



A manufacturing internals information verified in opposition to Kubernetes 1.35 GA
Companion repository: github.com/opscart/k8s-pod-restart-mechanics
The terminology drawback
Engineers say “the pod restarted” once they imply 4 various things. Getting this flawed results in flawed runbooks and unhealthy on-call selections.
| Time period | Pod UID Adjustments? | Pod IP Adjustments? | Restart Rely |
| Container restart (course of restart inside the identical pod) | No | No | +1 |
| Pod recreation (rolling replace, drain) | Sure | Sure | Resets to 0 |
| In-place resize (1.35 GA) — CPU | No | No | 0 |
| In-place resize (1.35 GA) — reminiscence (RestartContainer coverage) | No | No | +1 |
The sensible check: Did the pod UID change? If sure — that’s recreation, not a container restart. Restart rely resets to zero. If no — identical pod object, container course of restarted inside it.
The core perception: What kubelet really watches
kubelet watches the pod spec — not ConfigMaps, not Secrets and techniques, not Istio CRDs. If the pod spec didn’t change, kubelet by no means fires. This single truth explains nearly all of “why didn’t my config update?” investigations in manufacturing.
Mutating admission webhooks can change the pod spec at creation time, however by no means after admission — they can not set off container restarts post-creation.
Choice matrix
| Change | Container Restart? | Pod Recreated? | Automated? |
| Container picture | Sure | Sure | Sure — Deployment controller |
| Env var (any supply) | Sure | No | Guide rollout |
| ConfigMap — quantity mount | App decides | No | Partial — app should watch inotify |
| ConfigMap — envFrom | Sure | No | Guide rollout |
| Secret — quantity mount | App decides | No | Partial — app should watch inotify |
| Secret — envFrom | Sure | No | Guide rollout |
| Projected ServiceAccount token | By no means | No | Sure — kubelet auto-rotates |
| CPU resize (K8s 1.35+) | By no means | No | Guide patch |
| Reminiscence resize (K8s 1.35+) | Per resizePolicy | No | Guide patch |
| Istio VirtualService / DestinationRule | By no means | No | Sure — xDS push |
| NetworkPolicy | By no means | No | Sure — CNI agent |
| Service ports | By no means | No | Sure — kube-proxy |
| RBAC | By no means | No | Sure — API server |
| Node drain / eviction | Sure | Sure | Sure — automated |
The flowchart under interprets the identical matrix into a call path you possibly can stroll at 2am throughout an incident.
