



Determine 2 illustrates the workflow of our methodology. Initially, we randomly stratify all sufferers utilizing multi-center knowledge to pick out coaching, inside validation, and exterior validation units. Subsequently, consultants annotated the important thing anatomical constructions in FAUSP pictures. Based mostly on these authentic pictures and their annotations, we utilized Okay-fold cross-validation to meticulously partition the information, coaching and evaluating the mannequin throughout varied coaching and validation units36. Lastly, the mannequin’s efficiency was evaluated on inside and exterior validation cohorts utilizing customary metrics. Grad-CAM visualization was additional utilized to spotlight the picture areas most related to the predictions, thereby enhancing interpretability and facilitating comparability with medical reasoning.
General workflow of this examine. (I) Information acquisition; (II) Information annotation; (III) Deep studying mannequin for FAUSP-NET prediction; (IV) Mannequin analysis and evaluation.
Information acquisition and annotation
From Could 2021 to February 2024, we collected 6905 FAUSP pictures from 3209 pregnant ladies at Fujian Medical College Second Affiliated Hospital, Quanzhou Kids’s Hospital, and Quanzhou First Hospital Affiliated to Fujian Medical College. The typical age of those ladies was 33 ± 2 years, and all had been of their mid-pregnancy (18 to 24 + 6 weeks). These pictures originated from quite a lot of totally different gear varieties, together with Resona 8 (Mindray, China), Voluson E6 (GE Healthcare, USA), Voluson E8 (GE Healthcare, USA), Voluson E10 (GE Healthcare, USA), HI Imaginative and prescient Preiru (Hitachi, Japan), Aixplorer (Acoustics, France), Erlangshen (Hitachi, Japan), and Sequoia 512 (Siemens, Germany). After screening, 145 blurry pictures from 48 pregnant ladies and 83 pictures from 30 pregnant ladies with incomplete knowledge had been excluded. The remaining pictures had been allotted right into a coaching set (80%, totaling 5159 pictures) and a validation set (20%, totaling 1290 pictures). We meticulously chosen 1 to three pictures from every pregnant girl, making certain knowledge high quality and representativeness. Particularly, pictures had been required to (i) meet the diagnostic requirements of fetal stomach ultrasound planes with clearly seen key anatomical constructions, (ii) have good general picture high quality with out movement artifacts or extreme noise, and (iii) be consultant of the person case to make sure dataset variety whereas avoiding redundancy. The precise knowledge choice and allocation course of is proven in Fig. 3. Throughout the mannequin coaching course of, varied knowledge augmentation methods together with mirroring, rotation, scaling, picture saturation, and distinction adjustment had been employed to reinforce the mannequin’s robustness and efficiency throughout totally different settings. Particularly, rotation was utilized inside ± 10°, translation as much as 10% of the picture measurement, scaling components between 0.5 and 1.5, brightness and distinction changes inside ± 0.2, horizontal flipping with a chance of 0.5, and saturation or hue shifts inside an element of ± 0.1. These augmentation methods and parameter ranges are derived from the built-in Yolov8 framework, which contains broadly adopted settings in medical picture evaluation. This strategy aids in optimizing mannequin efficiency, making certain effectivity and accuracy in sensible functions. The examine acquired approval from the ethics committees of Fujian Medical College Second Affiliated Hospital, Quanzhou Kids’s Hospital, and Quanzhou First Hospital Affiliated to Fujian Medical College ([2024] Fuzhou Second Affiliated Hospital of Fujian Medical College Ethics Approval No. (395)). All individuals offered written knowledgeable consent to take part within the examine, and all strategies had been carried out in accordance with related pointers and laws. Moreover, to validate the mannequin’s generalization functionality, we chosen 228 FAUSP pictures from 75 pregnant ladies at Quanzhou First Hospital Affiliated to Fujian Medical College. These pictures weren’t used throughout the mannequin coaching course of and had been reserved for exterior knowledge validation.
All knowledge annotations had been collectively carried out by two medical doctors with in depth medical expertise. One physician used the open-source annotation device LabelImg to exactly mark the important thing options throughout the FAUSP pictures37. After the preliminary annotations had been accomplished, the second clinician reviewed the annotations made by the primary clinician to make sure that all anatomical constructions had been precisely annotated. In circumstances of disagreement, the 2 clinicians engaged in thorough discussions to succeed in a consensus on the annotation outcomes. This course of not solely ensured the standard and accuracy of the information but additionally successfully eradicated potential subjective biases, thereby making certain the reliability of subsequent analysis and evaluation.
