



Constructing simulators for robots has been a long run problem. Conventional engines require guide coding of physics and excellent 3D fashions. NVIDIA is altering this with DreamDojo, a totally open-source, generalizable robotic world mannequin. As an alternative of utilizing a physics engine, DreamDojo ‘dreams’ the outcomes of robotic actions instantly in pixels.

Scaling Robotics with 44k+ Hours of Human Expertise
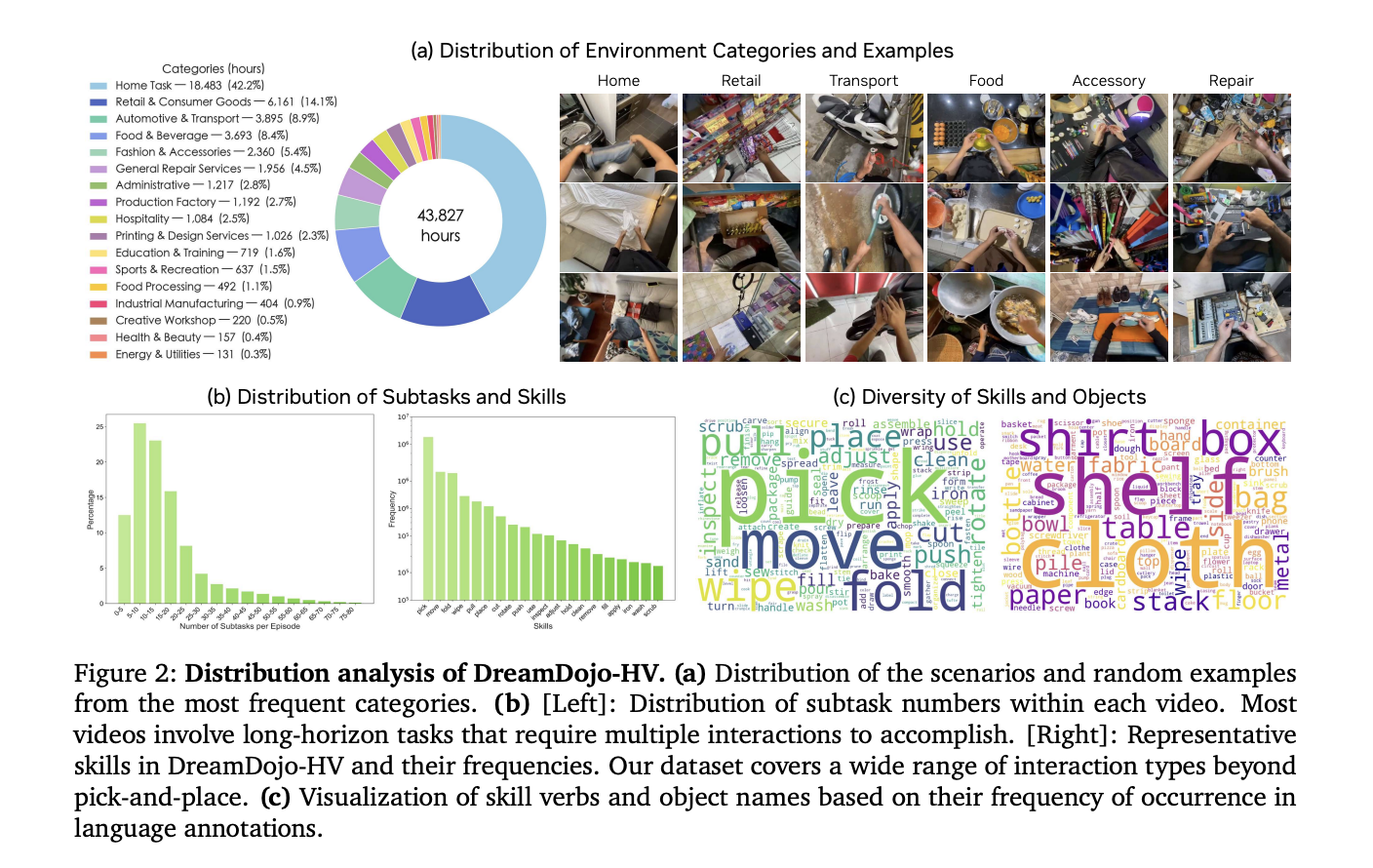
The most important hurdle for AI in robotics is knowledge. Amassing robot-specific knowledge is dear and gradual. DreamDojo solves this by studying from 44k+ hours of selfish human movies. This dataset, known as DreamDojo-HV, is the biggest of its type for world mannequin pretraining.