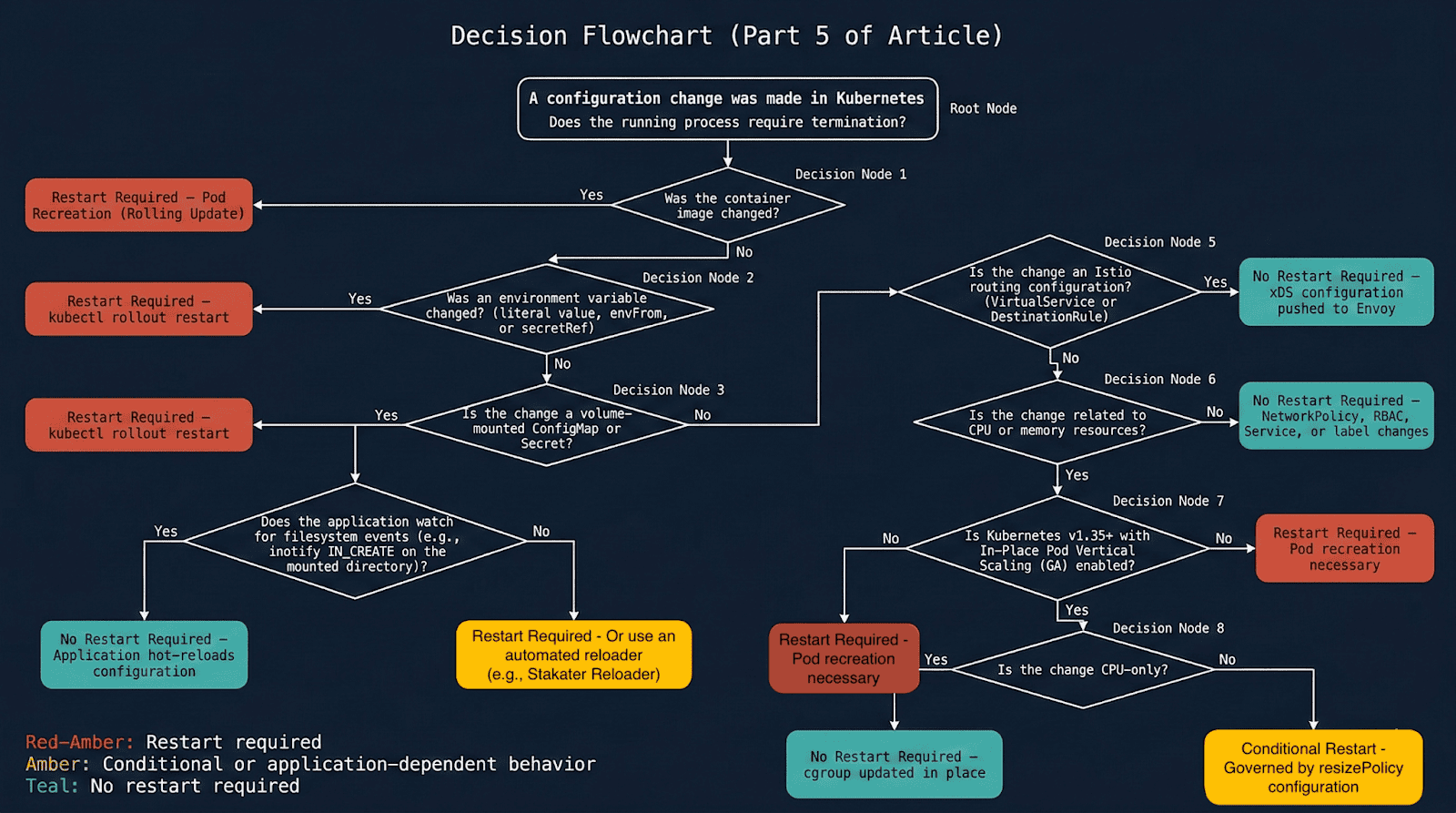
Diagram 1: Full determination flowchart — does this alteration require a pod restart?
Situation 1: ConfigMap — Why the identical change has two behaviors
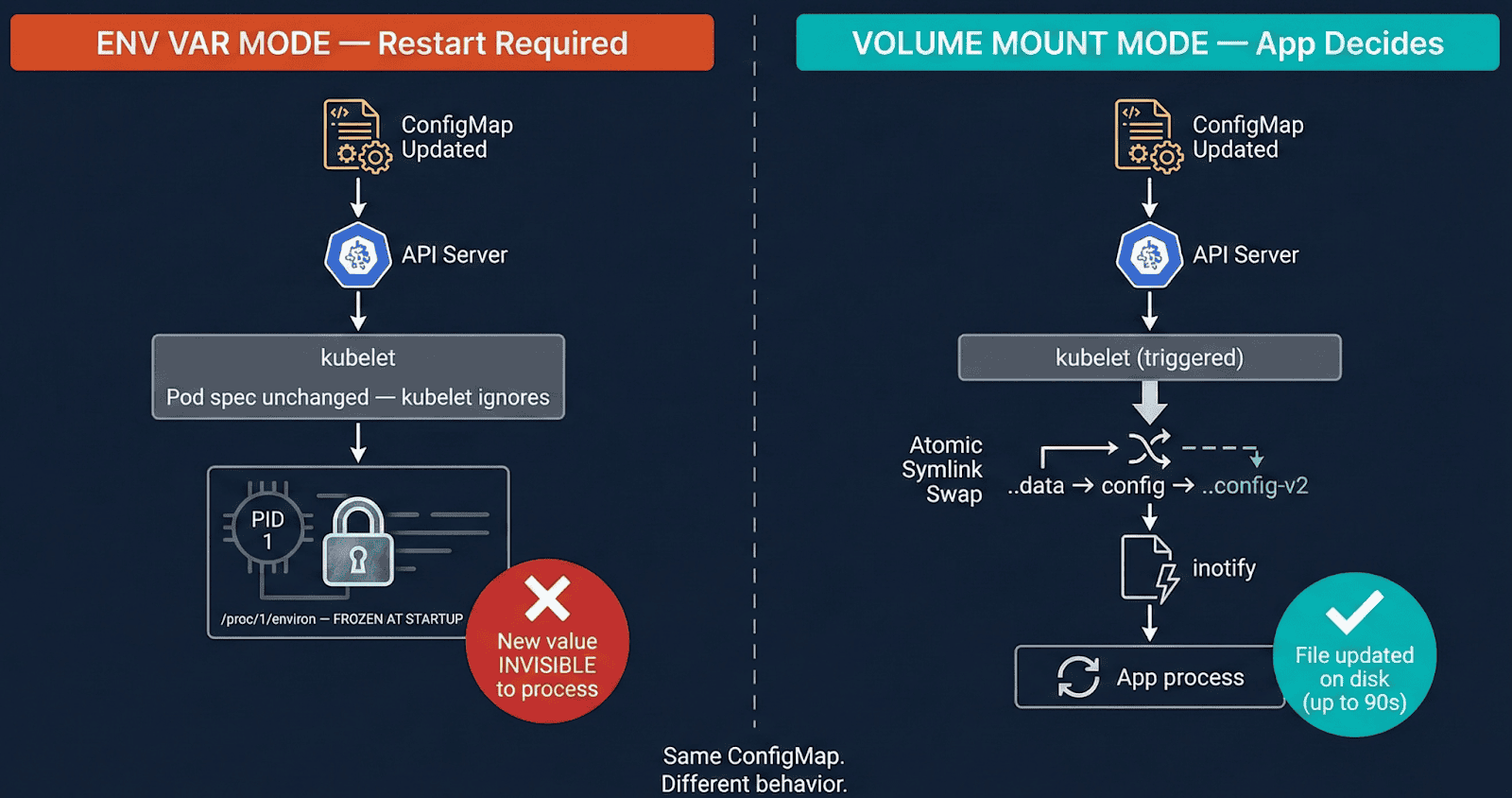
[Diagram 1: ConfigMap env var vs volume mount — env var pod frozen, volume pod auto-synced via kubelet symlink swap]
Env var mode (envFrom / valueFrom): The kernel copies env vars into /proc/at execve(). That reminiscence is owned by the method — no exterior system can modify it. Replace the ConfigMap and kubelet sees no pod spec change, does nothing. The method retains previous values indefinitely.
Quantity mount mode: kubelet syncs by way of an atomic symlink swap, not a file write:
/and many others/config/
├── ..2025_12_19_11_30_00/ ← NEW knowledge dir (kubelet creates this)
│ └── APP_COLOR ← "red"
├── ..knowledge ─────────────────▶ ..2025_12_19_11_30_00/ ← symlink SWAPPED atomically
└── APP_COLOR ──────────────▶ ..knowledge/APP_COLOR
The symlink swap generates IN_CREATE on ..knowledge — NOT IN_MODIFY on the file. Functions watching IN_MODIFY on an open file descriptor miss this solely. Because of this nginx doesn’t auto-reload on ConfigMap adjustments with out express inotify dealing with.
