



After pretraining, large language models stop updating. Their stored knowledge stays frozen while the real world keeps changing. Completely retraining a modern LLM costs far too much. Fine-tuning introduces new information but often erases what the model already knew. Retrieval-augmented generation (RAG) falls short when a question demands connecting insights scattered across many different documents.
Researchers from the National University of Singapore, MIT CSAIL, A*STAR, and the Singapore-MIT Alliance for Research and Technology (SMART) have come up with a fresh solution called MEMO (Memory as a Model).
What Problem Does MEMO Solve?
Current strategies for adding fresh knowledge to LLMs fall into three groups. Non-parametric approaches such as RAG pull in relevant documents at query time. These methods are easily thrown off by noisy search results and have trouble reasoning across multiple documents. Parametric approaches like continual pretraining or supervised fine-tuning bake knowledge directly into the model’s weights. They demand heavy compute and trigger catastrophic forgetting — the tendency for new learning to overwrite or degrade earlier knowledge. Latent memory approaches squeeze knowledge into compact soft-token vectors. But these representations are tightly entangled with the specific model that created them, a bottleneck the researchers label representation coupling, making it hard to transfer memory across different LLMs.
MEMORY as a Separate Model
MEMO draws a clear line between memory and reasoning. The MEMORY model is a small, purpose-built language model trained to absorb knowledge from a chosen body of text. The EXECUTIVE model is the main LLM — kept frozen and accessed only through its standard input and output channels.
In the experiments, the MEMORY model used is Qwen2.5-14B-Instruct, while the EXECUTIVE model is either Qwen2.5-32B-Instruct or Gemini-3-Flash, a closed-source proprietary system. Because MEMO treats the EXECUTIVE model as a black box, it needs neither weight access nor output logits to work.
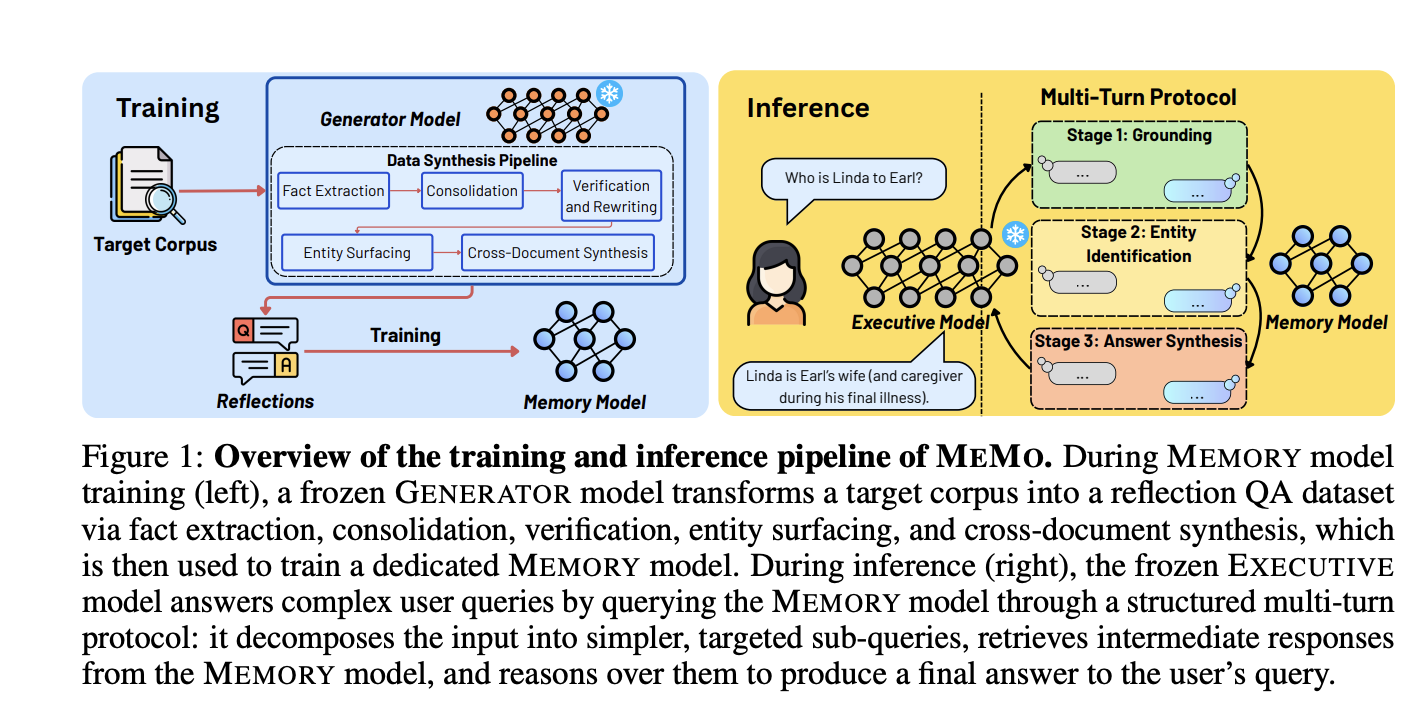
How the MEMORY Model is Trained
The training process kicks off with a five-step data synthesis pipeline steered by a GENERATOR model — in experiments, this is Qwen2.5-32B-Instruct. The pipeline transforms raw source documents into a reflection QA dataset: collections of question-and-answer pairs that capture the corpus knowledge expressed through a wide variety of query styles.
The five steps break down as follows:
- Fact extraction — explicitly stated facts are pulled straight from the text, while implied information is inferred. Both processes run in parallel across each document chunk.
- Consolidation — QA pairs that touch on the same underlying context — such as a shared entity, time frame, or relationship — are merged into richer, multi-fact pairs.
