



Standardized checks can let you know whether or not a pupil is aware of calculus or can parse a passage of textual content. What they can’t reliably let you know is whether or not that pupil can resolve a disagreement with a teammate, generate genuinely unique concepts underneath strain, or critically dismantle a flawed argument. These are the so-called sturdy abilities — collaboration, creativity, and significant pondering — and for many years they’ve resisted rigorous, scalable measurement. A brand new analysis from Google Analysis proposes a technically novel answer known as Vantage: orchestrated massive language fashions that may each simulate genuine group interplay and rating the outcomes with accuracy rivaling human skilled raters.

The Core Drawback: Ecological Validity vs. Psychometric Rigor
To know why that is technically attention-grabbing, it helps to grasp the measurement paradox the analysis staff was making an attempt to crack. Measuring sturdy abilities successfully requires two conflicting properties. On one hand, the evaluation wants ecological validity — it ought to really feel like a real-world situation, as a result of that’s exactly the context wherein these abilities are exercised. However, it wants psychometric rigor: standardized situations, reproducibility, and controllable stimuli in order that scores are comparable throughout test-takers.
Earlier large-scale efforts, just like the PISA 2015 Collaborative Drawback Fixing evaluation, tried to resolve this by having topics work together with scripted simulated teammates through multiple-choice questions. That ensures management however sacrifices authenticity. Human-to-human assessments do the alternative. LLMs, the analysis staff argues, are uniquely positioned to fulfill each necessities concurrently — they will produce naturalistic, open-ended conversational interactions whereas nonetheless being steered programmatically towards particular evaluation objectives.
The Government LLM: A Coordination Layer Over AI Brokers
Essentially the most technically distinctive contribution of this analysis is the Government LLM structure. Moderately than spawning a number of unbiased LLM brokers — one per AI teammate — the system makes use of a single LLM to generate responses for all AI individuals within the dialog. This issues for 2 causes.
First, it allows coordination. The Government LLM has entry to the identical pedagogical rubric that may later be used to judge the human participant. It makes use of this rubric not simply passively, however actively — steering the dialog towards eventualities that elicit proof of particular abilities. For instance, if the goal dimension is Battle Decision, the Government LLM could instruct one in every of its AI personas to introduce a disagreement and maintain it till the human participant demonstrates (or fails to reveal) a conflict-resolution technique. That is functionally analogous to how a computerized adaptive take a look at (CAT) dynamically adjusts merchandise problem based mostly on a test-taker’s working efficiency — besides right here, the ‘items’ are turns in a reside dialog.
Second, the Unbiased Brokers baseline (separate LLMs with no coordination) proved demonstrably weaker. With out steering, conversations merely may not produce the suitable proof — if staff members naturally agree, there isn’t a battle to resolve, and the evaluation learns nothing about that sub-skill.
Gemini 2.5 Professional was used because the mannequin underlying the Government LLM for the principle collaboration experiments, whereas Gemini 3 powered the creativity and significant pondering modules.
What the Experiments Really Present
The analysis staff recruited 188 individuals aged 18–25, English native audio system based mostly in the USA, through the Prolific platform. Every participant generated two conversations for a complete of 373 transcripts (three had been filtered because of technical points). All individuals labored via collaborative duties — both a science experiment design or a structured debate — with a gaggle of AI personas, for half-hour per dialog.
Two sub-skills of collaboration had been evaluated: Battle Decision (CR) and Undertaking Administration (PM). Conversations had been rated each by two human pedagogical raters from New York College and by an AI Evaluator (Gemini 3.0), which scored every participant flip 20 occasions. A flip was declared NA if any one of many 20 predictions returned NA; in any other case, the ultimate label was essentially the most frequent non-NA stage among the many 20 runs. A regression mannequin — linear for scores, logistic for NA selections — was then skilled on these turn-level labels to provide a conversation-level rating, with efficiency evaluated utilizing leave-one-out cross-validation.
The primary outcomes are compelling on a number of fronts. Flip-level and conversation-level proof charges for skill-relevant conduct had been considerably larger within the Government LLM situations than within the Unbiased Brokers situation throughout each sub-skills. Dialog-level info charges reached 92.4% for Undertaking Administration and 85% for Battle Decision when the skill-matched Government LLM was used. Notably, merely telling individuals to deal with a ability had no important impact on proof charges (all p > 0.6), confirming that the steering should come from the AI facet.