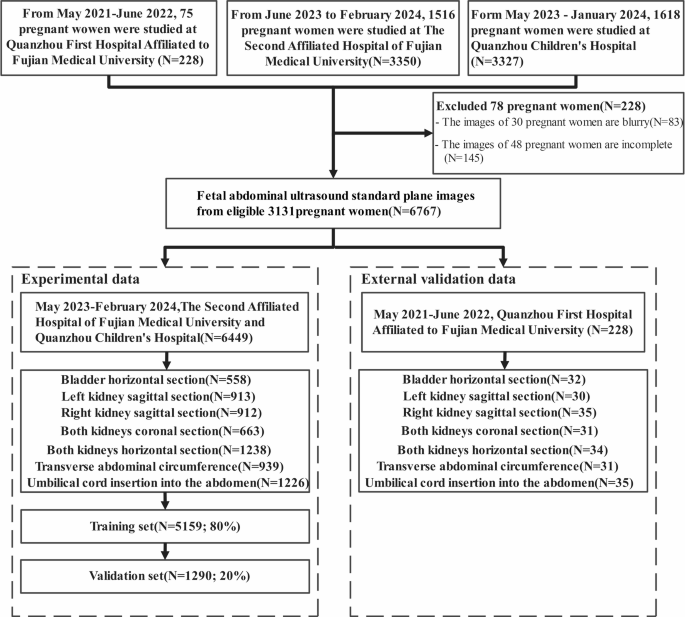
Flowchart of information set distribution.
The multi-task mannequin
On this examine, FAUSP-NET employs a unified MTL framework to detect 14 key anatomical constructions and classify 7 FAUSP concurrently, attaining excessive accuracy and real-time efficiency by eliminating redundant computations in comparison with single-task fashions, and the community construction of FAUSP-NET is proven in Fig. 4. Within the object detection process, the mannequin supplies essential assist for screening fetal stomach ailments by detecting key anatomical options in FAUSP pictures in real-time. Within the classification process, the mannequin successfully identifies varied customary planes based mostly on the outcomes from the anatomical construction detection module, thereby enhancing diagnostic accuracy.

The construction of FAUSP-NET mannequin.
Impressed by Yolov8, the most recent technology of object detection know-how recognized for its superior community structure and processing effectivity, our mannequin has been improved and optimized based mostly on the Yolov8 framework38. The spine community performs a vital function in extracting shared shallow options, and we have now made a number of enhancements to the unique spine community of Yolov8. Specifically, residual constructions had been integrated to facilitate deeper characteristic studying whereas sustaining efficient gradient propagation, thereby decreasing the chance of vanishing gradients in deep networks.
Within the structure, the enter picture sizes of 720 × 370, 768 × 576, and 1260 × 910 are adaptively resized to a uniform dimension of 640 × 640 pixels following the minimal padding rule, preserving the true pixel measurement of the unique pictures by way of strategies equivalent to sustaining side ratio, edge padding, and cropping. This strategy successfully reduces knowledge redundancy. Furthermore, throughout the picture preprocessing stage, we make the most of the Mosaic knowledge augmentation method, which not solely decreases the dependency on batch measurement but additionally enhances the generalization functionality of the dataset and alleviates the burden on {hardware} assets to some extent. Moreover, to extend coaching effectivity and speed up mannequin convergence, our community is provided with batch normalization (BN) layers after every convolutional layer, adopted by Rectified Linear Unit (ReLU) activation features which optimize the general efficiency of the community.
The thing detection module of our examine integrates the design rules of the PANet community by using a hybrid technique of the Characteristic Pyramid Community (FPN) and Path Aggregation Community (PAN) to ascertain an environment friendly multi-scale characteristic integration structure. The underside-up integration technique of the FPN facilitates the seize of high-level semantic data, considerably enhancing the mannequin’s capability to acknowledge smaller or much less distinct anatomical markers. Concurrently, the top-down pathway of the PAN enhances the spatial localization capabilities of decrease layers, making certain correct transmission of spatial data within the higher-level characteristic maps. We generate deep fusion characteristic maps at three totally different scales (massive, medium, and small), integrating each shallow spatial options and deep semantic options. By optimizing the sizes of anchor packing containers by way of adaptive strategies, we will exactly delineate the bounding packing containers of anatomical constructions, thereby enhancing the accuracy of fetal stomach construction detection. Subsequently, 1 × 1 convolutions are employed to increase these characteristic maps, leading to three particular detection characteristic layer outputs. Lastly, the Tender Non-Most Suppression (Tender-NMS) algorithm is utilized to regulate the arrogance scores of overlapping predictions, enhancing the dealing with of overlaps in multi-object detection and minimizing the lack of helpful data39. This strategy precisely locates and identifies key anatomical constructions, with the ultimate output together with confidence scores and predicted classes for 14 FAUSP anatomical constructions.
