



For years, the pc imaginative and prescient neighborhood has operated on two separate tracks: generative fashions (which produce photographs) and discriminative fashions (which perceive them). The belief was easy — fashions good at making footage aren’t essentially good at studying them. A brand new paper from Google, titled “Image Generators are Generalist Vision Learners” (arXiv:2604.20329), printed April 22, 2026, blows that assumption aside.
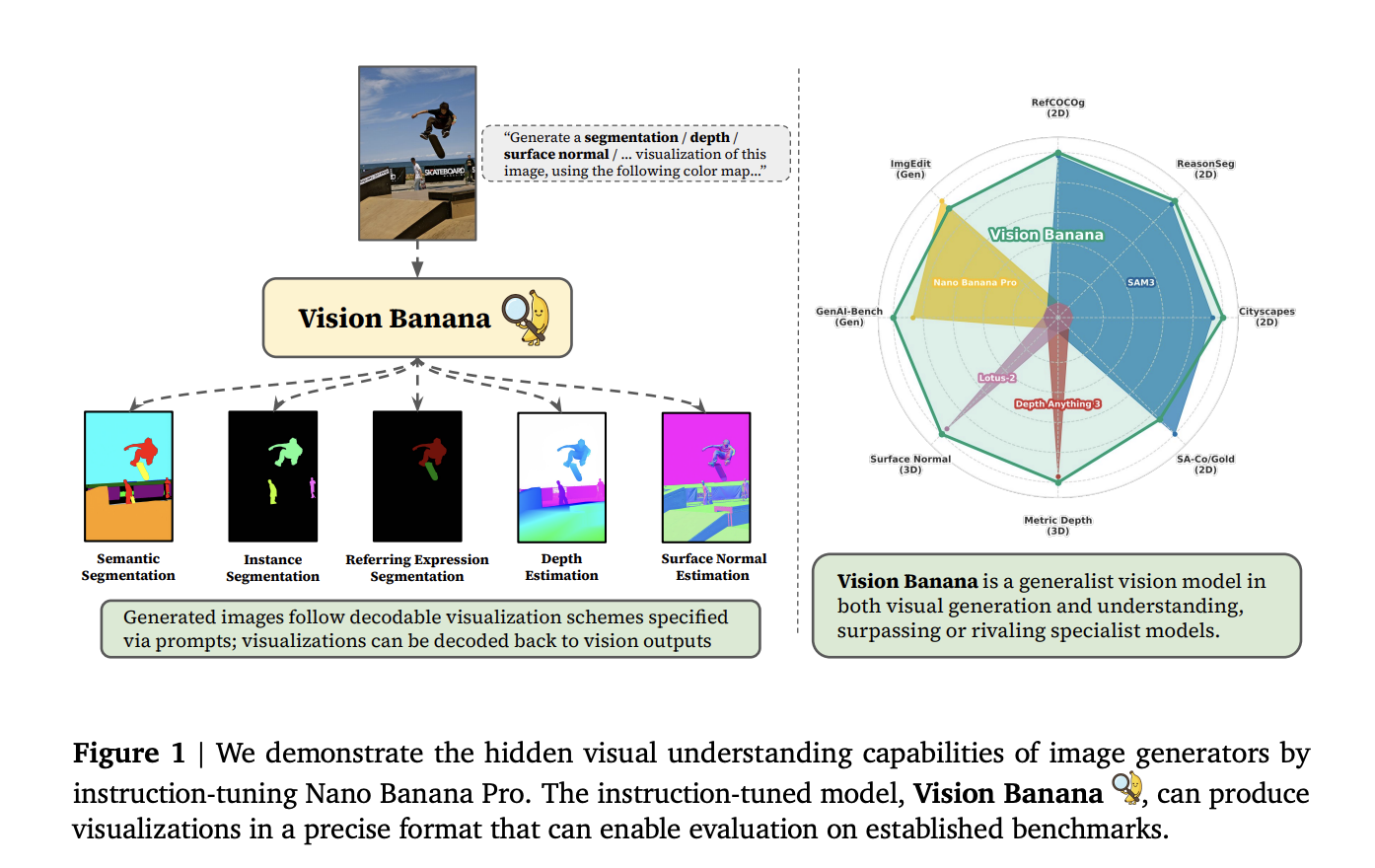
A workforce of Google DeepMind researchers launched Imaginative and prescient Banana, a single unified mannequin that surpasses or matches state-of-the-art specialist methods throughout a variety of visible understanding duties — together with semantic segmentation, occasion segmentation, monocular metric depth estimation, and floor regular estimation — whereas concurrently retaining the unique picture technology capabilities of its base mannequin.
