



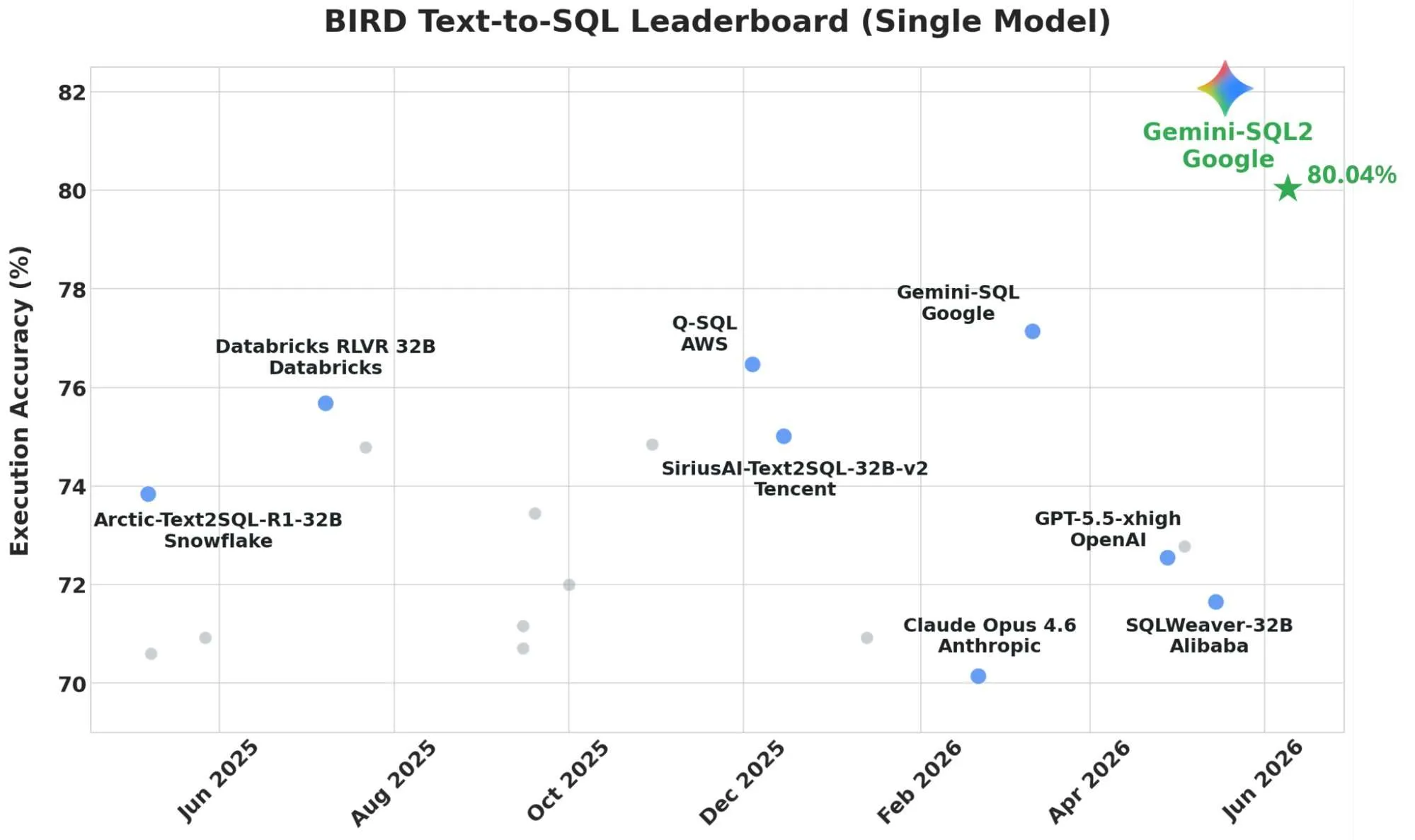
Google Research team has unveiled Gemini-SQL2 on X, presenting it as a significant progress in text-to-SQL performance powered by Gemini 3.1 Pro. On the BIRD Text-to-SQL Leaderboard (Single Model track), the system recorded 80.04% execution accuracy. Google’s visualization positions it above its own Gemini-SQL, which previously held the highest spot. The measurement verifies whether the produced SQL runs and delivers the correct results, rather than just checking for syntactic appearance.
Gemini-SQL2
Gemini-SQL2 is a text-to-SQL capability, not a standalone foundation model release. It converts natural language questions into what Google refers to as ‘execution-ready SQL queries.’ The capability is built on Gemini 3.1 Pro.
According to the announcement on X, “data subtlety & complex business contexts make generating accurate SQL from natural language notoriously hard.” The X Post also mentioned that “improved SQL understanding can elevate natural language skills across Google’s data services.” This suggests potential integration targets like BigQuery Studio, AlloyDB AI, and Cloud SQL Studio, which already ship Gemini-based SQL generation. Google has not yet confirmed which products will receive Gemini-SQL2.
Benchmarks
BIRD (BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation) is an industry standard for this task. It contains 12,751 question-SQL pairs across 95 databases spanning 37 professional domains, totaling 33.4GB. The databases include dirty values and require external knowledge grounding, unlike earlier benchmarks such as Spider.