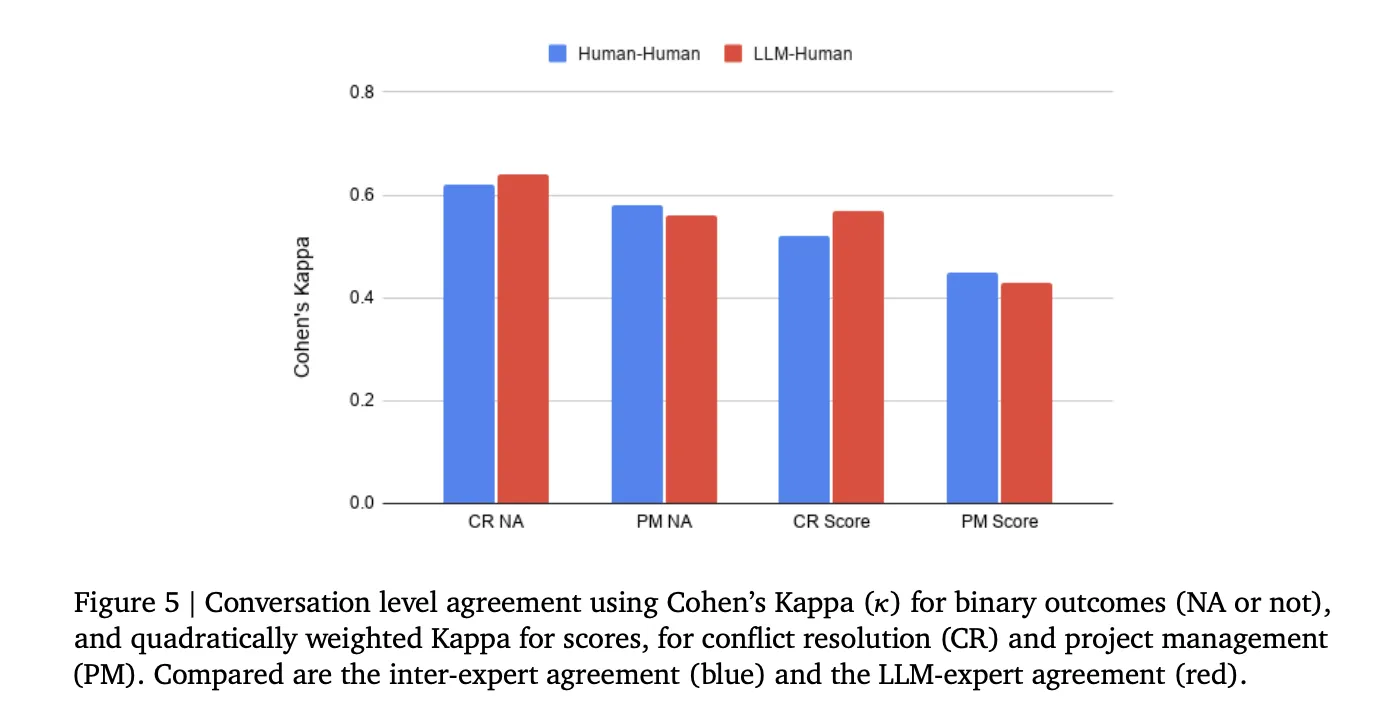
On scoring accuracy, inter-rater settlement between the AI Evaluator and human consultants — measured with Cohen’s Kappa — was corresponding to inter-human settlement, which ranged from reasonable (κ = 0.45–0.64) throughout each abilities and each scoring duties.
Simulation as a Growth Sandbox
One virtually helpful discovering for ML engineers constructing related programs is the validation of LLM-based simulation as a stand-in for human topics throughout protocol growth. The analysis staff used Gemini to simulate human individuals at recognized ability ranges (1–4 on every rubric dimension), then measured restoration error — the imply absolute distinction between the ground-truth stage and the autorater’s inferred stage. The Government LLM produced considerably decrease restoration error than Unbiased Brokers for each CR and PM. Qualitative patterns within the simulated information intently matched these from actual human conversations, suggesting that rubric-based simulation can de-risk evaluation design earlier than costly human information assortment.