In our examine, we use the detection outcomes of key constructions in fetal stomach ultrasound pictures to establish customary planes. In accordance with medical requirements, we outline the usual fetal stomach ultrasound planes as follows: ACS ought to show the umbilical vein (UV), inferior vena cava (IVC), abdomen bubble (ST), and stomach aorta (AO); UCS ought to clearly present the SP and umbilical CORD; BHS ought to exhibit the bladder (BL) and UAS; BKHS ought to show the kidney (Okay) and SP; LKS ought to present the left kidney (LK), ST, diaphragm (DI), and SP; RKS ought to current the fitting kidney (RK), DI, and SP; BKCS ought to embody the Okay, umbilical artery (IB), AO, and RIB. The precise identification course of is as follows: First, we outline the goal class dictionary P for every customary aircraft as: ACS: [UV, IVC, ST, AO], UCS: [SP, CORD], BHS: [BL, UAS], BKHS: [K, SP], LKS: [LK, ST, DI, SP], RKS: [RK, DI, SP], BKCS: [K, IB, AO, RIB]. Subsequent, based mostly on the detection outcomes which embody confidence rating, class, and bounding field coordinates (x1, y1, x2, y2), we choose the category with the very best confidence because the goal marker. Lastly, by verifying whether or not these predicted targets utterly match the predefined goal listing for the usual aircraft, we verify whether or not the ultrasound picture corresponds to the usual aircraft and output the variety of detected objects and the class of the FAUSP. The design of FAUSP-NET successfully overcomes the challenges of time-consuming and error-prone identification processes that may result in non-standard choices. It doesn’t depend on in depth pre-training with massive datasets however performs inference instantly from detection outcomes. This strategy not solely considerably reduces coaching time and reminiscence necessities but additionally accelerates the implementation of FAUSP-NET, aligning the inference course of intently with medical judgment workflows. This makes FAUSP-NET extra appropriate for medical functions and supplies higher interpretability and intuitiveness.
Hybrid consideration mechanism in multi-task mannequin networks
In contrast with single-type consideration, hybrid consideration can leverage the strengths of a number of mechanisms, enabling extra complete characteristic illustration and improved mannequin robustness40. Ultrasound pictures sometimes endure from low distinction and noise contamination, which considerably impacts the visibility of inside structural options of tissues. To extra successfully deal with key options throughout the FAUSP, we have now integrated an Environment friendly Channel Consideration (ECA) module into the foundational a part of our mannequin41. The ECA module, by way of its light-weight and parameter-free design, optimizes the processing of FAUSP pictures by specializing in channel-level options, thereby enhancing the precision in recognizing essential anatomical constructions. This module adaptively extracts key options from FAUSP pictures, aiding in enhancing the mannequin’s generalization capabilities and decreasing overfitting, thus considerably enhancing efficiency. The working precept of the ECA module is detailed in Fig. 5, the place GAP refers to International Common Pooling, Okay denotes the kernel measurement used within the 1D convolution for channel interplay, and σ represents the sigmoid activation perform. Based mostly on the ECA module, we have now designed two totally different convolutional constructions: EConv1 and EConv2. EConv1 features a residual connection, which helps keep data movement and prevents gradient vanishing points in deep networks. The residual connection permits main options to be instantly transmitted to subsequent layers, which reinforces the effectivity of characteristic switch and improves the community’s capability to study essential options of the fetal stomach. This permits the mannequin to extra successfully acknowledge and parse advanced anatomical constructions. EConv2, by simplifying the connection construction, successfully will increase computational effectivity, attaining quicker and extra environment friendly characteristic fusion and processing.

Particulars of the Environment friendly Channel Consideration (ECA).
