



Tencent AI Lab has launched Covo-Audio, a 7B-parameter end-to-end Massive Audio Language Mannequin (LALM). The mannequin is designed to unify speech processing and language intelligence by straight processing steady audio inputs and producing audio outputs inside a single structure.
System Structure
The Covo-Audio framework consists of 4 main elements designed for seamless cross-modal interplay:
- Audio Encoder: The mannequin makes use of Whisper-large-v3 as its main encoder attributable to its robustness in opposition to background noise and various accents. This part operates at a body fee of 50 Hz.
- Audio Adapter: To bridge the encoder and the LLM, a specialised adapter employs three downsampling modules, integrating linear and convolution layers to cut back the body fee from 50 Hz to six.25 Hz.
- LLM Spine: The system is constructed upon Qwen2.5-7B-Base, which has been tailored to course of interleaved sequences of steady acoustic options and textual tokens.
- Speech Tokenizer and Decoder: The tokenizer, primarily based on WavLM-large, makes use of a codebook measurement of 16,384 to supply discrete audio tokens at 25 Hz. The decoder employs a Movement-Matching (FM) primarily based framework and a BigVGAN vocoder to reconstruct high-fidelity 24K waveforms.
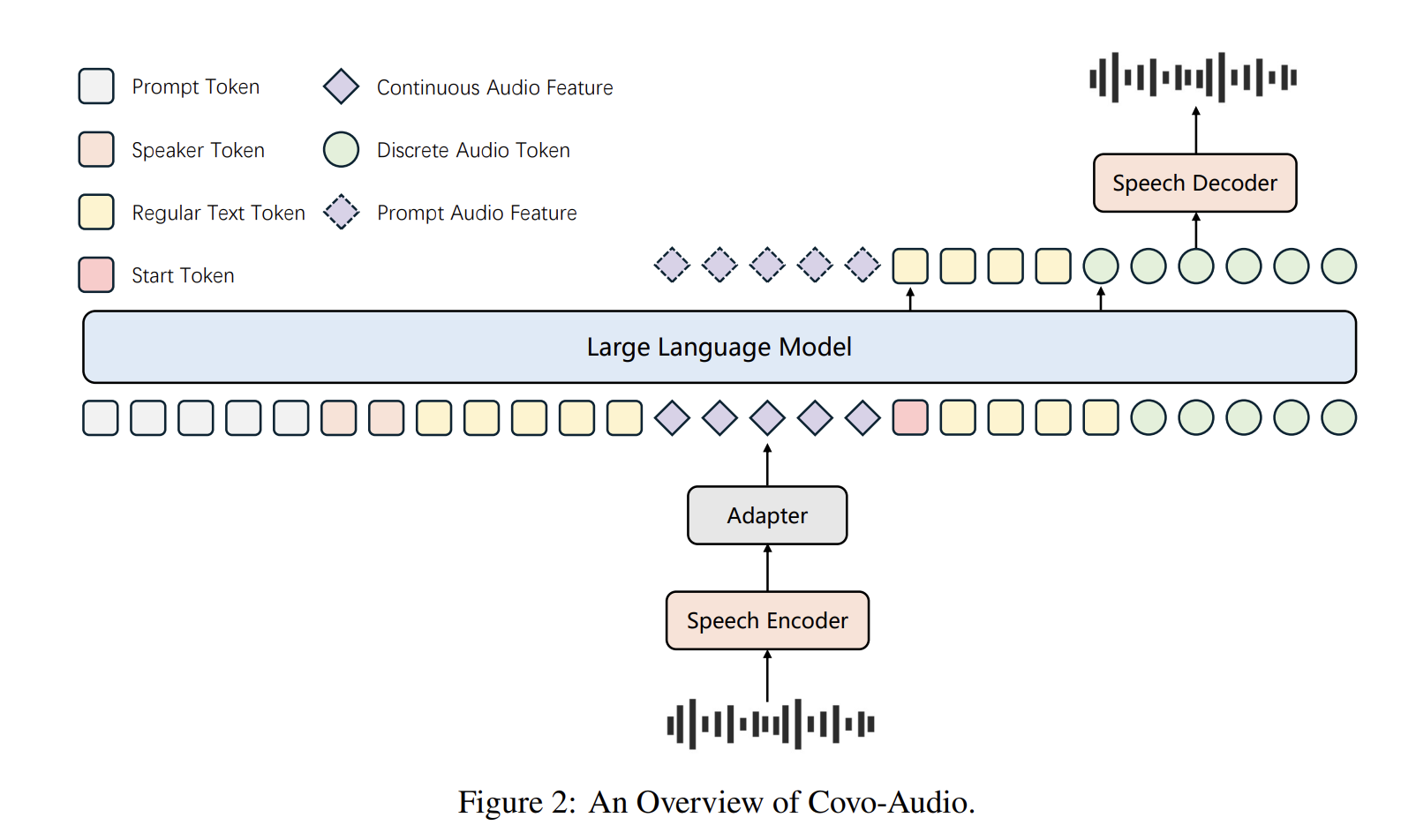
Hierarchical Tri-modal Interleaving
A core contribution of this work is the Hierarchical Tri-modal Speech-Textual content Interleaving technique. Not like conventional strategies that function solely on the phrase or character degree, this framework aligns steady acoustic options , discrete speech tokens , and pure language textual content .
