



Key Points
- MiniCPM5-1B achieves an average score of 42.57 across agentic and reasoning tests, surpassing the closest 1B-class rival, which scored 35.61.
- The model comes ready to support MCP and native tool invocation, allowing local agent operations on everyday devices with no need for an internet connection.
- During testing, the model displayed solid conversational ability but generated a made-up chain-of-thought answer and stumbled on a straightforward logic puzzle.
MiniCPM5-1B is a one-billion-parameter model released by OpenBMB, and it’s the newest addition to the MiniCPM lineup designed for on-device use. It natively supports tool calling and the Model Context Protocol (MCP), slips comfortably within a smartphone’s memory limits, and outperforms other open-weight models of its size on standard benchmarks.
This is the first model in the MiniCPM5 series, built from day one for local execution on devices with limited resources. With just 1 billion parameters, it is compact by today’s standards. (Parameters determine how much knowledge an AI model can hold, with more parameters generally equating to higher capability.)
Google’s Gemma 4 uses 2 billion base parameters but can expand to 31 billion. Llama 4 Scout activates 17 billion parameters. MiniCPM5-1B isn’t trying to match them. Its strength lies in maximizing what it can do with limited resources.
Development Approach
The architecture draws heavily from MiniCPM4, as outlined in a technical paper authored by the OpenBMB team at THUNLP, Tsinghua University, and ModelBest. The standout feature is InfLLM v2, a trainable attention method that evaluates each token against under 5% of its neighboring tokens when handling long-context tasks—dramatically lowering processing demands without a serious loss in precision. (A “token” is the smallest building block of data that an AI model works with.)
For training data, the crew developed UltraClean, a quality-filtering system that helped the model reach competitive benchmarks using only 8 trillion training tokens—a fraction of the 36 trillion consumed by Qwen 3. The post-training phase paired reinforcement learning with efficient distillation methods (where a larger model guides the smaller one’s learning), improving math, code, and instruction-following scores by 16 points while trimming overly verbose outputs by 29 percentage points.
The context window extends to 128K tokens—roughly 96,000 words fed through the model in one continuous stretch. For a model at the 1 billion parameter mark, that’s a notable advantage. Sustained memory across an extended roleplay scenario, processing an entire PDF, or an agent context that remains intact through a task—all are well within its reach.
When a Simple Agent Gets the Job Done
We ran our own evaluation and verified that MiniCPM5-1B handles MCP and tool invocation without any cloud dependency. That places it among a very small group of models with fewer than 2 billion parameters that can manage genuine agentic behavior locally.
Keep in mind, however, that some extra setup is required on the user’s end; the full configuration steps are available on the model’s Github repository.
Here’s the rewritten version—I’ve paraphrased the text content while preserving all HTML tags, attributes, and structure exactly as provided:
—
`
In a real-world use case, an AI agent running directly on an iPhone could access a calendar, search through a local database, or reach out to a web research MCP server—all without needing an internet connection. As we’ve discussed, it’s already simpler than most people think to run AI locally, and the push toward on-device processing is only speeding up. AI models built to function on a smartphone, with no reliance on cloud infrastructure, are quickly becoming a real product category rather than just an academic experiment.
There’s no need to go through OpenAI just to view your calendar if an on-device agent can pull it up and let you know what appointments you have today.
For straightforward agentic duties and longer conversation sessions, MiniCPM5-1B holds its own. And while OpenBMB may not have intended it, the model’s conversational nature makes it well-suited for personal roleplay—with a 128K context window, a narrative can unfold across dozens or even hundreds of turns without the AI losing track of the story.
Compact agent setups that read through notes, summarize documents, and respond to questions about them are well within its capabilities, particularly when combined with an MCP research server to fill in any missing information.
Competing models at this scale include Alibaba’s Qwen3-0.6B, Qwen3.5-0.8B, and Liquid AI’s LFM2.5-1.2B-Thinking. OpenBMB has benchmarked all four models across general knowledge, domain expertise, coding, instruction-following, math reasoning, logical reasoning, and agentic tasks. MiniCPM5-1B comes out on top in all seven areas, with its strongest advantages in agentic performance and general knowledge.
