



I’ve been incorporating AI coding agents into my everyday engineering routine and wanted to gauge how effectively they handle genuine, real-world bugs.
To find out, I designed a series of structured experiments using bug reports pulled from the Kubernetes repository. The goal was to see whether these agents could deliver accurate, thorough fixes with no human guidance inside a massive, multi-million-line codebase. My starting hypothesis was straightforward: success would come down to retrieval. Whether through retrieval-augmented generation (RAG) or filesystem search, a model that locates the relevant code should be able to craft the correct fix.
That hypothesis only partially held up. Even when agents identified the correct files, they frequently struggled to link changes across multiple files, misjudged the actual scope of the bug, or produced fixes that made sense in isolation but were wrong in the broader context. The real bottleneck wasn’t just locating code — it was reasoning about that code within the full picture.
The setup
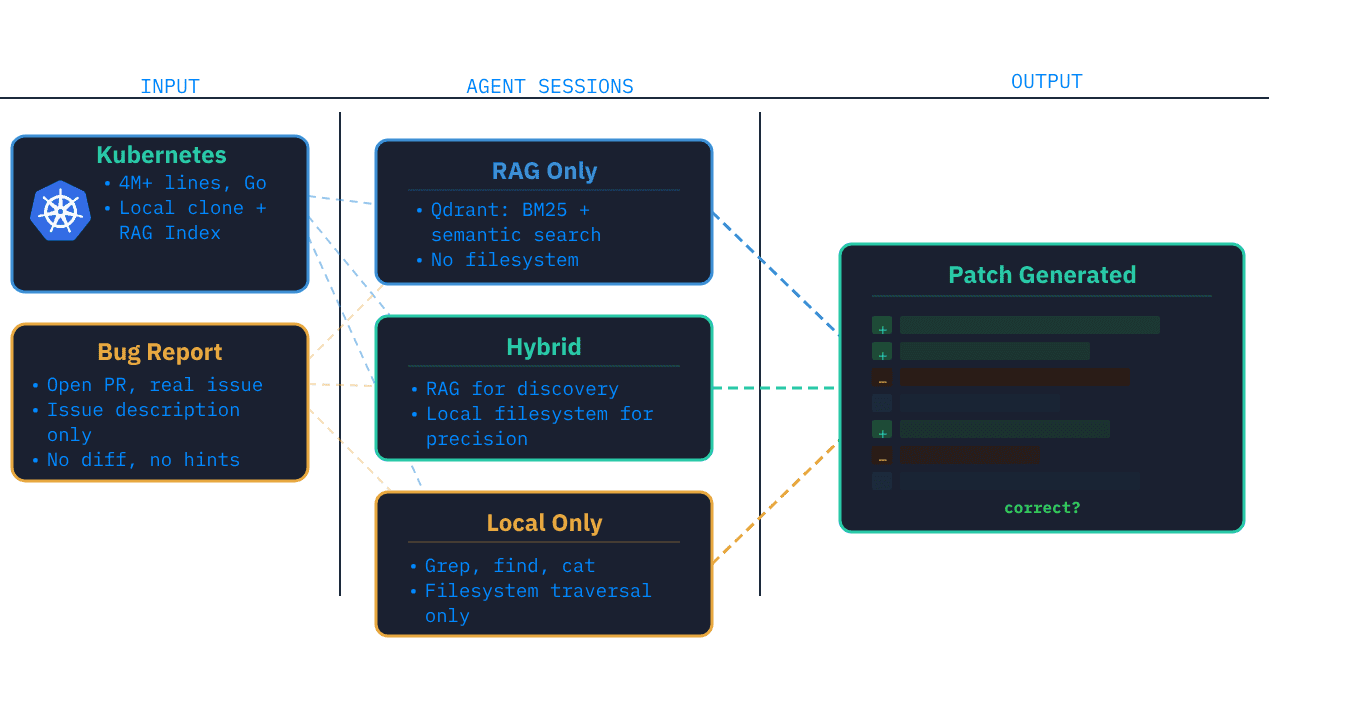
I pulled open pull requests from the Kubernetes GitHub repo — real bugs being actively addressed by real contributors. I extracted only the issue description (not the PR description, not the diff, nothing that would reveal the solution) and fed each issue to three distinct agent configurations:
- RAG Only: Hybrid retrieval over an indexed copy of the Kubernetes codebase via the KAITO RAG Engine (Qdrant), combining BM25 keyword matching with embedding-based semantic search. KAITO also offers an auto-indexing controller, which is ideal for indexing enormous git repos with support for incremental indexing. Results are merged and ranked before being returned as context snippets. No local files or web access — the agent only sees retrieved chunks.
- Hybrid (RAG + Local): Same RAG index, but also equipped with a full local clone of the Kubernetes repository. The agent must begin with RAG for discovery, then can read local files for precision.