Moreover, the anatomical constructions in FAUSP pictures should not solely numerous and widespread but additionally exhibit similarities amongst totally different constructions, rising the complexity of recognition and evaluation. To accommodate the multiscale nature of fetal stomach anatomical constructions and handle the problem of distinguishing related pictures and anatomical constructions in FAUSP, we have now launched a spatial consideration module referred to as the Massive Selective Kernel Block (LSKblock)42, the detailed means of LSKblock is proven in Fig. 6. On this module, neurons can adaptively regulate their receptive discipline measurement based mostly on the dimensions of the enter data, successfully capturing anatomical constructions of varied sizes within the fetal stomach, thereby enhancing the accuracy of identification and evaluation of varied anatomical particulars. The method is as follows: Initially, the module receives options X from fetal stomach ultrasound FAUSP pictures and reduces computational complexity and will increase processing effectivity by decomposing a big convolutional kernel into two 1 × 1 convolution operations, (:{mathcal{F}}_{1}^{1times:1})and (:{mathcal{F}}_{2}^{1times:1}). These two characteristic maps,(:stackrel{sim}{:U})1 and (:stackrel{sim}{:U})2, are then merged by way of channel concatenation, integrating anatomical options extracted by totally different kernels. Subsequently, the mixed characteristic map undergoes common pooling and max pooling to scale back knowledge dimensions, adopted by additional refinement by way of a convolutional layer. Lastly, key areas within the picture are enhanced utilizing a Sigmoid perform to supply the processed characteristic map S. This characteristic map is element-wise multiplied with the unique spatial characteristic map (:mathcal{F}) to selectively improve options of essential anatomical constructions. The improved characteristic map is then element-wise added to S to additional refine characteristic expression, and the ultimate output Y is obtained by way of element-wise multiplication. This processing considerably improves the visualization high quality of essential anatomical constructions, thus drastically enhancing the diagnostic effectivity of fetal stomach pictures.

The detailed means of the Massive Selective Kernel Block (LSKblock).
We’ve got built-in an Environment friendly Multi-Scale Consideration (EMA) mechanism into the bottleneck part of our mannequin43. As illustrated in Fig. 7, the EMA consideration mechanism first divides the enter FAUSP pictures into a number of teams, with every group containing knowledge of measurement C//G×H×W, the place C represents the variety of channels, H is the peak, W is the width, and G is the variety of teams. Every group undergoes common pooling in each the X and Y instructions, leading to characteristic maps of measurement C//G×H×1 and C//G×1×W, respectively. Concurrently, a 3 × 3 convolution operation is utilized to every group, producing characteristic maps of the identical measurement. This step extracts fundamental options from the FAUSP pictures. The pooled characteristic maps are then concatenated and processed by way of a 1 × 1 convolution, producing characteristic maps of measurement C//G×1 × 1. These characteristic maps are activated utilizing a Sigmoid perform, leading to new weighted characteristic maps. Subsequently, these characteristic maps bear Group Normalization and are then common pooled in each top and width instructions, producing characteristic maps of measurement C//G×1 × 1. Subsequent, they’re activated utilizing the Softmax perform and mixed by way of matrix multiplication to reinforce the inter-feature connections and the mannequin’s sensitivity to the FAUSP picture content material. These processed characteristic maps are additional refined by one other spherical of matrix multiplication and re-weighted utilizing the Sigmoid perform, which reinforces the nonlinearity and discriminative capability of the options, considerably enhancing the general recognition functionality of FAUSP-NET. Lastly, the mannequin outputs the processed pictures. Via these steps of grouping, convolutional processing, and subsequent characteristic recombination, the mannequin successfully extracts and weights key data throughout the FAUSP pictures, additional enhancing the accuracy of detecting FAUSP anatomical constructions.

The detailed means of the Environment friendly Multi-Scale Consideration (EMA) mechanism.
Multi-task mannequin loss perform
Within the process of detecting FAUSP anatomical constructions, we launched a novel Focal and environment friendly IOU loss perform (:left({L}_{Foca{l}_{_EIoU}}proper)) loss to deal with the problem of picture imbalance44. This loss perform particularly targets exhausting to categorise samples and targets with ambiguous boundaries, considerably enhancing the mannequin’s efficiency in these advanced situations and thus drastically enhancing the detection accuracy and robustness of the system. The entire (:{L}_{loss}) of the mannequin consists of three elements:(:{L}_{Focal}), (:{L}_{EIoU}), and (:{L}_{obj}). The weights for these elements(::{lambda:}_{1}),(:{lambda:}_{2})and (:{lambda:}_{3}:)are set at 0.7, 0.5, and 0.5, respectively. These weight settings assist steadiness the affect of various losses throughout coaching, making certain extra correct detection outcomes. The precise computation of the loss is detailed in Eqs. (1) and (2).