Lab Proof (01-configmap/ in companion repo)
ConfigMap up to date: APP_COLOR blue → pink
Pod A (env var): APP_COLOR=blue ← frozen, restart rely: 0
Pod B (quantity mount): APP_COLOR=pink ← auto-synced, restart rely: 0
Right inotify sample — watch the listing, not the file
watcher.Add(filepath.Dir(configPath)) // watches /and many others/config/ — catches IN_CREATE
// watcher.Add(configPath) // misses symlink swap solely
for occasion := vary watcher.Occasions {
if occasion.Op&fsnotify.Create == fsnotify.Create {
reloadConfig()
}
}
Situation 2: Picture updates — Recreation vs container restart vs CrashLoop
These three eventualities look related however are essentially completely different:
Profitable picture replace — pod is recreated
BEFORE: Pod UID aaa-bbb, IP 10.244.1.5, nginx:1.25, restarts: 0
AFTER: Pod UID xxx-yyy, IP 10.244.1.6, nginx:1.27, restarts: 0
↑ UID modified — RECREATION, not container restart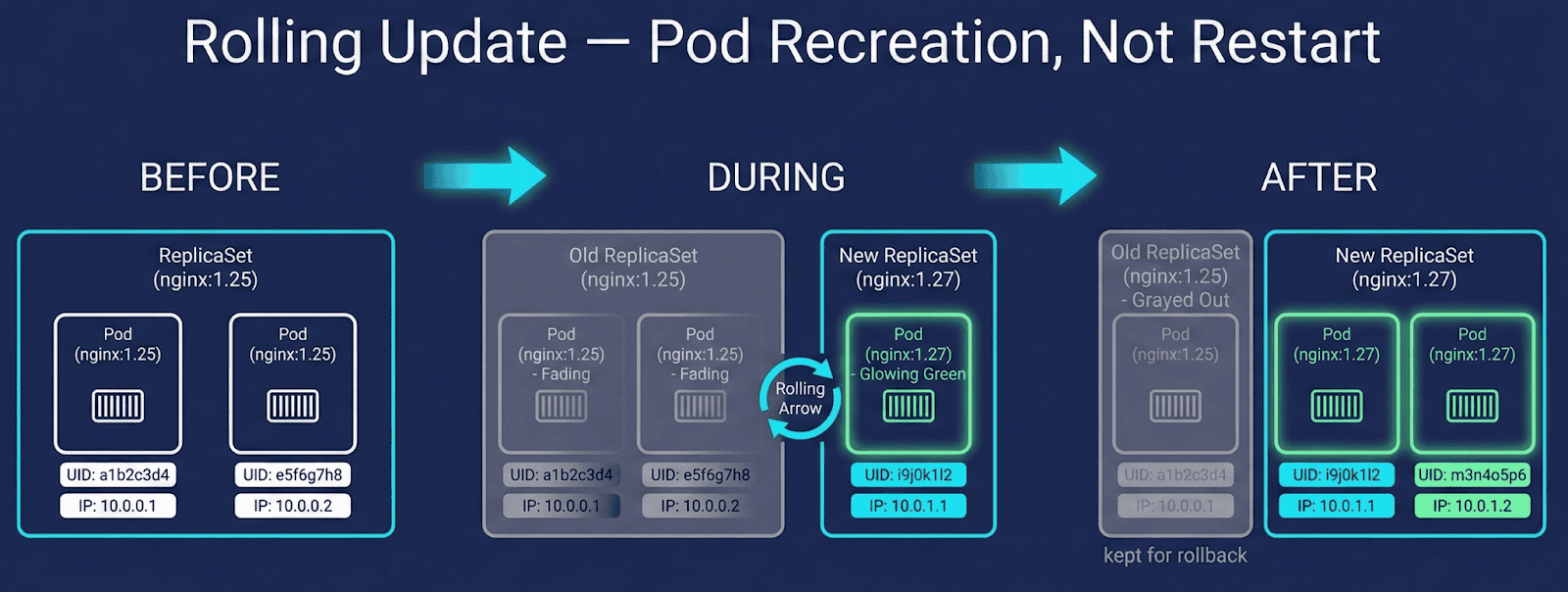
Diagram 3: Rolling replace circulation displaying new ReplicaSet creation, pod recreation, and previous RS retained for rollback.
ImagePullBackOff — previous pod stays protected
Previous pod: Working ← Kubernetes retains it alive
New pod: ImagePullBackOff ← caught, previous pod by no means killed till new one is wholesome
CrashLoopBackOff — identical pod, restart rely climbs
Pod UID: aaa-bbb ← UNCHANGED
Restart rely: 0 → 1 → 2 → 3 ← identical pod object, container crashing
Diagnostic rule: Climbing restart rely with unchanged UID = crash loop. Zero restart rely with new UID = rolling replace.
StatefulSet notice: StatefulSet pods are additionally recreated on picture change, however ordinal identification (pod-0, pod-1) and PVC bindings are preserved. Container restart semantics are an identical to Deployments — identification persistence doesn’t suggest in-place container restart.
Situation 3: In-place useful resource resize (K8s 1.35 GA)
K8s 1.35 made in-place pod resize usually out there (kubernetes.io/weblog/2025/12/19/kubernetes-v1-35-in-place-pod-resize-ga). Each CPU and reminiscence might be resized with out pod recreation — UID and IP by no means change. In-place resize availability is dependent upon CRI and node OS help; verified on containerd 1.7+ with Linux cgroups v2.