BIRD measures execution accuracy (EX): the produced SQL must run and yield results matching the gold query. Google confirmed this explicitly. “Per the BIRD benchmark, which measures execution-verified accuracy, GeminiSQL-2’s SQL doesn’t just look right, it also runs successfully.”
The Single Trained Model Track restricts preprocessing, retrieval, and agentic frameworks that ensembles use to boost scores. It measures the model’s core text-to-SQL ability. Google Cloud’s prior record on this track, reported November 15, 2025, was 76.13. Google benchmarks human performance at 92.96, leaving a 12.92-point gap from 80.04.
How the Leaderboard Stacks Up
Google’s chart from the X post shows Gemini-SQL2 ahead of eight named competitors, alongside several unnamed entries. Only the 80.04% figure is specified in the text. The remaining values are estimated from the chart’s positioning, with dates reflecting each entry’s horizontal placement.
| System | Organization | BIRD Execution Accuracy (Single Model) | Chart Date |
|---|---|---|---|
| Gemini-SQL2 | 80.04% (stated) | Jun 2026 | |
| Gemini-SQL | ~77.2% | Mar 2026 | |
| Q-SQL | AWS | ~76.5% | Dec 2025 |
| Databricks RLVR 32B | Databricks | ~75.7% | Jul 2025 |
| SiriusAI-Text2SQL-32B-v2 | Tencent | ~75.0% | Dec 2025 |
| Arctic-Text2SQL-R1-32B | Snowflake | ~73.9% | Jun 2025 |
| GPT-5.5-xhigh | OpenAI | ~72.5% | Apr 2026 |
| SQLWeaver-32B | Alibaba | ~71.7% | May 2026 |
| Claude Opus 4.6 | Anthropic | ~70.1% | Feb 2026 |
Two patterns are visible. Google now holds the top two named positions, Gemini-SQL2 and Gemini-SQL. A number of specialized 32B SQL models also outperform some general frontier models on this chart.
Use Cases with Examples
- Self-service analytics: A revenue manager requests monthly recurring revenue by region, for accounts that churned within 90 days of upgrade. This requires joins, window logic, and date arithmetic. Execution-verified generation catches SQL that runs but returns wrong rows.
- Data engineering drafts: Developers can draft BigQuery transformations from English, then review rather than write from scratch. Google’s November 2025 work identified schema understanding
Gemini-SQL2 Debut: Community Reception Dashboard
Confirmed public engagement on Google Research’s announcement post • first ~3 hours • Jun 12, 2026
BIRD Single-Model Leaderboard • Execution Accuracy
Platform Engagement Summary
X / Twitter (main post)
Views144.4K
Likes2,800
Reposts267
Bookmarks1,300
Replies64
Engagement rate3.1%
LinkedIn (main post)
Reactions349+
Comments12
Reposts27
Reception signal
Bookmark-plus-like to reply ratio on X. A strong save rate coupled with relatively few replies generally signals approval rather than controversy. Comment-level sentiment couldn’t be assessed yet; replies were still loading at the time of capture.
Implementation Pattern
Google hasn’t released a Gemini-SQL2 model identifier or API so far. The schema-grounded approach shown here works with existing Gemini models through the google-genai SDK. When Gemini-SQL2 becomes available, simply update the model string.
from google import genai
client = genai.Client() # picks up GEMINI_API_KEY from environment
schema = """
CREATE TABLE orders (
order_id INTEGER, customer TEXT, region TEXT,
amount REAL, status TEXT, created_at DATE
);
"""
question = "Show total paid order amount by region for 2026, sorted highest first."
prompt = f"""You are a text-to-SQL system.
Schema:{schema}
Question: {question}
Return a single executable SQLite query only. No commentary."""
resp = client.models.generate_content(
model="gemini-3.1-pro-preview", # the base model referenced in the announcement; replace with a Gemini-SQL2 ID once available
contents=prompt,
)
print(resp.text)
In production, add execution validation. Run the generated SQL, catch any errors, and retry by appending the error message back into the prompt. This retry loop aligns with how BIRD’s execution accuracy score is calculated.
Key Takeaways
- Google reports Gemini-SQL2 achieving 80.04% execution accuracy on the BIRD single-model leaderboard.
- The feature runs on Gemini 3.1 Pro and is designed for “execution-ready SQL” rather than merely plausible SQL.
- According to Google’s chart, Gemini-SQL2 and Gemini-SQL occupy the top two listed positions; human performance sits at 92.96%.
- No API, model card, technical report, or product integration specifics have been shared yet.
MARKTECHPOST Visual Explainer
Text-to-SQL Playground
The Gemini-SQL2 model just earned 80.04% on the BIRD benchmark (single-model category). Choose a question, review the generated SQL, then execute it against a live in-browser dataset.
1 • Ask in natural language
2 • Generated SQL
Choose a question above to generate SQL.
CREATE TABLE orders ( order_id INTEGER, customer TEXT, region TEXT, amount REAL, status TEXT, created_at DATE ); -- 12 sample rows loaded in this browser
Execution accuracy means the SQL must both run successfully AND return the correct rows.
Explore the full details here. Also, follow us on Twitter and make sure to join our 150k+ ML SubReddit and subscribe to our Newsletter! Already on Telegram? You can join us there too.
Interested in partnering with us to promote your GitHub repo, Hugging Face page, product launch, webinar, and more? Get in touch with us
