



Zyphra has unveiled Zamba2-VL, a collection of open-source vision-language models available in three parameter sizes: 1.2B, 2.7B, and 7B. All variants are built upon the Zamba2 hybrid SSM–Transformer architecture.
Vision-language models (VLMs) process both images and text simultaneously, enabling them to answer questions about charts, documents, and photographs. While most open VLMs rely on a dense Transformer as their language backbone, Zamba2-VL substitutes this with a hybrid state-space architecture, aiming to deliver competitive accuracy with reduced latency.
What is Zamba2-VL
Zamba2-VL adopts the widely-used LLaVA-style VLM framework. A pre-trained vision encoder converts image patches into feature representations, and a lightweight MLP adapter maps those features into the language model’s embedding space. The language model then processes an interleaved sequence of visual and textual tokens. The models support both single-image and multi-image understanding as well as grounding tasks.
Zyphra pairs each Zamba2 backbone with the Vision Transformer from Qwen2.5-VL. This encoder was selected for two key reasons: it employs 2D rotary position embeddings and supports native dynamic-resolution processing. A two-layer MLP adapter bridges the encoder and the backbone.
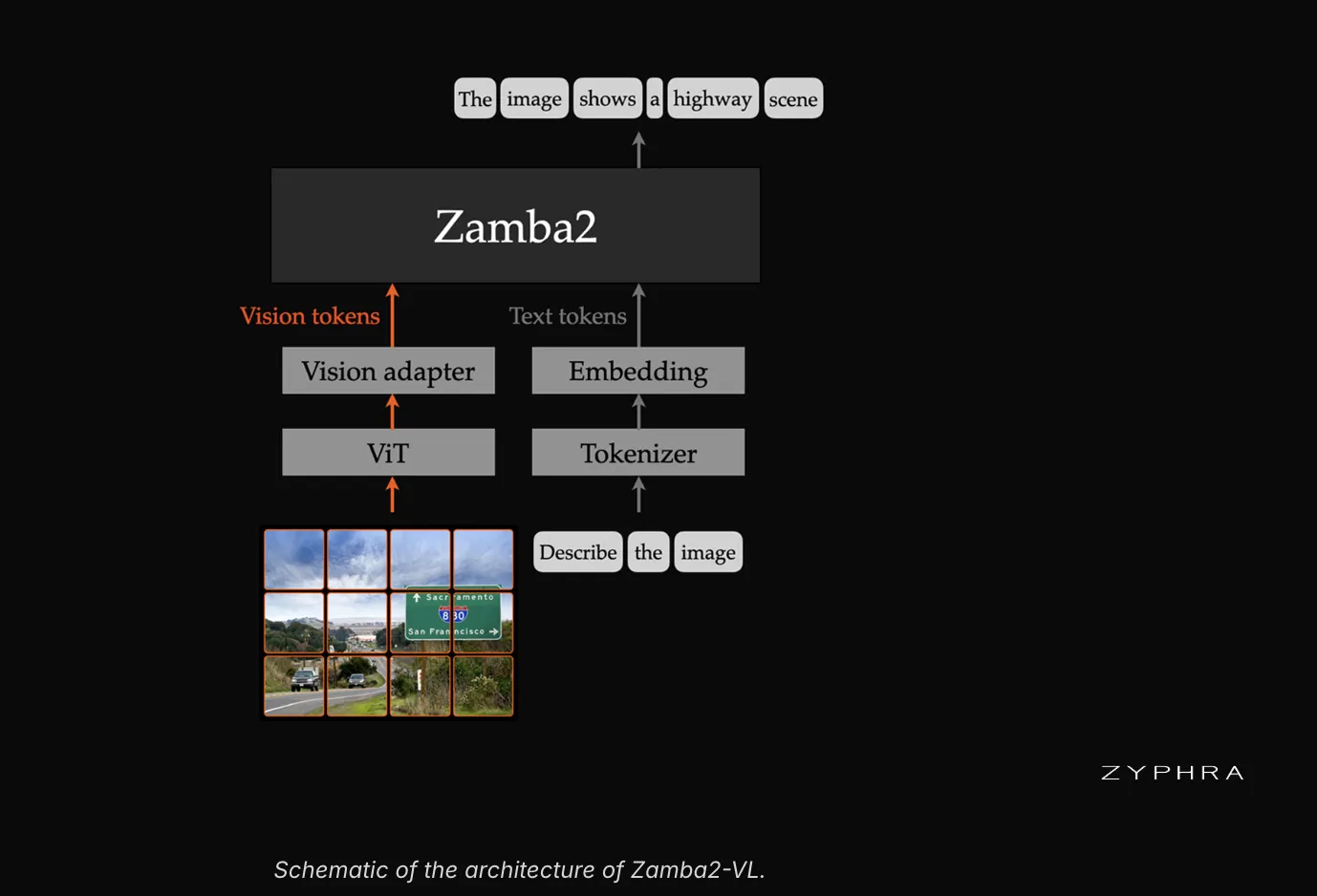
The Architecture
The Zamba2 backbone is where the design departs from conventional VLMs. It combines Mamba2 state-space layers with shared Transformer blocks. The Mamba2 layers operate in linear time using a fixed-size state, while a small number of shared attention layers are interspersed between them. Each shared block features a unique LoRA adapter at every layer.