- Local Only: Full clone, grep, find, cat. No RAG, no web. The agent navigates the codebase through direct filesystem traversal.
Each agent operated in a completely isolated session. Same model (Claude Opus 4.6), same timeout (5 minutes), same output format. The only variable was how they could access code.
One critical constraint: the RAG and Hybrid agents were instructed to run RAG queries before producing any fix. Early experiments revealed that without this requirement, hybrid agents would bypass RAG entirely when the issue referenced specific filenames, undermining the entire purpose of the comparison.
The test cases (Benchmark)
I assembled a benchmark from real, in-flight bug fixes in the Kubernetes repository. Each test case is an open pull request where the agent receives only the issue description and is asked to produce a patch. They span kubelet, scheduler, networking, storage, and apps — ranging from a one-line guard clause to a 900-line multi-file refactor.
| PR | Bug | SIG | Size | Files |
| #134540 | SubPath volume mount race condition (EEXIST) | sig/storage | XS | 3 |
| #138211 | Image pull record poisoning (preloaded images) | sig/node | M | 5 |
| #138244 | NUMA topology stall on GB200 systems (O(2^n)) | sig/node | L | 2 |
| #136013 | OOM score panic on zero memory capacity | sig/node | S | 2 |
| #138269 | Scheduler SchedulingGates missing Pod/Update event | sig/scheduling | S | 2 |
| #138158 | ServiceCIDR deletion race in allocator | sig/network | M | 3 |
| #135970 | Missing initializer in StatefulSet slice builder | sig/apps | M | 4 |
| #138000 | Windows kube-proxy stale remote endpoint cleanup | sig/network | XL | 5 |
| #138191 | Container status sort by attempt (clock rollback) | sig/node | M | 5 |
Each generated diff was compared against the corresponding pull request diff and graded across five dimensions (0–4 each):
- Files: Did the diff touch the correct files?
- Location: Was the fix applied in the correct function or layer?
- Mechanism: Did the fix preserve correct system-level invariants and layering, rather than just patching symptoms?
- Tests: Were existing tests updated or meaningful new tests added?
- Completeness: Did the patch propagate changes across all required call sites and dependent paths?
This evaluation uses the PR diff as the reference implementation. That’s not a perfect ground truth — PRs reflect iterative discussion and may not represent the only or final correct solution. Here, it serves as a proxy for “what human contributors converged on under review constraints.”
Timing
Every session had a 5-minute ceiling. Here’s how long each actually took:
| PR | RAG | Hybrid | Local |
| #134540 | 55s | 3m00s | 5m00s |
| #138211 | 2m30s | 3m30s | 2m30s |
| #138244 | 41s | 44s | 2m00s |
| #136013 | 31s | 55s | 41s |
| #138269 | 44s | 1m12s | 1m23s |
| #138158 | 1m41s | 1m48s | 52s |
| #135970 | 1m23s | 2m43s | 1m32s |
| #138000 | 1m28s | 4m03s | 4m57s |
| #138191 | 1m34s | 3m54s | 2m52s |
| Average | 1m16s | 2m25s | 2m24s |
RAG is consistently the fastest. It doesn’t read files, navigate directories, or wait for grep results. It queries the index, receives snippets, and generates. Average wall-clock: 1 minute 16 seconds. This suggests retrieval
While this approach cuts down on the effort of exploring the codebase, it also limits how deeply the agent can investigate the overall structure.
On average, the Hybrid method is the slowest, clocking in at 2 minutes and 25 seconds. It requires a mandatory RAG-first step, which adds delay before any local file exploration can start. For particularly complex pull requests like #138000 and #138191, Hybrid took over 3–4 minutes. The back-and-forth switching between tools ends up consuming more time than the actual reading of files.
Local exploration matches Hybrid’s average speed, but for entirely different reasons. Hybrid spends its time running RAG queries and then reading specific files. Local, on the other hand, burns through time with broad searches—grepping, locating files, and navigating directories. How much time this takes depends heavily on how clearly the issue description points the agent in the right direction.
Token economics
Token consumption isn’t just about how much code the agent reads—it’s primarily driven by how many times it calls the model.
Claude’s API is stateless, meaning every call re-sends the entire conversation history. This makes the number of calls the main factor multiplying your costs.
Here are a few key terms used below:
- Calls: The number of times the model is invoked during a session
- New Tokens: Tokens introduced for the first time (retrieved code, file contents, prompts)
- Output: Tokens produced by the model in response
- Cached (replay): Tokens re-sent on every call because the full conversation is replayed each time
- Total: The sum of all tokens processed throughout the session
Averages across all runs:
| Approach | Calls | New Tokens | Output | Cached (replay) | Total |
| RAG | 4 | 44k | 2k | 141k | 187k |
| Hybrid | 8 | 27k | 3k | 234k | 264k |
| Local | 6 | 23k | 4k | 162k | 189k |