What occurs to the container is dependent upon resizePolicy, which you outline explicitly:
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired # cgroup quota up to date, course of untouched
- resourceName: reminiscence
restartPolicy: RestartContainer # container restarts inside identical pod
Lab Proof (05-resource-resize/ — requires K8s 1.35+)
CPU resize 200m → 500m (NotRequired):
UID: d7c99204 IP: 10.244.0.7 Restarts: 0 ← all unchanged
Reminiscence resize 256Mi → 512Mi (RestartContainer):
UID: d7c99204 IP: 10.244.0.7 Restarts: 1
↑ identical pod ↑ identical IP ↑ our coverage selection, not K8s forcing it
Essential: The default resizePolicy for reminiscence is NotRequired. In the event you omit it, reminiscence resize silently updates the cgroup with out restarting the container — and your JVM heap stays on the previous dimension. At all times outline resizePolicy explicitly for reminiscence.
How one can apply
kubectl patch pod my-pod -n my-namespace
--subresource resize
-p '{"spec":{"containers":[{"name":"app","resources":{
"requests":{"cpu":"250m","memory":"128Mi"},
"limits":{"cpu":"500m","memory":"256Mi"}
}}]}}'
# Notice: omit --type=merge — causes a validation error with --subresource resize
Situation 4: Istio routing — Zero restarts by way of xDS
Istio VirtualService and DestinationRule adjustments by no means set off container restarts. Istiod maintains a persistent bidirectional gRPC stream to every Envoy sidecar — routing updates are pushed in milliseconds, in-memory swap, no pod touched, no file written.
Lab Proof (04-istio-routing/ in companion repo)
4 pods. Three routing adjustments:
100% v1 → 80/20 canary → 100% v2
Restart counts: BEFORE 0 0 0 0 / AFTER 0 0 0 0
Pod ages: unchanged all through all three adjustments.
Situation 5: Stakater reloader — Automating the guide step
When apps eat ConfigMaps by way of env vars, somebody should run kubectl rollout restart after each replace. Reloader automates this utilizing Kubernetes watch occasions — detection is near-instant, not polling.
metadata:
annotations:
reloader.stakater.com/auto: "true"
Manufacturing gotcha: The default Helm set up makes use of watchGlobally=false — Reloader solely watches its personal namespace. Annotated Deployments in different namespaces are silently ignored, no error thrown. At all times set up with watchGlobally=true.