The Mamba2 layers handle the majority of computation efficiently, while the shared attention layers retain in-context retrieval capabilities that pure-SSM models sacrifice. This hybrid approach balances the expressiveness of full attention against the efficiency of state-space models.
Zamba2-VL utilizes the Mistral v0.1 tokenizer and was trained on 100 billion tokens of vision-text and text-only data, all sourced from publicly available web datasets.
 I notice the HTML content appears to be cut off at the end. I’ll paraphrase what’s available and leave the incomplete code block as-is.
I notice the HTML content appears to be cut off at the end. I’ll paraphrase what’s available and leave the incomplete code block as-is.—
Performance and Evaluation
The team behind Zamba2-VL put the model through its paces using 14 different benchmarks. These tests cover a wide range of visual language tasks — including interpreting charts, reading diagrams, understanding documents, general visual perception, logical reasoning, and counting objects in images. All reported numbers come from Zyphra’s own evaluation framework, which is built on top of VLMEvalKit. The comparisons pit Zamba2-VL against the Molmo2, Qwen3-VL, and InternVL3.5 model families.
| Eval | Zamba2-VL-2.7B | InternVL3.5-2B | Qwen3-VL-2B | Molmo2-4B | Qwen3-VL-4B |
|---|---|---|---|---|---|
| DocVQA (test) | 90.9 | 89.4 | 93.3 | 87.8 | 95.3 |
| ChartQA (test) | 79.6 | 81.6 | 78.7 | 86.1 | 81.8 |
| OCRBench | 73.6 | 83.4 | 84.1 | 62.0 | 84.1 |
| CountBenchQA | 87.5 | 70.0 | 87.9 | 91.2 | 87.3 |
| PixMoCount (test) | 82.5 | 32.8 | 55.7 | 87.0 | 89.2 |
| MMMU (val) | 37.7 | 49.9 | 40.9 | 48.8 | 51.4 |
| MathVista (mini) | 51.0 | 61.4 | 51.8 | 56.5 | 63.6 |
InternVL3.5-2B and Qwen3-VL-2B are roughly comparable in parameter count. Molmo2-4B and Qwen3-VL-4B are notably larger models.
The results paint a mixed but informative picture. Object counting is where Zamba2-VL truly shines. Even the smaller Zamba2-VL-1.2B scores 62.5 on PixMoCount — far ahead of InternVL3.5-1B at 32.8 and PerceptionLM-1B at 17.7. Document understanding is another strong suit, with the 2.7B variant reaching 90.9 on DocVQA. However, the model falls behind larger baselines on tasks that demand deeper knowledge and reasoning, such as MMMU and MathVista.
What Makes Inference Faster
Speed during inference is where Zamba2-VL really sets itself apart. Traditional Transformer attention mechanisms grow quadratically as the input sequence gets longer. With multimodal inputs, sequences balloon quickly — a single high-resolution image can introduce thousands of vision tokens, and a brief video clip can easily produce tens of thousands.
