Throughout this guide, you’ll explore how to create a text clustering system by merging large language model embeddings with HDBSCAN—a density-based clustering method—to automatically identify topics within unlabeled text collections.
Key areas we’ll address:
- How to produce text embeddings from raw documents using a pre-trained sentence-transformers model.
- How to lower the dimensionality of those embeddings using UMAP to get them ready for clustering.
- How to leverage HDBSCAN to automatically detect topic clusters and display the outcomes visually.
Clustering Unstructured Text with LLM Embeddings and HDBSCAN
Overview
The present wave of Generative AI tends to revolve around chat interfaces and prompt engineering, yet the usefulness of large language models, commonly referred to as LLMs, extends well beyond these areas. In fact, one of their most impactful downstream capabilities is converting raw, unstructured, and often messy text into meaningful numerical representations known as embeddings. Once we have these representations, we can apply them to numerous machine learning tasks—clustering being a prime example.
Specifically, embeddings can be paired with sophisticated, density-based clustering algorithms such as HDBSCAN, which enables the uncovering of latent topics, patterns, or categories within your text document collection—all without requiring any pre-existing labels.
This article walks you through building a text clustering pipeline from the ground up. We’ll work with an openly accessible dataset of text samples, alongside an open-source LLM fine-tuned for embedding generation—commonly referred to as an embedding model. As a bonus, we’ll take advantage of free, modern Python libraries that offer ready-made implementations of clustering algorithms like HDBSCAN.
Detailed Walkthrough
To begin, let’s set up the essential Python libraries we’ll be relying on:
- Sentence transformers, for loading a pre-trained LLM from Hugging Face to generate embeddings — you’ll need a Hugging Face access token (API key) to download the model.
- Umap-learn, for performing dimensionality reduction on the embeddings.
Additionally, if you’re running things in a local IDE rather than a cloud-based notebook and don’t already have scikit-learn and pandas installed, you may need to add those as well.
!pip install sentence–transformers umap–learn |
Now we move into the coding phase by sourcing some fresh data. The fetch_20newsgroups function—which retrieves a collection of categorized news article texts—will handle this. It’s worth noting that although the dataset comes with labels, we’ll intentionally discard them, since the goal is to cluster these documents into similarity-based groups as if we had no prior knowledge of their categories. We also trim the dataset down to 150 samples, which is sufficient for demonstration purposes.
import pandas as pd from sklearn.datasets import fetch_20newsgroups
# Fetching a highly targeted subset of data (~150-200 docs) categories = [‘sci.space’, ‘sci.med’, ‘rec.autos’] newsgroups = fetch_20newsgroups The next step is to derive embeddings from the raw text data. For this purpose, we load the
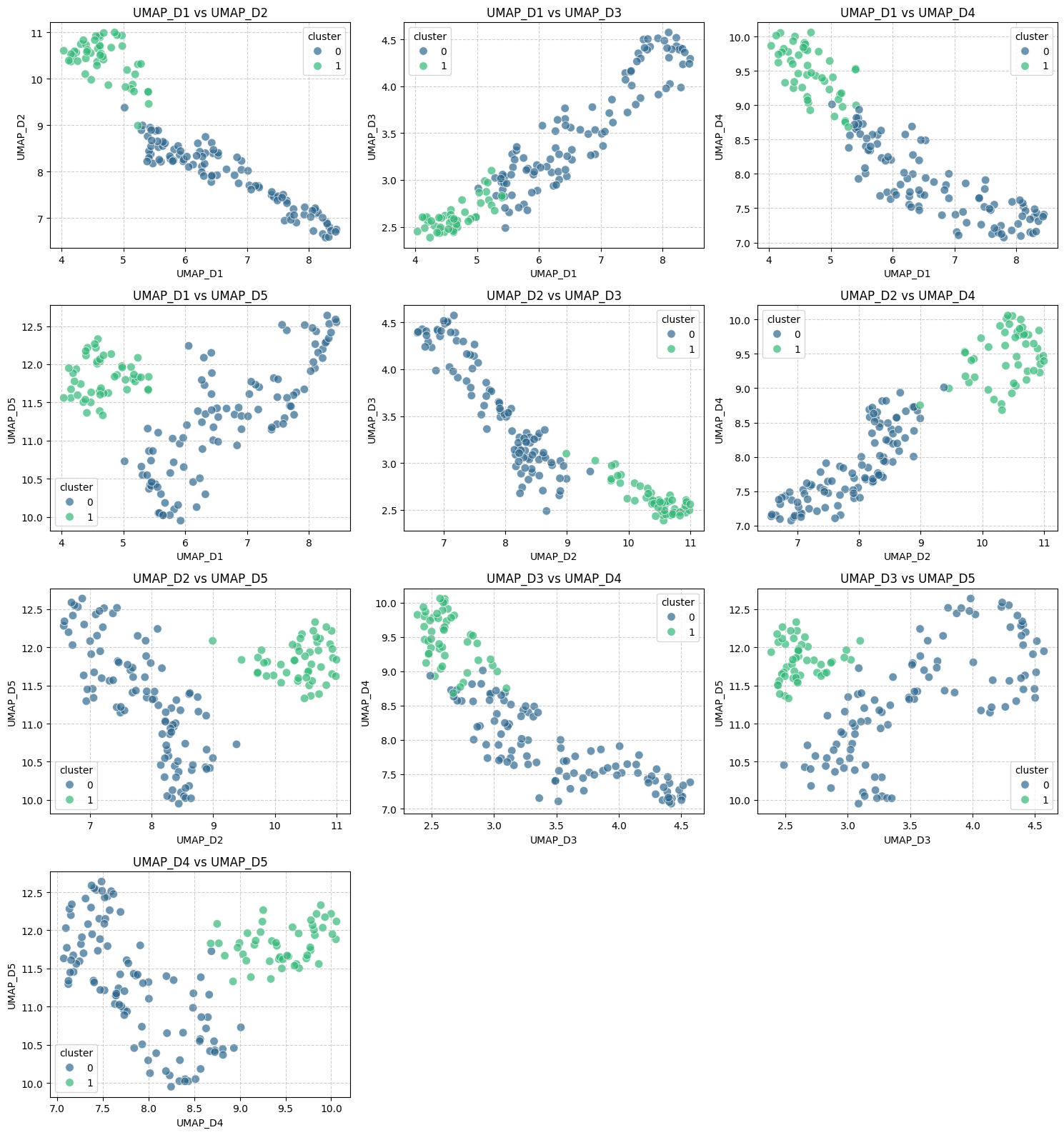
With the embeddings in hand, we now turn to dimensionality reduction. We employ UMAP (Uniform Manifold Approximation and Projection) to project the high-dimensional vectors into a lower-dimensional space. This makes it possible to visualize the data and can enhance clustering performance.
Next, we apply HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) to identify clusters within the reduced embeddings. Unlike some other clustering methods, HDBSCAN does not require specifying the number of clusters beforehand and can detect outliers automatically.
Finally, we visualize the clusters in a 2D scatter plot, coloring each point according to its assigned cluster label.
Since the original embedding dimension is far too great for effective clustering, we can now leverage a dimensionality reduction method by employing the UMAP algorithm from the previously installed library:
At this point, our numeric embedding vectors corresponding to the news articles are composed of merely five dimensions (features). Let’s verify whether this streamlined representation remains expressive enough to produce meaningful clusters by applying the HDBSCAN algorithm — a density-based clustering technique:
|