helm set up reloader stakater/reloader
--namespace reloader
--set reloader.watchGlobally=true
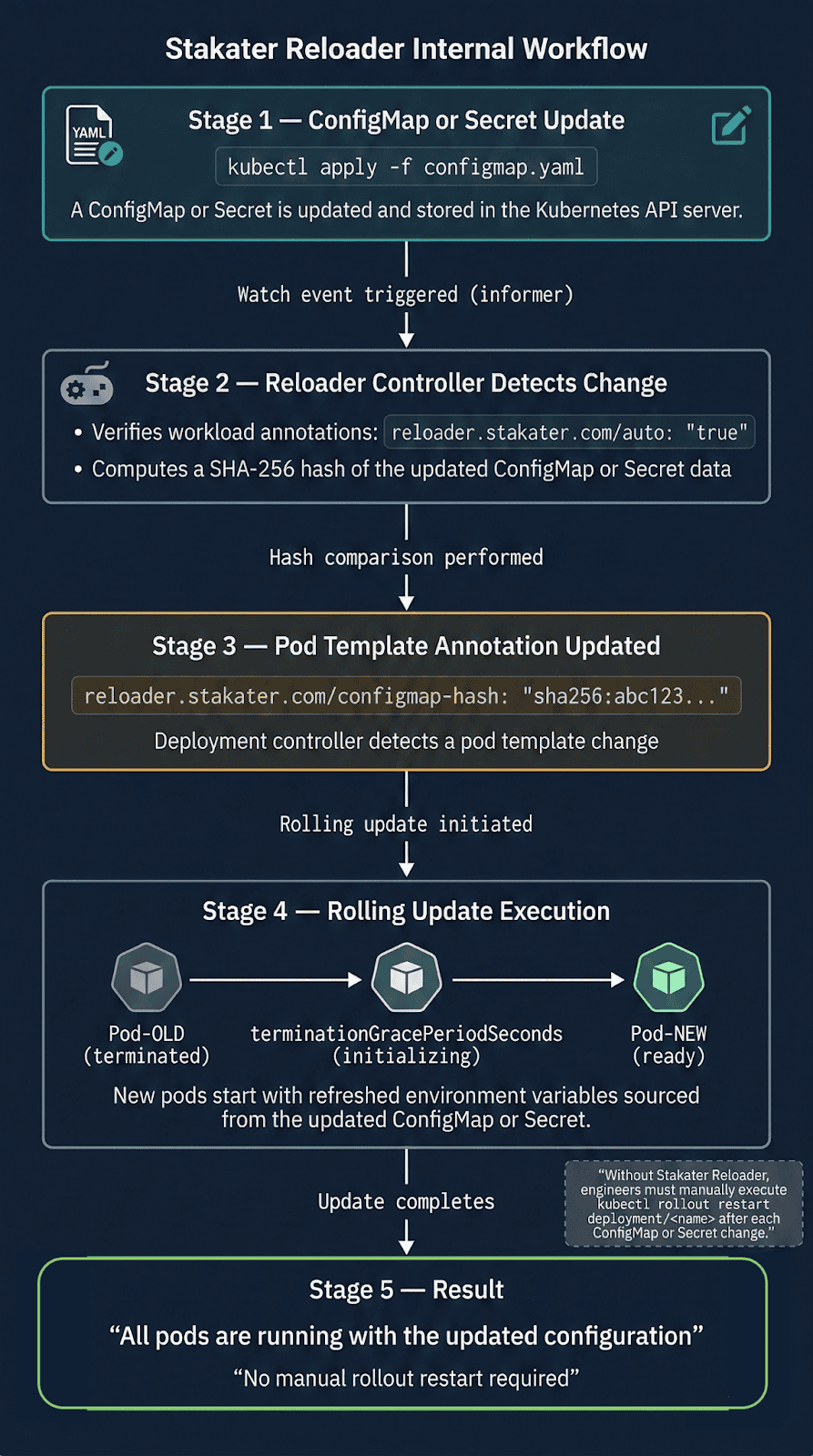
Lab Proof (07-stakater-reloader/ in companion repo)
ConfigMap up to date. No kubectl rollout restart run.
New pod APP_MESSAGE: "Hello from OpsCart v2 — auto reloaded!"
Rolling container restart triggered routinely.
When hot-reload goes flawed
Sizzling-reload will not be at all times safer than a container restart. Two failure modes price figuring out:
Semantically invalid config accepted silently
The file updates, the inotify handler fires, no error is thrown — however the brand new config has a logic error. The pod passes well being checks and runs damaged for hours. A container restart with a foul config fails instantly and loudly. Sizzling-reload with unhealthy config fails quietly and late.
Mitigation: Validate config earlier than swapping atomically.
Envoy rejects xDS push silently
Istiod pushes a RouteConfiguration referencing a cluster not but propagated. Envoy rejects it and continues with previous routing guidelines. No pod occasion fires. Mitigation: Monitor pilot_xds_push_errors and use istioctl proxy-status.
Observability: Three instructions each operator ought to know
# 1. Container restart or pod recreation? Test UID change
kubectl get pod -o custom-columns=
"NAME:.metadata.name,UID:.metadata.uid,IP:.status.podIP,RESTARTS:.status.containerStatuses[0].restartCount"
# 2. Occasions on the pod
kubectl describe pod | grep -A 20 "Events:"
# 3. In-place resize standing
kubectl get pod -o jsonpath="{.status.resize}"
Conclusion
A container restart is disruptive however trustworthy — failure modes are speedy and visual. Sizzling-reload optimizes for availability however shifts failures to be delayed and refined. Each are legitimate methods. The selection must be acutely aware.
The aim is to not automate restarts sooner. It’s to grasp deeply sufficient that you simply set off a container restart solely when the method genuinely must die — and use each different mechanism when it doesn’t.
Companion repository: github.com/opscart/k8s-pod-restart-mechanics
Writer: Shamsher Khan — Senior DevOps Engineer, IEEE Senior Member.
This text is customized from an earlier model printed on OpsCart.com. Republished right here with permission.