Proof Charges Prolong Throughout Creativity and Important Considering
For creativity and significant pondering, preliminary proof charges had been evaluated utilizing simulated topics. The outcomes present the Government LLM outperforming Unbiased Brokers throughout all 8 dimensions examined — all six creativity dimensions (Fluidity, Originality, High quality, Constructing on Concepts, Elaborating, and Choosing) and each vital pondering dimensions (Interpret and Analyze; Consider and Choose) — with all variations statistically important. The analysis staff famous that human score assortment for these two abilities is ongoing and outcomes will probably be shared in future work, however the simulation outcomes recommend the Government LLM strategy generalizes past collaboration.
Creativity Scoring at 0.88 Pearson Correlation
In a separate partnership with OpenMic, an establishment constructing AI-powered sturdy abilities evaluation instruments, the analysis staff evaluated their Gemini-based creativity autorater on advanced multimedia duties accomplished by 280 highschool college students. The duties concerned designing a information section based mostly on a brief story, together with producing character interview questions. Critically, 100 submissions had been used first to refine the Gemini immediate and the skilled pedagogical rubrics, whereas the remaining 180 held-out submissions had been used for the ultimate accuracy analysis. Rubric-based scoring by OpenMic consultants and the autorater agreed at Cohen’s Kappa = 0.66 (good settlement) on the merchandise stage. Extra strikingly, when general submission scores had been in contrast, the Pearson correlation between autorater and human skilled totals was 0.88 — a stage of settlement that’s tough to attain even between human raters on subjective artistic duties.
Closing the Suggestions Loop
Past scoring, Vantage surfaces outcomes to customers via a quantitative abilities map displaying competency ranges throughout all abilities and sub-skills, with the choice to drill down into particular excerpts from the dialog that substantiate every numeric rating. This makes the proof for the evaluation clear and actionable — a significant design consideration for anybody constructing related analysis pipelines the place interpretability of automated scores issues.
Key Takeaways
- A single ‘Executive LLM’ outperforms a number of unbiased brokers for ability evaluation: Moderately than working one LLM per AI teammate, Google’s Vantage makes use of a single coordinating LLM that generates responses for all AI individuals. This permits it to actively steer conversations utilizing a pedagogical rubric — introducing conflicts, pushing again on concepts, or creating planning bottlenecks — to attract out observable proof of particular abilities which may by no means floor naturally.
- LLM-based scoring is now on par with human skilled raters: The AI Evaluator’s settlement with human raters was corresponding to the settlement between two human consultants themselves, who solely reached reasonable Cohen’s Kappa (0.45–0.64) even after a number of calibration rounds. This positions automated LLM scoring as a genuinely scalable various to costly human annotation for advanced, open-ended conversational duties.
- Telling customers to deal with a ability does nothing — the steering has to return from the AI facet: Contributors who had been explicitly instructed to concentrate to battle decision or undertaking administration confirmed no statistically important enchancment in proof charges (all p > 0.6) in comparison with these given no directions. Solely the Government LLM’s energetic steering produced measurably richer evaluation information.
- LLM simulation can function a low-cost sandbox earlier than working research with actual people: By simulating individuals at recognized ability ranges and measuring how precisely the system recovered these ranges, the analysis staff validated their evaluation protocol with out burning via costly human topic budgets. Simulated and actual dialog patterns had been qualitatively related, making this a sensible strategy for iterating on rubrics and prompts early in growth.
- AI creativity scoring achieved 0.88 Pearson correlation with human consultants on actual pupil work: In a real-world take a look at with 180 held-out highschool pupil submissions, a Gemini-based autorater matched human skilled scores at a Pearson correlation of 0.88 on general creativity evaluation — demonstrating that automated scoring of advanced, subjective, multimedia duties is not only theoretically attainable however empirically validated.
Try the Paper and Technical particulars. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 130k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as nicely.
Must associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so on.? Join with us

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking advanced datasets into actionable insights.