$$:{L}_{loss}={lambda:}_{1:}{L}_{Focal}+{lambda:}_{2}{L}_{EIoU}+{lambda:}_{3}{L}_{obj}$$
(1)
$$:{L}_{Focal_EIoU}={lambda:}_{1:}{L}_{Focal}+{lambda:}_{2}{L}_{EIoU}$$
(2)
(:{L}_{Focal}) loss successfully addresses class imbalance points. On this formulation, (:{p}_{t,c}in:left(textual content{0,1}proper)) represents the mannequin’s predicted chance for the true class (:c), the place (:{p}_{t,c})=0 signifies the mannequin is totally sure that the enter doesn’t belong to class (:c), and (:{p}_{t,c})=1 signifies full certainty that the enter belongs to class (:c). The time period (:{alpha:}_{c}in:left(textual content{0,1}proper)) is the load assigned to class(::c), as (:{alpha:}_{c}) approaches 0, the mannequin’s deal with that class is diminished, whereas as (:{alpha:}_{c}) approaches 1, the main focus is elevated. The parameter (:gamma:) is the focusing parameter. By adjusting the loss perform. (:{L}_{Focal}) considerably enhances the mannequin’s robustness and generalization capability when coping with minority lessons in FAUSP pictures, making the mannequin pay extra consideration to these lessons which are tough to acknowledge. The precise computation is detailed in Eq. (3).
$$:{L}_{Focal}={-{alpha:}_{c}(1-{p}_{t,C})}^{gamma:}:{log}left({p}_{t,C}proper)$$
(3)
(:{L}_{EIoU}) loss is an extension of the normal Intersection over Union (IoU) loss, primarily utilized in object detection duties to reinforce the localization accuracy of bounding packing containers. The precise formulation is proven in Eqs. (4) and (5), The place (:{b}_{pred}:textual content{a}textual content{n}textual content{d}:{b}_{gt}) characterize the expected and floor fact bounding packing containers, respectively.(:rho:)denotes the Euclidean distance between the facilities of the expected and true bounding packing containers, and (:c) is the diagonal size of the smallest enclosing field protecting each the expected and true bounding packing containers.(::alpha:) is a scaling issue used to regulate the contribution of side ratio variations within the complete (:{L}_{EIoU}) loss.(::{w}_{pred}) and(::{h}_{pred})are the width and top of the expected field, respectively, whereas (:{w}_{gt}) and (:{h}_{gt}) are the width and top of the bottom fact field.
$$:IoU=frac{|{b}_{pred}cap:{b}_{gt}|}{|{b}_{pred}cup:{b}_{gt}|}$$
(4)
$$:{L}_{EIoU}=1-IoU+frac{{rho:}^{2}left({b}_{pred},{b}_{gt}proper)}{{c}^{2}}+alpha:left(frac{left|{w}_{pred}-{w}_{gt}proper|+|{h}_{pred}-{h}_{gt}|}{{w}_{pred}+{h}_{pred}+{w}_{gt}+{h}_{gt}}proper)$$
(5)
(:{textual content{T}textual content{h}textual content{e}:L}_{obj}) loss is a binary cross-entropy loss, primarily used to evaluate whether or not a goal really exists inside every predicted bounding field and to precisely consider the mannequin’s confidence in its predictions. (:N) represents the variety of bounding packing containers thought-about within the loss computation.(:{:y}_{i}) is the true label for the (:i) bounding field, the place (:{y}_{i}=0) signifies no object is current, and (:{y}_{i}=1) signifies the presence of an object. (:{v}_{i}) is the mannequin’s authentic predicted rating for the (:i) field. The precise calculation formulation is proven in Eqs. (6) and (7).
$$:pleft(yright)=frac{1}{1+exp(-x)}$$
(6)
$$:{L}_{obj}=:-frac{1}{N}sum:_{i}^{N}[{y}_{i}cdot:{log}left(pleft({v}_{i}right)right)+(1-{y}_{i}cdot :log(1-p({v}_{i}left)right)]$$
(7)
Statistical evaluation
Statistical evaluation was carried out utilizing SPSS software program, model 30.0.0. A paired t-test was employed to judge efficiency variations between fashions on paired pattern datasets. By evaluating the detection outcomes from varied fashions, this check helps to find out whether or not modifications within the fashions have led to important efficiency variations underneath constant experimental situations. A significance stage of p < 0.05 was adopted to evaluate statistical significance. If the p-value falls under this threshold, it signifies a significant distinction in efficiency between the fashions, suggesting substantial results from the modifications. This technique affords a rigorous strategy to evaluate the affect of mannequin enhancements in scientific analysis.