- Verification and rewriting — each QA pair is examined to make sure it stands on its own. Pairs containing vague pronouns or missing references are either rewritten with help from the original source chunk or thrown out entirely.
- Entity surfacing — QA pairs are crafted so that the question encodes attributes and relationships of an entity, while the answer reveals that entity’s identity. This step directly tackles the reversal curse, the well-known weakness where a model trained on “A is B” struggles to infer the reverse “B is A.”
- Cross-document synthesis — the GENERATOR model builds QA pairs that draw from multiple documents at once. It picks up on two kinds of cross-document links: converging clues (where several documents describe the same entity) and parallel properties (where different entities share a common attribute or role).
Step 5 is the linchpin of the whole pipeline. A leave-one-out ablation study shows that stripping away this single step causes accuracy on NarrativeQA to collapse from 24.00% to just 6.37%. It also represents the largest share of the
The final dataset’s training pairs originate from a diverse collection of sources.
The MEMORY model learns through supervised fine-tuning (SFT), where loss is calculated exclusively from answer tokens. During inference, the model relies entirely on its internalized knowledge — source documents are never made available at that stage.
Inference: The Structured Multi-Turn Protocol
During inference, the EXECUTIVE model communicates with the MEMORY model via a structured three-stage multi-turn protocol.
Stage 1: Grounding. The EXECUTIVE model breaks the original query into smaller sub-questions, each designed to isolate a distinct identifying constraint. The MEMORY model addresses each one independently.
Stage 2: Entity identification. Building on the grounded answers, the EXECUTIVE model sends follow-up sub-queries aimed at progressively narrowing the pool of candidate entities until a single match is confirmed or the allowed budget for the stage is exhausted.
Stage 3: Answer seeking and synthesis. Once the entity is identified, the EXECUTIVE model prompts the MEMORY model for supporting facts. The executive then consolidates all retrieved responses into a coherent final answer.
The MEMORY model returns concise natural-language snippets whose length remains constant regardless of corpus size. This means retrieval cost stays flat even as the document collection grows — a key advantage over RAG, where inference cost increases proportionally with the corpus.
Experimental Results
MEMO is tested on three benchmarks: BrowseComp-Plus (multi-hop deep-research), NarrativeQA (discourse comprehension over books and movie scripts), and MuSiQue (2–4 hop reasoning over Wikipedia paragraphs). Baseline methods include BM25, NV-Embed-V2, HippoRAG2, and Cartridges. Cartridges requires white-box access to the EXECUTIVE model and achieved 0.00% on BrowseComp-Plus and 3.75% on NarrativeQA.
On NarrativeQA using Gemini-3-Flash, MEMO reaches 53.58%, while HippoRAG2 attains 23.21% under the same conditions. On MuSiQue, MEMO scores 60.20% compared to HippoRAG2’s 57.00%. On BrowseComp-Plus, MEMO achieves 66.67% versus HippoRAG2’s 66.33%.
With Qwen2.5-32B-Instruct serving as the EXECUTIVE model, MEMO records 54.22% on BrowseComp-Plus and 48.30% on MuSiQue. Upgrading to Gemini-3-Flash delivers improvements of 12.45%, 26.73%, and 11.90% across the three benchmarks. Notably, the MEMORY model does not need retraining when the EXECUTIVE model is swapped.
Robustness to retrieval noise: The team measures performance after injecting distractor documents into the corpus. NV-Embed-V2 and HippoRAG2 decline by as much as 6.22% on BrowseComp-Plus when one negative document is added per evidence document. MEMO’s accuracy on the same benchmark shifts by only +0.55% — well within one standard deviation.
MEMORY model architecture robustness: Three MEMORY model families of comparable parameter scale are evaluated: Qwen2.5-1.5B-Instruct, Gemma3-1B-IT, and LFM2.5-1.2B-Instruct (a hybrid state-space and transformer architecture). Results remain broadly consistent across all three, suggesting the framework is not dependent on the specific pretraining lineage of the MEMORY model.
Continual Knowledge Integration via Model Merging
MEMO enables incremental knowledge updates through model merging. When a new corpus becomes available, a separate MEMORY model is independently trained on it. Its task vector — defined as the parameter difference relative to the base model — is then merged with the existing MEMORY model directly in parameter space.
The team validates this approach on NarrativeQA using TIES merging (ρ=0.3). For K=2 corpora, merging accumulates 48 GPU-hours compared to 72 GPU-hours for full retraining — a 33% reduction. At K=10, merging scales as Θ(K) while full retraining scales as Θ(K²), producing a 5.5× saving (240 vs. 1,320 GPU-hours).
The merged MEMORY model falls behind full retraining by 11.04% under Qwen2.5-32B-Instruct (15.81% vs. 26.85%) and by 19.11% under Gemini-3-Flash (34.47% vs. 53.58%). Despite this performance gap, it still surpasses all retrieval-based baselines on NarrativeQA.
Marktechpost’s Visual Explainer
Key Takeaways
- MEMO trains a dedicated MEMORY model on new knowledge while keeping the main LLM completely untouched.
- A five-stage data synthesis pipeline converts raw documents into a reflection-style QA dataset that captures cross-document relationships.
- During inference, a structured multi-turn protocol breaks complex queries into targeted sub-queries directed at the MEMORY model.
- Retrieval cost stays fixed at inference time — it does not grow with corpus size, unlike RAG.
- Model merging reduces cumulative training compute by 33% at K=2 corpora and 5.5× at K=10, with a measurable trade-off in accuracy.
Check out the Research Paper. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and subscribe to our Newsletter. Wait! Are you on Telegram? Now you can join us on Telegram as well.
Interested in partnering with us to promote your GitHub repo, Hugging Face page, product release, or webinar? Connect with us