The mannequin makes use of two main patterns:
- Sequential Interleaving : Steady options, textual content, and discrete tokens are organized in a progressive chain.
- Parallel Integration : Steady options are aligned with a coupled text-discrete unit.
The hierarchical facet ensures structural coherence through the use of phrase-level interleaving for fine-grained alignment and sentence-level interleaving to protect international semantic integrity in long-form utterances. The coaching course of concerned a two-stage pre-training pipeline processing a complete of 2T tokens.
Intelligence-Speaker Decoupling
To mitigate the excessive price of establishing large-scale dialogue knowledge for particular audio system, the analysis workforce proposed an Intelligence Speaker Decoupling technique. This method separates dialogue intelligence from voice rendering, permitting for versatile voice customization utilizing minimal text-to-speech (TTS) knowledge.
The tactic reformats high-quality TTS recordings into pseudo-conversations with masked textual content loss. By excluding the textual content response portion from the loss calculation, the mannequin preserves its reasoning talents whereas inheriting the naturalness of the TTS speaker. This allows customized interplay with out the necessity for in depth, speaker-specific dialogue datasets.
Full-Duplex Voice Interplay
Covo-Audio advanced into Covo-Audio-Chat-FD, a variant able to simultaneous dual-stream communication. The audio encoder is reformatted right into a chunk-streaming method, and the person and mannequin streams are chunk-interleaved in a 1:4 ratio. Every chunk represents 0.16s of audio.
The system manages conversational states by way of particular architectural tokens:
- THINK Token: Signifies a listening-only state whereas the mannequin waits to reply.
- SHIFT Token: Signifies the transition to the mannequin’s talking flip.
- BREAK Token: Detects interruption indicators (barge-ins), triggering the mannequin to terminate talking instantly and change again to listening.
For multi-turn situations, the mannequin implements a recursive context-filling technique, the place steady audio options from person enter and generated tokens from earlier turns are prefixed as historic context.
Audio Reasoning and Reinforcement Studying
To boost complicated reasoning, the mannequin incorporates Chain-of-Thought (CoT) reasoning and Group Relative Coverage Optimization (GRPO). The mannequin is optimized utilizing a verifiable composite reward operate:
$$R_{complete} = R_{accuracy} + R_{format} + R_{consistency} + R_{considering}$$
This construction permits the mannequin to optimize for correctness , structured output adherence , logical coherence , and reasoning depth .
Analysis and Efficiency
Covo-Audio (7B) exhibits aggressive or superior outcomes on a number of evaluated benchmarks, with strongest claims made for fashions of comparable scale and chosen speech/audio duties. On the MMAU benchmark, it achieved a mean rating of 75.30%, the best amongst evaluated 7B-scale fashions. It notably excelled in music understanding with a rating of 76.05%. On the MMSU benchmark, Covo-Audio achieved a number one 66.64% common accuracy.
Concerning its conversational variants, Covo-Audio-Chat demonstrated sturdy efficiency on URO-Bench, significantly in speech reasoning and spoken dialogue duties, outperforming fashions like Qwen3-Omni on the Chinese language monitor. For empathetic interplay on the VStyle benchmark, it achieved state-of-the-art ends in Mandarin for anger (4.89), unhappiness (4.93), and anxiousness (5.00).
The analysis workforce notes an ‘early-response’ subject on the GaokaoEval full-duplex setting, the place unusually lengthy silent pauses between vocal fragments may cause untimely responses. This ‘early-response’ habits correlates with the mannequin’s pause-handling success metric and is recognized as a vital path for future optimization.
Key Takeaways
- Unified Finish-to-Finish Structure: Covo-Audio is a 7B-parameter mannequin that natively processes steady audio inputs and generates high-fidelity audio outputs inside a single, unified structure. It eliminates the necessity for cascaded ASR-LLM-TTS pipelines, lowering error propagation and data loss.
- Hierarchical Tri-modal Interleaving: The mannequin employs a specialised technique to align steady acoustic options, discrete speech tokens, and pure language textual content. By interleaving these modalities at each phrase and sentence ranges, it preserves international semantic integrity whereas capturing fine-grained prosodic nuances.
- Intelligence-Speaker Decoupling: Tencent analysis workforce introduces a method to decouple dialogue intelligence from particular voice rendering. This enables for versatile voice customization utilizing light-weight Textual content-to-Speech (TTS) knowledge, considerably decreasing the price of creating customized conversational brokers.
- Native Full-Duplex Interplay: The Covo-Audio-Chat-FD variant helps simultaneous listening and talking. It makes use of particular architectural tokens—THINK, SHIFT, and BREAK—to handle complicated real-time dynamics similar to clean turn-taking, backchanneling, and person barge-ins.
- Superior Parameter Effectivity: Regardless of its compact 7B scale, Covo-Audio achieves state-of-the-art or extremely aggressive efficiency throughout core benchmarks, together with MMAU, MMSU, and URO-Bench. It ceaselessly matches or exceeds the efficiency of a lot bigger techniques, similar to 32B-parameter fashions, in audio and speech understanding duties.
Try the Paper, Mannequin on HF and Repo. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.