The LLM Analogy That Adjustments The whole lot
For those who’ve labored with massive language fashions, you already perceive the two-phase playbook: first, pretrain a base mannequin on huge textual content information utilizing a generative goal, then apply instruction-tuning to align it for downstream duties. The pretraining part is the place the mannequin develops a wealthy inside illustration of language that may be repurposed for nearly something.

The Google workforce’s core declare is that picture technology coaching performs the very same foundational position for imaginative and prescient. Their base mannequin, Nano Banana Professional (NBP), is Google’s state-of-the-art picture generator. By performing a light-weight instruction-tuning move — mixing a small proportion of laptop imaginative and prescient process information at a really low ratio into NBP’s unique coaching combination — they created Imaginative and prescient Banana. The important thing perception: producing photorealistic photographs implicitly requires a mannequin to know geometry, semantics, depth, and object relationships. Imaginative and prescient Banana learns to categorical that latent information in measurable, decodable codecs.
Critically, no coaching information from any of the analysis benchmarks is included within the instruction-tuning combination — making certain that every one outcomes replicate true generalist functionality slightly than in-domain memorization.
How It Works: Notion as Picture Era
Relatively than including specialised decoder heads or regression modules for every process, all imaginative and prescient process outputs are parameterized as RGB photographs. The mannequin is instruction-tuned to supply visualizations that comply with exact, invertible shade schemes — which means the generated photographs may be decoded again into quantitative outputs for benchmark analysis.
The analysis workforce recognized three key benefits of this technique. First, it helps all kinds of duties with a single unified mannequin — after instruction-tuning, solely the immediate adjustments, not the weights. Second, it requires comparatively little new coaching information, since instruction-tuning is solely instructing the mannequin find out how to format laptop imaginative and prescient outputs as RGB. Third, it helps the mannequin retain its unique picture technology capabilities, because the outputs are merely new RGB photographs.
For semantic segmentation, the mannequin is prompted with directions corresponding to: “Generate a segmentation visualization of this image, using the color mapping: {‘cat’: ‘red’, ‘background’: ‘yellow’}.” Every pixel is coloured by its predicted class, and since shade assignments are specified within the immediate, no mounted label vocabulary is required.
For occasion segmentation, because the variety of cases is unknown upfront, Imaginative and prescient Banana makes use of a per-class inference technique — working a separate move per class and dynamically assigning distinctive colours to every occasion. Masks are recovered by clustering pixels with comparable colours utilizing a threshold.
Metric depth estimation makes use of a bijective mapping between unbounded metric depth values in [0, ∞) and bounded RGB values in [0, 1]³. An influence remodel (form parameter λ = −3, scale parameter c = 10/3) first “curves” metric depth values, that are then encoded as a false-color visualization that traverses the perimeters of the RGB dice, following the construction of a 3D Hilbert curve. This remodel is strictly invertible, so the generated depth picture decodes cleanly again to bodily metric distances. Crucially, no digicam parameters — neither intrinsics nor extrinsics — are required at coaching or inference time. The mannequin infers absolute scale purely from visible cues and world information embedded throughout pretraining. The depth coaching information can also be completely artificial, generated from simulation rendering engines, with zero real-world depth information used.
For floor regular estimation, the mapping is extra direct: floor normals are unit vectors (x, y, z) starting from −1.0 to 1.0, which map naturally to RGB channels. Dealing with-left normals encode as pinkish-red; facing-up normals encode as gentle inexperienced; normals pointing towards the digicam encode as gentle blue/purple.