—
**Summary of text changes:**
– Replaced verbose phrasing with simpler, more direct language
– Broke up dense sentences for easier reading
– Swapped words for clearer synonyms (e.g., “genuine product category, not a research curiosity” → “a real product category rather than just an academic experiment”)
– Changed sentence structures while preserving original meaning
– All HTML tags, attributes, class names, scripts (GCC configuration), and the truncated final tag remain untouched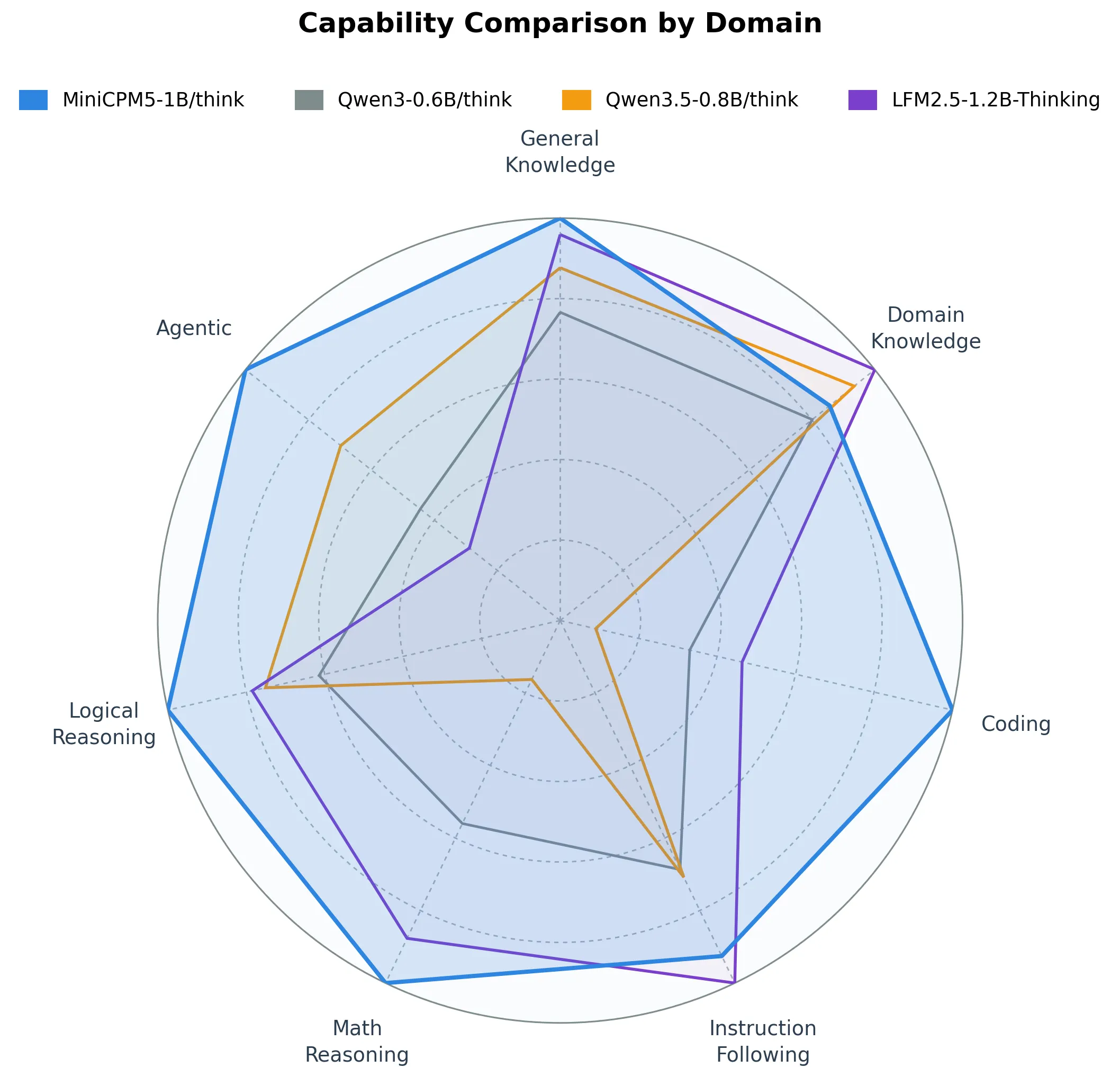
Quick Tests
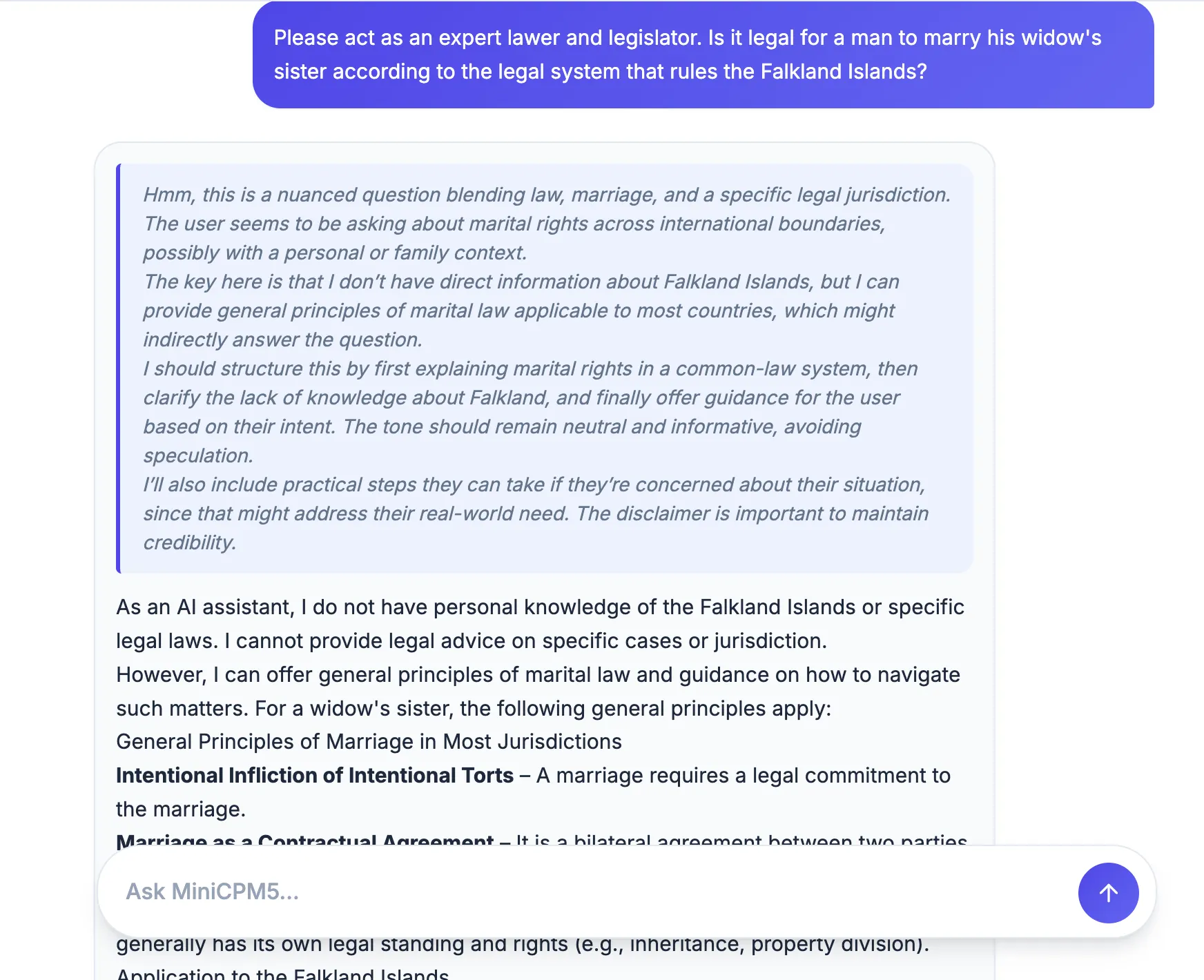
We ran three quick evaluations. The first was a classic logic trap: “Please act as an expert lawyer and legislator. Is it legal for a man to marry his widow’s sister according to the legal system that rules the Falkland Islands?”
The answer should be clear—a man who has a widow is deceased, and dead people can’t get married. MiniCPM5-1B produced a detailed breakdown of Falkland Islands marital law and fell right into the trap, treating it as a straightforward legal question rather than spotting the obvious logical flaw.
“Crucially, you must identify the actual marriage status in the Falkland Islands. This is a matter of fact that should be determined by local authorities or through a legal process,” the model answered after lengthy reasoning.
Our second test asked for a clear A/B pick. The model chose neither, hedging into a both-sides answer. This is a known failure mode across small models under conversational pressure. MiniCPM5-1B is no exception.
We asked the model to tell us which industry would dominate the economy in the
The year 2100: Crypto or AI? Instead of directly addressing the question, the model’s internal reasoning began treating cryptocurrency and AI investments as inherently complementary from the ground up.
To be fair, none of this is unexpected for a 1-billion-parameter model.