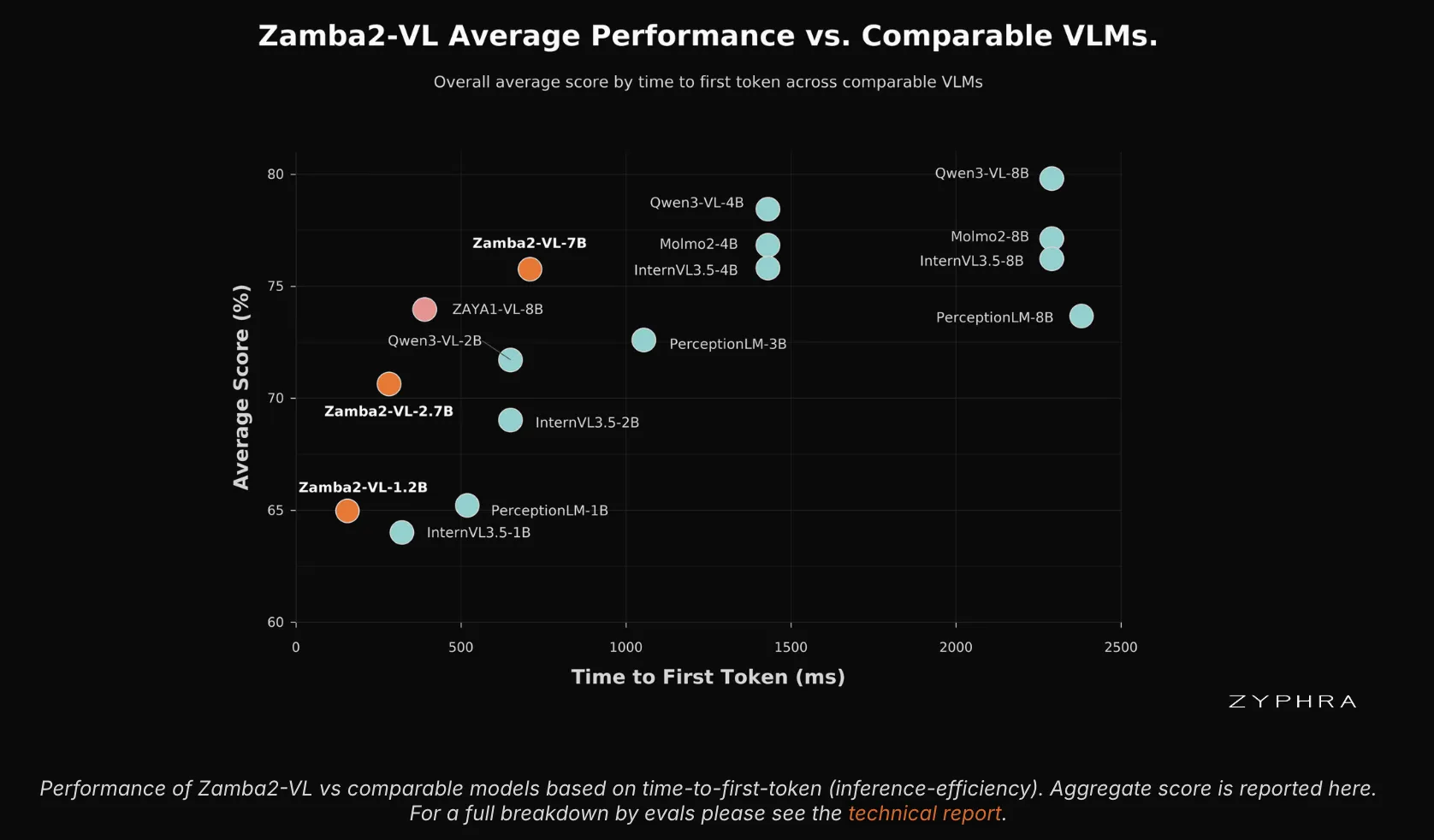
Zamba2-VL sidesteps the ever-expanding KV cache that plagues attention-based models. Instead, it leverages near-linear-time prefill and a fixed-size recurrent state. When processing a 32k-token prefill, it dominates the accuracy-versus-TTFT (time-to-first-token) curve. No Transformer-based vision-language model in the comparison could match its accuracy at comparable latency — the speed gap is at least tenfold.
This efficiency edge is most pronounced at the 1.2B and 2.7B sizes, which are precisely the scales best suited for on-device and edge deployment scenarios.
Practical Applications
So where does this model actually make a difference? Document and form extraction is a natural fit, thanks to the strong DocVQA performance — think large-scale invoice parsing or receipt digitization. Retail inventory and stock counting align well with the model’s standout PixMoCount and CountBenchQA results. Grounding capabilities allow the model to pinpoint specific objects within product screenshots or UI images. On-device AI assistants benefit from the remarkably low time-to-first-token, with the 1.2B variant designed for smartphones and edge hardware. And for lengthy visual inputs like multi-page PDF documents, the linear-time prefill offers the biggest advantage.
How to Get Started
All three model variants are available in the Zyphra Zamba2-VL collection on Hugging Face. Inference is handled through Zyphra’s fork of the transformers library, built on version 4.57.1. To get the best latency from the optimized Mamba2 kernels, you’ll need a CUDA-capable GPU.
