a +35%p boost in inference speed (16.3→22.1 Hz).
But these tokens pull double duty. The same 64-token representation also serves as the building block for long-horizon memory. A FIFO sliding cache stores past cognition features throughout the rollout, and the Memory Module attends over this cache to keep track of task progress.
Whether it’s packing a box, assembling a product, or counting 10 apples into an opaque bag, each step relies on knowing what’s already been done, RLWRLD noted. Compression and memory are the same mechanism, cleverly reused.
RLWRLD Uses Synthetic Data to Fill the Gaps
Real teleoperation data alone can’t cover the vast range of scenarios a five-finger hand must handle. RLWRLD’s synthetic data pipeline multiplies a small set of real demonstrations using video generation models like Cosmos-Predict2.
A fine-tuned video model generates new trajectories at scale by varying scene conditions — lighting, surfaces, object positions, and backgrounds.
An inverse dynamics model then labels the generated videos with corresponding actions, and a quality and motion-consistency filter keeps only the synthetic data that follows instructions and obeys physical laws.
RLWRLD said this produces video-action paired synthetic data that genuinely benefits VLA training, rather than just visually convincing outputs. The approach yields roughly a fivefold increase in data volume, translating to a 9.2% improvement in average success rate on the GR-1 Tabletop benchmark.

RLWRLD Also Learns Directly from Human Hands
RLWRLD believes there’s no better instructor for a dexterous robot hand than a human hand. Traditional teleoperation is often too sluggish and imprecise for five-finger manipulation, since conventional controllers can’t replicate the rapid reflexes needed for dynamic tasks like catching or quick regrasping.
The most common alternative, UMI, mounts the robotic end effector onto a human operator, but RLWRLD claims this only works for simple grippers. The company pointed to DexUMI as an attempt to adapt the approach to five-finger hands, but said it falls short in practice due to poor ergonomics, restricted hand movement, and hardware that must be redesigned for each new robot hand.
RLDX takes the reverse approach: capture data from the bare human hand and bridge the kinematic and morphological differences entirely in software, using a retargeting framework purpose-built for five-finger dexterity.
- RLWRLD outlined the pipeline’s four stages:
- Track the human hand and objects in the scene
- Reconstruct the workspace using 3D Gaussian Splatting
- Retarget the motion onto the robot hand
The company said users can deploy this pipeline in simulation to generate VLA training data, producing over 200 demonstrations per hour with further scaling possible through automated augmentations.
RLWRLD’s Three-Stage Training Pipeline
RLDX is trained through a three-stage pipeline, with each stage building on the checkpoint from the previous one. The first stage is pre-training for general manipulation. The model acquires broad manipulation skills across single-arm, dual-arm, and humanoid platforms (many featuring dexterous five-finger hands) using a shared MSAT core paired with per-embodiment encoders and decoders.
The pre-training dataset combines trajectories from diverse real-world datasets with synthetic robot data. RLWRLD randomly drops embodiment tags during training so the model learns both an embodiment-conditioned policy and an embodiment-agnostic one within a single backbone.
Next comes mid-training for target embodiments. Starting from the pre-trained checkpoint, the Memory Module and Physics Module are introduced and initialized from scratch, while existing weights are preserved. Embodiment-specific dexterity data builds temporal and sensory capabilities. Pre-training data is partially recycled to prevent catastrophic forgetting, and synthetic robot data fills gaps for embodiments with limited real data.
Finally, post-training prepares the model for deployment. Imitation learning alone leaves room for improvement in both success rates and motion quality.
Two mechanisms close this gap, corresponding to the two remaining aspects of Context Awareness:
- DAgger (Recovery) focuses training data on the model’s actual failure modes. The model is deployed and corrected whenever it goes out of distribution, and those corrections become new training data. Each iteration shrinks the failure distribution until the error pattern vanishes.
- Progress-Aware RL (Progress-Awareness) uses a separate VLM fine-tuned as a learned progress estimator. Given a trajectory, it predicts how close the policy is to finishing the task. This gives reinforcement learning (RL) a dense, visually-grounded reward signal that steers the policy toward task completion without hand-crafted, task-specific objectives. By reusing batch on-policy data, every rollout is fully leveraged across multiple updates, making
- Real-world reinforcement learning (RL) is now more manageable and cost-effective.
