



If you’ve ever run reinforcement learning (RL) post-training on a language model — whether for math reasoning, code generation, or any task you can verify automatically — you’ve likely found yourself watching a progress bar crawl along while your GPU cluster chews through rollout generation. Now, a team of NVIDIA researchers has come up with a clean solution: they’ve woven speculative decoding directly into the RL training loop itself, and they’ve done it without altering the target model’s output distribution in any way.
The research team embedded speculative decoding straight into NeMo RL v0.6.0 using a vLLM backend, achieving lossless acceleration of the rollout phase at both 8B parameters and at a projected 235B scale. The NeMo RL v0.6.0 update now officially includes speculative decoding as a supported feature, along with the SGLang backend, the Muon optimizer, and YaRN long-context training.
Why Rollout Generation Is the Bottleneck
To see why this matters, it helps to look at how a typical synchronous RL training step is structured. In NeMo RL, every training step consists of five phases: data loading, weight synchronization and backend setup (prepare), rollout generation (gen), log-probability recomputation (logprob), and policy optimization (train).

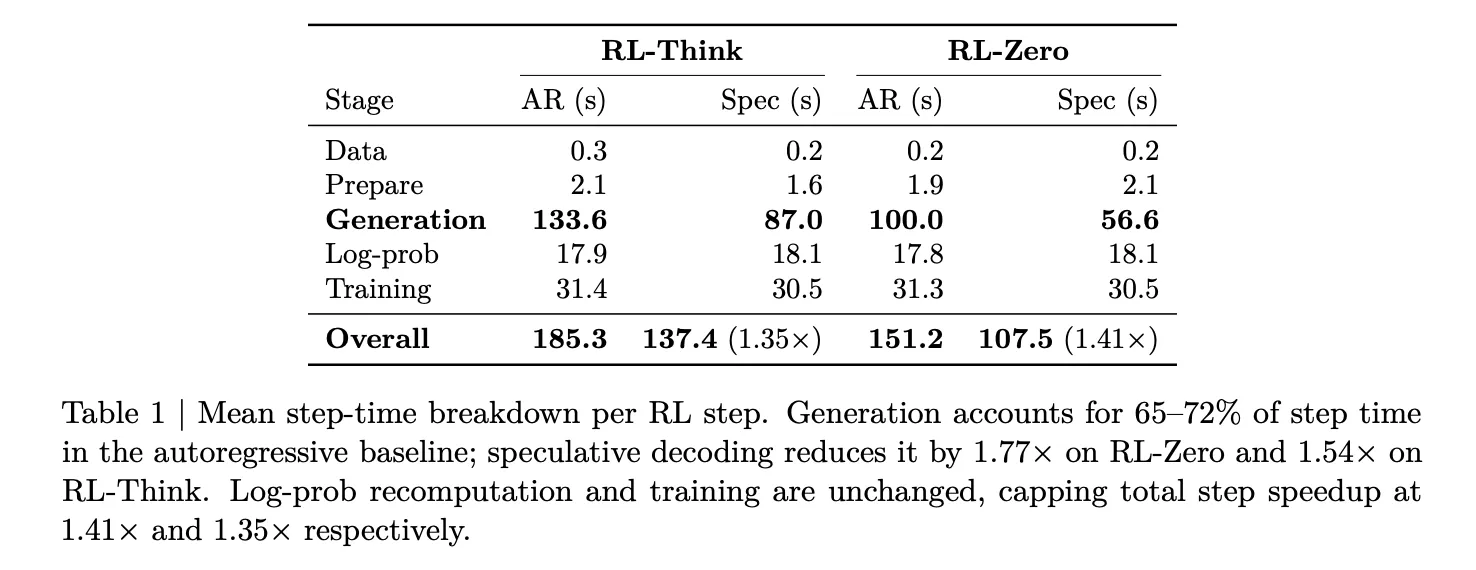
The researchers profiled this breakdown using Qwen3-8B across two different workloads: RL-Think, which takes an already reasoning-capable model and continues training it, and RL-Zero, which starts from a base model and must learn reasoning abilities from the ground up. In both setups, rollout generation consumed 65–72% of the total step time. The combined log-probability recomputation and training stages only accounted for about 27–33%. This makes it clear that generation is the only stage worth targeting for speedups, and it ultimately sets the upper limit for any rollout-side improvement.
How Speculative Decoding Works
Speculative decoding relies on a compact, swift draft model to predict multiple tokens simultaneously, while the larger target model (the one undergoing training) checks those predictions through a rejection sampling mechanism. The crucial aspect — and the reason it is valuable for RL — is that this rejection process is mathematically proven to yield the exact same output distribution as if the target model had produced those tokens one by one. There is no distribution shift, no need for off-policy adjustments, and no alteration to the training signal.
This matters significantly in RL post-training because the reward signal is derived from the policy’s own generated samples. Approaches like asynchronous execution, off-policy replay, or low-precision rollouts all sacrifice some degree of training accuracy in exchange for higher throughput. Speculative decoding sacrifices nothing: the rollouts follow the identical distribution the target model would have produced independently, just generated more quickly.