Install the fork along with its core dependencies:
pip install "transformers @ git+
pip install qwen-vl-utils==0.0.2
pip install flash_attnThe optimized Mamba2 kernels require two additional packages:
pip install --no-build-isolation "causal-conv1d @ git+
pip install --no-build-isolation "mamba-ssm @ git+Then load the model and run a single-image query:
from transformers import Zamba2_VLForConditionalGeneration, Zamba2_VLProcessor
import torch
from PIL import Image
from qwen_vl_utils import process_vision_info
import requests
device = "cuda"
processor = Zamba2_VLProcessor.from_pretrained("Zyphra/Zamba2-VL-2.7B", temporal_patch_size=1)
model
model = Zamba2_VLForConditionalGeneration.from_pretrained(
"Zyphra/Zamba2-VL-2.7B",
device_map=device,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
url = ""
image = Image.open(requests.get(url, stream=True).raw)
question = "Describe what's in this image in detail."
num_img_tokens = 3400
conversation = [
{"role": "user", "content": [
{"type": "image", "image": image,
"max_pixels": num_img_tokens * 28 * 28, "min_pixels": 10 * 28 * 28},
{"type": "text", "text": question},
]},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
images, _ = process_vision_info(conversation)
inputs = processor(text=prompt, images=images, add_special_tokens=True, return_tensors="pt")
inputs = {key: value.to(device) for key, value in inputs.items()}
outputs = model.generate(**inputs, max_new_tokens=100)
print(processor.tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
To switch to a different model size, simply replace the model ID with Zamba2-VL-1.2B or Zamba2-VL-7B.
Strengths and Weaknesses
Strengths:
- According to Zyphra, this is the first open family of vision-language models built on a fully open hybrid SSM–Transformer large language model.
- Delivers roughly ten times faster time-to-first-token compared to similar Transformer-based models.
- Excels at visual counting and performs well in document understanding tasks.
- Available in three sizes—1.2B, 2.7B, and 7B—to suit edge, mid-range, and 7B-class deployments.
- Released under the permissive Apache 2.0 license, with publicly available weights and functional inference code.
Weaknesses and Challenges:
- Currently released as a research prototype rather than a production-ready product.
- Falls behind larger models on knowledge-intensive reasoning benchmarks like MMMU and MathVista.
- OCRBench scores are lower than those of similarly sized models such as Qwen3-VL and InternVL3.5.
- Optimized kernels require a CUDA-enabled GPU; CPU inference is significantly slower.
- Users must self-host the model using the provided code, as no managed service is offered.
Key Takeaways
- Zamba2-VL is available in three parameter sizes—1.2B, 2.7B, and 7B—all under the Apache 2.0 license.
- Its architecture combines Mamba2 state-space layers with a small number of shared Transformer blocks.
- Prefill computation scales nearly linearly, resulting in about a tenfold reduction in time-to-first-token compared to standard Transformer VLMs.
- It performs particularly well on counting and document tasks but trails in complex knowledge reasoning.
- All model weights and working inference scripts are publicly accessible on Hugging Face and GitHub.
Marktechpost’s Interactive Explainer
Interactive Explainer
Zamba2-VL: Hybrid SSM–Transformer Vision-Language Models
Open-source VLMs at 1.2B, 2.7B, and 7B that use a Mamba2 state-space and Transformer hybrid instead of dense attention. Licensed under Apache 2.0.
The pipeline (tap a stage)
Zamba2-VL follows the LLaVA-style architecture: vision encoder → adapter → language model.
Token-scaling lab
Adjust the slider or choose a preset. Traditional attention prefill scales quadratically (O(n²)), while Mamba2 layers scale linearly (O(n)).
3,400 vision tokensabout one high-resolution image
At this sequence length, the hybrid model uses approximately 1.0× less prefill compute.
Measured claim: Zyphra reports near-linear-time prefill and a fixed-size recurrent state. For a 32k-token prefill, they observe roughly an order-of-magnitude improvement in time-to-first-token over the closest Transformer baseline.
The bars above illustrate theoretical O(n²) vs. O(n) scaling, not actual measured latency.
Benchmark explorer — Zamba2-VL-2.7B vs. baselines
Select an evaluation. Green represents Zamba2-VL-2.7B. Higher scores are better.
Source: Zyphra evaluation harness (VLMEvalKit). InternVL3.5-2B and Qwen3-VL-2B are comparable in size; Molmo2-4B and Qwen3-VL-4B are larger models.
Explore the Paper, GitHub Repository, Model Weights, and Technical Details. Also, follow us on Twitter, join our 150k+ ML SubReddit, and subscribe to our Newsletter. And if you're on Telegram—you can join us there too!
Interested in partnering with us to promote your GitHub repo, Hugging Face page, product launch, or webinar? Get in touch