- It options 6,015 distinctive duties throughout 1M+ trajectories.
- The information covers 9,869 distinctive scenes and 43,237 distinctive objects.
- Pretraining used 100,000 NVIDIA H100 GPU hours to construct 2B and 14B mannequin variants.
People have already mastered complicated physics, resembling pouring liquids or folding garments. DreamDojo makes use of this human knowledge to present robots a ‘common sense’ understanding of how the world works.
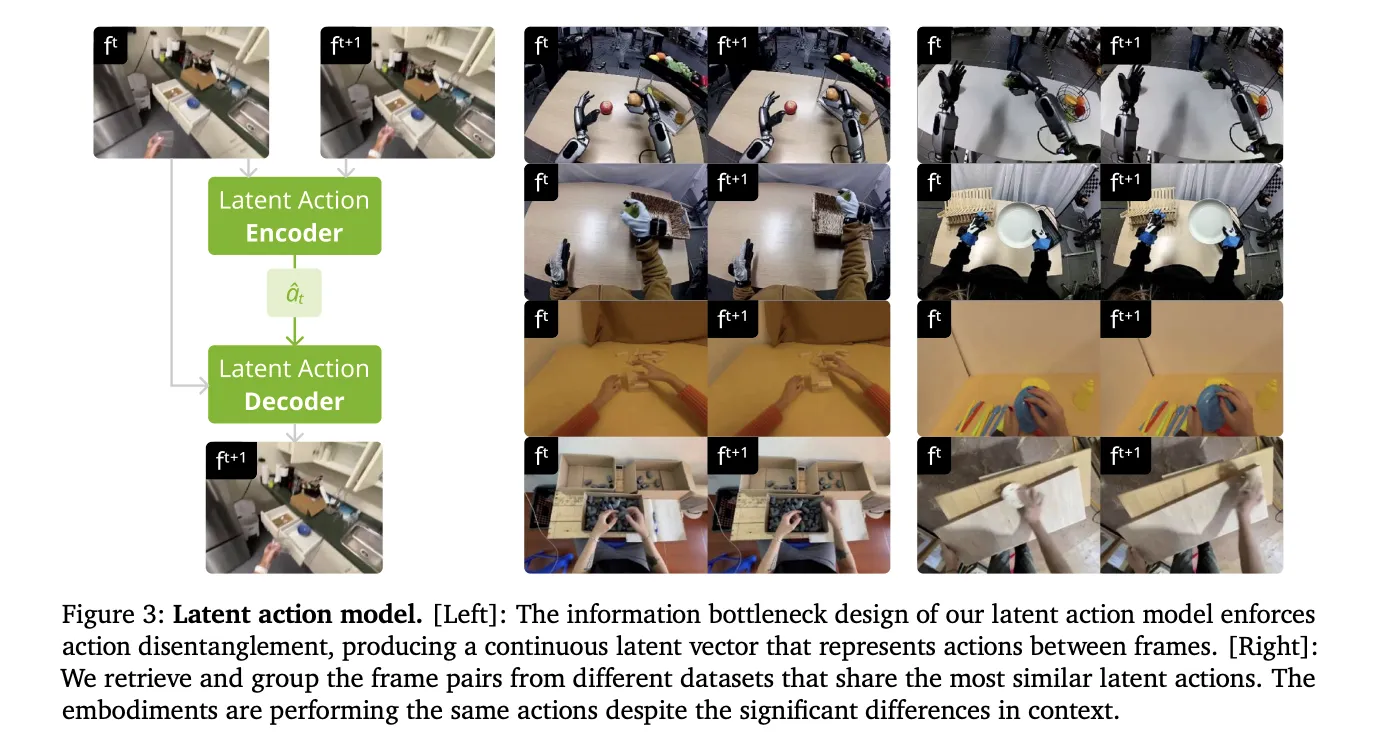
Bridging the Hole with Latent Actions
Human movies shouldn’t have robotic motor instructions. To make these movies ‘robot-readable,’ NVIDIA’s analysis crew launched steady latent actions. This method makes use of a spatiotemporal Transformer VAE to extract actions instantly from pixels.