The Difficulty of System Integration
Integrating a draft model into a serving backend is relatively simple. Embedding one into an RL training loop, however, is far more complex. Each time the policy is updated, the rollout engine must be supplied with fresh weights. The draft model needs to stay in sync with the changing policy. Log-probabilities, KL penalties, and the GRPO policy loss must all be calculated relative to the target (verifier) policy — not the draft — or the optimization objective is quietly undermined.
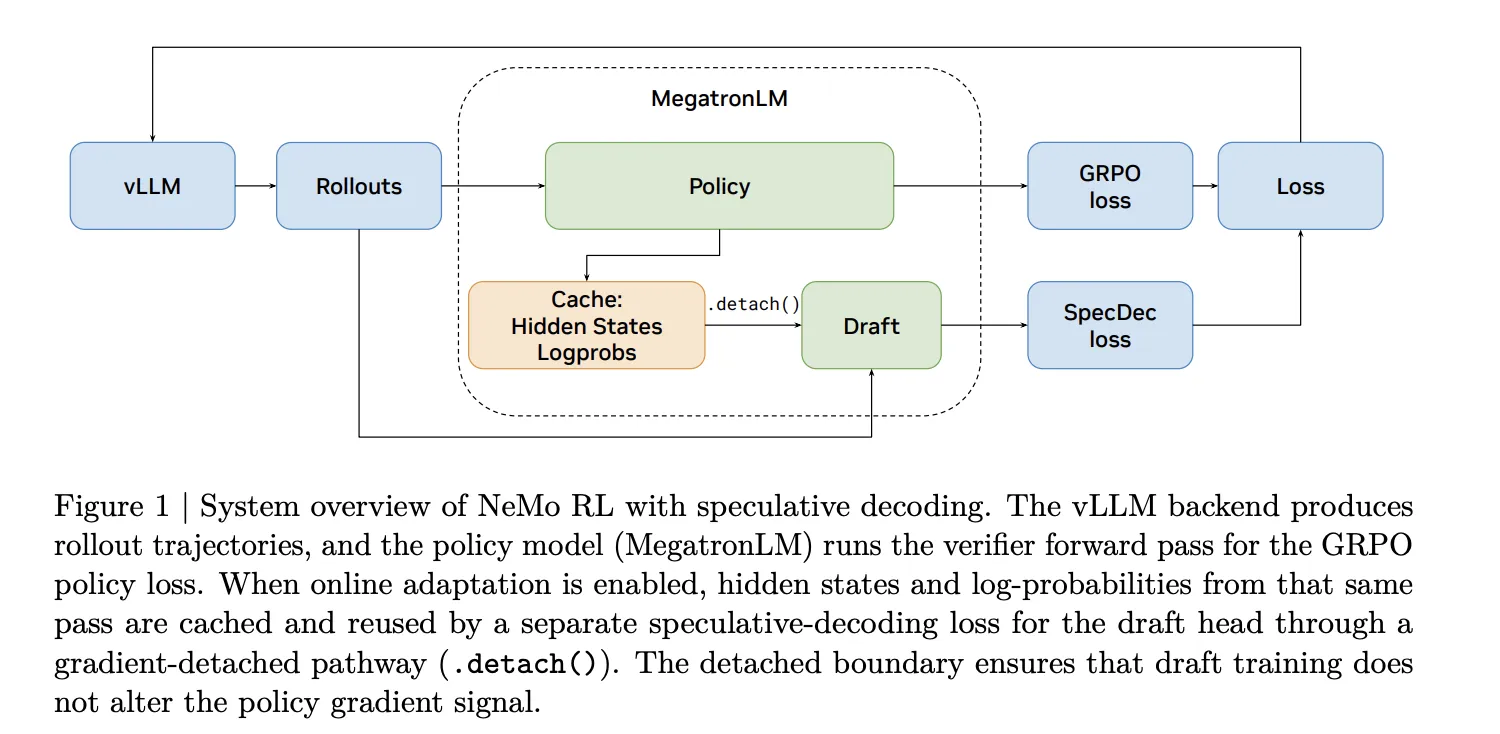
The NVIDIA research team addresses this in NeMo RL through a dual-path architecture. The standard path leverages EAGLE-3, a drafting framework compatible with any pretrained model without needing built-in multi-token prediction (MTP) support. A native path is offered for models that include integrated MTP heads. When online draft adaptation is activated, the hidden states and log-probabilities from the MegatronLM verifier forward pass are cached and repurposed to train the draft head via a gradient-detached pathway, ensuring draft training never disturbs the policy gradient signal.
Measured Results at 8B Scale
Across 32 GB200 GPUs (8 GB200 NVL72 nodes, 4 GPUs per node), EAGLE-3 cuts generation latency from 100 seconds down to 56.6 seconds on RL-Zero — a 1.8× improvement in generation speed. On RL-Think, it falls from 133.6 seconds to 87.0 seconds, a 1.54× speedup. Since log-probability re-computation and training remain unaffected, these generation-side improvements carry over to total step speedups of 1.41× on RL-Zero and 1.35× on RL-Think. Validation accuracy on AIME-2024 progresses identically under both autoregressive and speculative decoding throughout training, confirming that the lossless guarantee holds in real-world conditions.