RLWRLD reported that its final policy can complete tasks approximately three times faster than using imitation learning alone.
How does RLDX-1 perform against common benchmarks?
RLDX is available in three versions: RLDX-1-PT (pre-trained checkpoint), RLDX-1-MT-ALLEX, and RLDX-1-MT-DROID (each 8.1B parameters, fine-tuned for their specific platforms).
Running an 8.1B policy in a real-time robot control loop is primarily a challenge of graph optimization and memory management rather than raw computational power. RLWRLD tested RLDX-1-PT in simulation against GR00T N1.5/N1.6 and π₀ [4] / π₀.₅ / π₀-FAST, and also assessed it on the OpenArm real-world benchmark without any platform-specific fine-tuning.
The fine-tuned versions — RLDX-1-MT-ALLEX and RLDX-1-MT-DROID — were then tested on their respective platforms. Each benchmark task is crafted to test a specific aspect of dexterity. RLWRLD compared RLDX-1 against leading baseline VLA models, including π₀.₅ and GR00T N1.6.
On the OpenArm + Inspire 6-DoF hand platform, RLWRLD tested RLDX-1-PT, without OpenArm-specific fine-tuning, to evaluate how well the embodiment-agnostic pre-trained policy adapts to a platform it wasn’t specifically designed for. The benchmark focuses on versatile intelligence, covering object recognition, instruction comprehension, and adaptability to new environments.
RLDX-1 consistently surpasses the baselines on the OpenArm benchmark for versatile intelligence. RLWRLD noted that π₀.₅ outperforms GR00T N1.6 on familiar tasks, but its performance falls below GR00T N1.6 on unfamiliar tasks, suggesting limited ability to generalize to new scenarios.
GR00T N1.6 faces a different challenge. It fails entirely on the object identification task, indicating difficulty with precise instance-level object recognition, according to the company. In contrast, RLDX-1 delivers consistent performance across various task types without failing in any particular area.
These findings show that RLDX-1 not only achieves a higher average success rate but is also more dependable across the wide range of skills needed for real-world humanoid manipulation, RLWRLD stated.
Testing RLDX-1 with humanoids
Using the ALLEX humanoid, RLWRLD designed tasks centered on motion awareness, history awareness, and physical signal awareness, tested with RLDX-1-MT-ALLEX fine-tuned for the platform.
The results reveal a significant performance gap between RLDX-1 and existing VLAs. On tasks requiring specialized functional capabilities, the leading baselines achieve success rates under 30%, while RLDX-1 reaches nearly 90%.
This indicates that current VLA models still face difficulties when a task demands more than basic visual-language understanding, such as monitoring motion, leveraging past interactions, or interpreting physical signals. In contrast, RLDX-1 handles these specialized challenges far more reliably.
RLDX-1-MT-DROID adapts the pre-trained checkpoint to a single-arm Franka Research 3 platform equipped with AnySkin tactile and joint torque sensing. RLWRLD evaluates two memory-dependent tasks (Swap Cup, Shell Game) and two sensory-dependent tasks (Plug Insertion, Egg Pick & Place) that utilize the Memory Module and Physics Module on a non-humanoid robot.
What’s next for RLWRLD
Data needs for each task vary, RLWRLD observed. Some tasks converge quickly with minimal demonstrations; others require more extensive post-training.
Regarding the company’s long-horizon planning capability, RLWRLD’s current experiments show memory-dependent decision-making over short-to-medium interaction periods. Scaling this capability to much longer time frames, such as hour-long interactions, remains a key focus for future development.
The company is also aiming for zero-shot capability. RLDX-1 demonstrates strong instruction comprehension under our current training and adaptation approach compared to other leading VLAs, but its zero-shot generalization as a pre-trained policy is still an area of ongoing research.
RLWRLD also expressed interest in expanding RLDX-1 to video/world modeling. RLDX-1 can be extended toward video/world modeling, where the model learns to predict future visual observations based on language instructions and actions. Such an expansion could provide a stronger foundation for long-horizon planning and action-conditioned imagination in embodied environments, and it represents a promising avenue for future work, said the company.