- The VAE encoder takes 2 consecutive frames and outputs a 32-dimensional latent vector.
- This vector represents probably the most crucial movement between frames.
- The design creates an data bottleneck that disentangles motion from visible context.
- This enables the mannequin to be taught physics from people and apply them to totally different robotic our bodies.
Higher Physics via Structure
DreamDojo is predicated on the Cosmos-Predict2.5 latent video diffusion mannequin. It makes use of the WAN2.2 tokenizer, which has a temporal compression ratio of 4. The crew improved the structure with 3 key options:
- Relative Actions: The mannequin makes use of joint deltas as an alternative of absolute poses. This makes it simpler for the mannequin to generalize throughout totally different trajectories.
- Chunked Motion Injection: It injects 4 consecutive actions into every latent body. This aligns the actions with the tokenizer’s compression ratio and fixes causality confusion.
- Temporal Consistency Loss: A brand new loss operate matches predicted body velocities to ground-truth transitions. This reduces visible artifacts and retains objects bodily constant.
Distillation for 10.81 FPS Actual-Time Interplay
A simulator is simply helpful whether it is quick. Normal diffusion fashions require too many denoising steps for real-time use. NVIDIA crew used a Self Forcing distillation pipeline to unravel this.
- The distillation coaching was performed on 64 NVIDIA H100 GPUs.
- The ‘student’ mannequin reduces denoising from 35 steps right down to 4 steps.
- The ultimate mannequin achieves a real-time velocity of 10.81 FPS.
- It’s secure for steady rollouts of 60 seconds (600 frames).
Unlocking Downstream Purposes
DreamDojo’s velocity and accuracy allow a number of superior functions for AI engineers.
1. Dependable Coverage Analysis
Testing robots in the true world is dangerous. DreamDojo acts as a high-fidelity simulator for benchmarking.
- Its simulated success charges present a Pearson correlation of (Pearson 𝑟=0.995) with real-world outcomes.
- The Imply Most Rank Violation (MMRV) is simply 0.003.
2. Mannequin-Based mostly Planning
Robots can use DreamDojo to ‘look ahead.’ A robotic can simulate a number of motion sequences and decide the perfect one.
- In a fruit-packing activity, this improved real-world success charges by 17%.
- In comparison with random sampling, it offered a 2x enhance in success.
3. Stay Teleoperation
Builders can teleoperate digital robots in actual time. NVIDIA crew demonstrated this utilizing a PICO VR controller and a neighborhood desktop with an NVIDIA RTX 5090. This enables for protected and fast knowledge assortment.
Abstract of Mannequin Efficiency
| Metric | DREAMDOJO-2B | DREAMDOJO-14B |
| Physics Correctness | 62.50% | 73.50% |
| Motion Following | 63.45% | 72.55% |
| FPS (Distilled) | 10.81 | N/A |
NVIDIA has launched all weights, coaching code, and analysis benchmarks. This open-source launch lets you post-train DreamDojo by yourself robotic knowledge right now.
Key Takeaways
- Large Scale and Variety: DreamDojo is pretrained on DreamDojo-HV, the biggest selfish human video dataset so far, that includes 44,711 hours of footage throughout 6,015 distinctive duties and 9,869 scenes.
- Unified Latent Motion Proxy: To beat the dearth of motion labels in human movies, the mannequin makes use of steady latent actions extracted through a spatiotemporal Transformer VAE, which serves as a hardware-agnostic management interface.
- Optimized Coaching and Structure: The mannequin achieves high-fidelity physics and exact controllability by using relative motion transformations, chunked motion injection, and a specialised temporal consistency loss.
- Actual-Time Efficiency through Distillation: By a Self Forcing distillation pipeline, the mannequin is accelerated to 10.81 FPS, enabling interactive functions like reside teleoperation and secure, long-horizon simulations for over 1 minute.
- Dependable for Downstream Duties: DreamDojo capabilities as an correct simulator for coverage analysis, displaying a 0.995 Pearson correlation with real-world success charges, and may enhance real-world efficiency by 17% when used for model-based planning.
Take a look at the Paper and Codes. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.