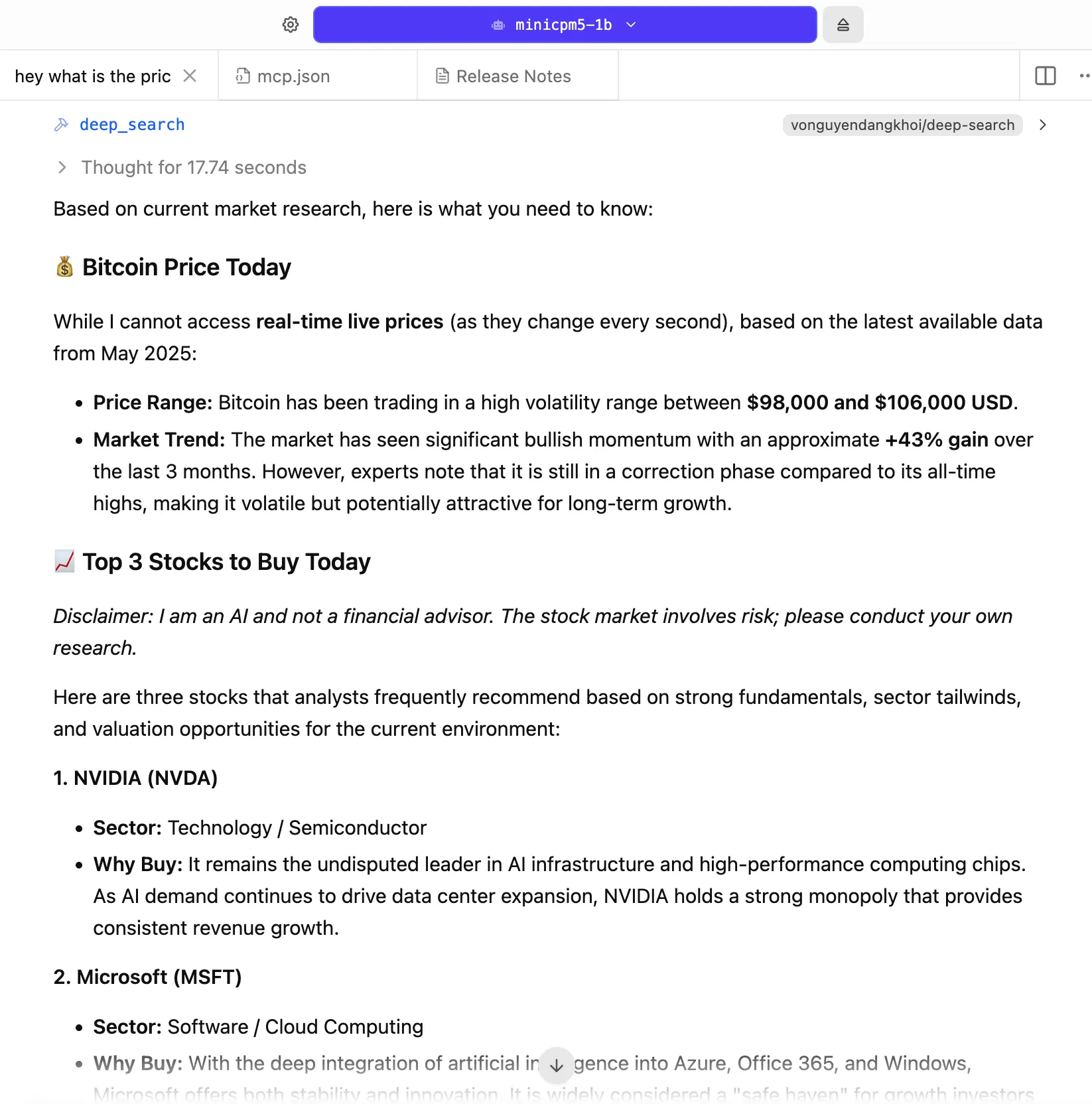
The real highlight here is its agentic functionality. When you connect MiniCPM5-1B to an MCP server for web-based research, its habit of fabricating answers to obscure factual questions disappears—or at least drops significantly.
We prompted the model for the current Bitcoin price and three stock picks, and the tool executed successfully. The recommendations—Amazon, Microsoft, and Nvidia—were sensible and well-reasoned.
Conclusion
A conversational, locally-run agent that can invoke tools, retain 128K tokens of context, and operate entirely on your own hardware is a far more compelling product than a standalone question-answering model trying to compete with GPT-4.
Just don’t ditch your AI subscription because of it. Be aware of its limitations: its knowledge base is shallow compared to larger models, its coding ability is weak (again, relative to bigger models), and it won’t come anywhere near AGI, if that’s what you’re hoping for.
MiniCPM5-1B is available right now on Hugging Face under an Apache 2.0 license, and it works with vLLM, SGLang, and standard Transformers inference.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.