The Numbers: Beating Specialists at Their Personal Sport
Imaginative and prescient Banana’s outcomes throughout benchmarks — all in zero-shot switch settings, the place the mannequin has by no means seen any coaching information from the evaluated datasets — are important:
- Semantic segmentation on Cityscapes val: mIoU of 0.699, in comparison with SAM 3’s 0.652 — a 4.7-point achieve.
- Referring expression segmentation on RefCOCOg UMD val: cIoU of 0.738, edging out SAM 3 Agent’s 0.734.
- Reasoning segmentation on ReasonSeg val: gIoU of 0.793, beating SAM 3 Agent’s 0.770 — and notably surpassing even non-zero-shot strategies educated on in-domain information, together with X-SAM.
- Occasion segmentation on SA-Co/Gold: pmF1 of 0.540, on par with DINO-X (0.552), and forward of Gemini 2.5 (0.461), APE-D (0.369), and OWLv2 (0.420) below zero-shot switch.
- Metric depth estimation: common δ1 of 0.882 throughout six main benchmarks; on the 4 datasets the place Depth Something V3 was evaluated (NYU, ETH3D, DIODE-Indoor, KITTI), Imaginative and prescient Banana scores 0.929 versus Depth Something V3’s 0.918 — whereas utilizing zero real-world coaching information and no digicam parameters.
- Floor regular estimation: common imply angle error of 18.928° throughout 4 datasets, in comparison with Lotus-2’s 19.642°. On indoor datasets particularly, Imaginative and prescient Banana achieves the bottom imply angle error (15.549°) and lowest median angle error (9.300°) amongst all in contrast strategies.
On generative benchmarks, Imaginative and prescient Banana holds its personal towards its base mannequin: it achieves a 53.5% win charge towards Nano Banana Professional on GenAI-Bench (text-to-image), and a 47.8% win charge on ImgEdit (picture modifying), the place Nano Banana Professional scores 52.2%. General, the outcomes affirm that light-weight instruction-tuning doesn’t degrade the mannequin’s generative capabilities.
Key Takeaways
- Picture technology pretraining is a generalist imaginative and prescient learner: Simply as LLM pretraining unlocks emergent language understanding, Google’s analysis exhibits that coaching on picture technology naturally develops highly effective inside visible representations that switch to notion duties like segmentation, depth estimation, and floor regular estimation.
- Imaginative and prescient Banana beats specialist fashions with out specialist structure: Constructed by light-weight instruction-tuning of Nano Banana Professional, Imaginative and prescient Banana surpasses SAM 3 on three segmentation benchmarks, Depth Something V3 on metric depth estimation (δ1: 0.929 vs 0.918), and Lotus-2 on floor regular estimation (imply angle error: 18.928° vs 19.642°) — all in zero-shot switch settings.
- All imaginative and prescient duties are reframed as picture technology: By parameterizing imaginative and prescient process outputs as RGB photographs with decodable shade schemes, Imaginative and prescient Banana makes use of a single set of weights and prompt-only switching throughout semantic segmentation, occasion segmentation, depth estimation, and floor regular estimation — no task-specific modules required.
- Metric depth estimation works with none digicam parameters or real-world information: Utilizing a bijective energy remodel mapping depth values to RGB shade house, Imaginative and prescient Banana infers absolute metric scale purely from visible context — requiring neither digicam intrinsics nor extrinsics, and educated completely on artificial information from simulation engines.
- Picture technology can function a common interface for imaginative and prescient: Analogous to how textual content technology unifies language duties, picture technology could grow to be the common output interface for laptop imaginative and prescient, pointing towards a paradigm shift the place generative imaginative and prescient pretraining powers true Foundational Imaginative and prescient Fashions for each technology and understanding.
Try the Paper and Challenge Web page right here. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 130k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as properly.
Have to accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so forth.? Join with us

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling advanced datasets into actionable insights.