The team also evaluates n-gram drafting as a model-free speculative baseline. Despite reaching acceptance lengths of 2.47 on RL-Zero and 2.05 on RL-Think, n-gram drafting underperforms the autoregressive baseline in both cases — 0.7× and 0.5× respectively. This is a vital takeaway for practitioners: a positive acceptance length is necessary but not enough on its own. If verification overhead is sufficiently high, speculation actually degrades performance.
Three Configuration Choices That Determine Actual Speedup
The research team identifies three operational decisions that practitioners must handle correctly.
Draft initialization is more impactful than general drafting capability. An EAGLE-3 draft initialized on the DAPO post-training dataset delivers a 1.77× generation speedup on RL-Zero, whereas a draft initialized on the general-purpose UltraChat and Magpie datasets manages only 1.51× at the same draft length. The draft needs to match the actual rollout distribution seen during RL, not just a broad conversational distribution.
Draft length has a non-obvious sweet spot. At draft length k=3, RL-Zero achieves 1.77× speedup and RL-Think reaches 1.53×. Pushing to k=5 increases the acceptance length but reduces speedup to 1.44× on RL-Zero and 0.84× on RL-Think — the latter already slower than autoregressive. At k=7, RL-Zero drops further to 1.21× and RL-Think to 0.71×. The difference is significant: RL-Zero’s rollouts originate from a base model producing brief outputs, making them easier for the draft to predict even at higher k. RL-Think’s fully formed reasoning chains are harder to speculate over, so the overhead of longer drafts eliminates the advantage sooner. More speculative work per step can completely negate the benefit of higher acceptance, particularly in more demanding generation scenarios.
Online draft adaptation — refreshing the draft during RL using rollouts from the current policy — provides the most benefit when the draft starts from a weak initialization. For a DAPO-initialized draft, offline and online setups perform almost identically (1.77× vs. 1.78× on RL-Zero). For a UltraChat-initialized draft, online updating boosts speedup from 1.51× to 1.63× on RL-Zero.
Interaction with asynchronous execution was also evaluated directly at 8B scale, not merely through simulation. The team ran RL-Think at policy lag 1 in a 16-node non-colocated setup, with 12 nodes assigned to generation and 4
In asynchronous mode, most of the rollout generation time is already overlapped with log-probability re-computation and policy updates, so the key metric is the exposed generation time that still sits on the critical path. Speculative decoding cuts that exposed generation time from 10.4 seconds down to 0.6 seconds per step and reduces effective step time from 75.0 seconds to 60.5 seconds (1.24×). The improvement is smaller than what is seen in synchronous RL — which is expected, since asynchronous overlap already masks a large portion of the rollout cost — but it demonstrates that the two techniques are truly complementary rather than overlapping in function.
Projected Gains at 235B Scale
Using a proprietary GPU performance simulator tuned to device-level compute, memory, and interconnect characteristics, the research team estimated speculative decoding gains at larger scales. For Qwen3-235B-A22B running synchronous RL on 512 GB200 GPUs, a draft length of k=3 with an acceptance length of 3 tokens produces a 2.72× rollout speedup and a 1.70× end-to-end speedup.
At the most favorable simulated configuration — Qwen3-235B-A22B on 2048 GB200 GPUs with asynchronous RL at policy lag 2 — rollout speedup reaches roughly 3.5×, translating to a projected 2.5× end-to-end training speedup. Speculative decoding and asynchronous execution are described as complementary: speculation lowers the cost of each individual rollout, while asynchronous overlap conceals the remaining generation time behind training and log-probability computation.
Key Takeaways
- Rollout generation is the primary bottleneck in RL post-training, making up 65–72% of total step time in synchronous RL workloads — meaning it is the only stage where acceleration meaningfully impacts end-to-end training speed.
- Speculative decoding via EAGLE-3 provides lossless rollout acceleration, delivering 1.8× generation speedup at 8B scale (1.41× overall step speedup) without altering the target model’s output distribution — unlike asynchronous execution, off-policy replay, or low-precision rollouts, which all sacrifice training fidelity for throughput.
- Draft initialization quality outweighs draft length, with in-domain (DAPO-trained) drafts outperforming general chat-domain drafts by a notable margin; longer draft lengths (k≥5) consistently underperform on harder reasoning tasks, making k=3 the dependable default.
- Simulator projections indicate gains scale up substantially, reaching ~3.5× rollout speedup and a projected ~2.5× end-to-end training speedup at 235B scale on 2048 GB200 GPUs — and the technique is already available in NeMo RL v0.6.0 under Apache 2.0.
Check out the Full Paper and Nemo RL Repo. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and subscribe to our Newsletter. Wait! Are you on Telegram? Now you can join us on Telegram as well.
Need to partner with us for promoting your GitHub repo, Hugging Face page, product release, webinar, or similar? Connect with us