



Picture by Writer
# Introduction
When designing an software, selecting the best SQL database engine can have a serious impression on efficiency.
Three widespread choices are PostgreSQL, MySQL, and SQLite. Every of those engines has distinctive strengths and optimization methods that make it appropriate for various eventualities.
PostgreSQL usually excels in coping with advanced analytical queries, and MySQL may ship strong general-purpose efficiency. Alternatively, SQLite provides a light-weight resolution for embedded purposes.
On this article, we’ll benchmark these three engines utilizing 4 analytical interview questions: two at medium issue and two at exhausting issue.
In every of them, the objective is to look at how every engine handles joins, window capabilities, date arithmetic, and complicated aggregations. This can spotlight platform-specific optimization methods and provide helpful insights into every engine’s efficiency and specs.
![]()
# Understanding The Three SQL Engines
Earlier than diving into the benchmarks, let’s attempt to perceive the variations between these three database programs.
PostgreSQL is a feature-rich, open-source relational database recognized for superior SQL compliance and complex question optimization. It may deal with advanced analytical queries successfully, has robust assist for window capabilities, CTEs, and a number of indexing methods.
MySQL is probably the most broadly used open-source database, favored for its pace and accuracy in internet purposes. Regardless of its historic emphasis on transactional workloads, fashionable variations of this engine embrace complete analytical capabilities with window capabilities and improved question optimization.
SQLite is a light-weight engine embedded immediately into purposes. Not like the 2 earlier engines, which run as separate server processes, SQLite runs as a library, making it excellent for cell purposes, desktop packages, and growth settings.
Nevertheless, as chances are you’ll anticipate, this simplicity comes with some limitations, for instance, in concurrent write operations and sure SQL options.
This text’s benchmark makes use of 4 interview questions that take a look at completely different SQL capabilities.
For every drawback, we’ll analyze the question options throughout all three engines, highlighting their syntax variations, efficiency concerns, and optimization alternatives.
We’ll take a look at their efficiency concerning execution time. Postgres and MySQL have been benchmarked on StrataScratch’s platform (server-based), whereas SQLite was benchmarked regionally in reminiscence.
# Fixing Medium-Stage Questions
// Answering Interview Query #1: Dangerous Tasks
This interview query asks you to determine initiatives that exceed their funds primarily based on prorated worker salaries.
Knowledge Tables: You are given three tables: linkedin_projects (with budgets and dates), linkedin_emp_projects, and linkedin_employees.
![]()
![]()
![]()
The objective is to compute the portion of every worker’s annual wage allotted to every mission and to find out which initiatives are over funds.
In PostgreSQL, the answer is as follows:
SELECT a.title,
a.funds,
CEILING((a.end_date - a.start_date) * SUM(c.wage) / 365) AS prorated_employee_expense
FROM linkedin_projects a
INNER JOIN linkedin_emp_projects b ON a.id = b.project_id
INNER JOIN linkedin_employees c ON b.emp_id = c.id
GROUP BY a.title,
a.funds,
a.end_date,
a.start_date
HAVING CEILING((a.end_date - a.start_date) * SUM(c.wage) / 365) > a.funds
ORDER BY a.title ASC;
PostgreSQL handles date arithmetic elegantly with direct subtraction (( textual content{end_date} – textual content{start_date} )), which returns the variety of days between dates.
The computation is easy and straightforward to learn due to the engine’s native date dealing with.
In MySQL, the answer is:
SELECT a.title,
a.funds,
CEILING(DATEDIFF(a.end_date, a.start_date) * SUM(c.wage) / 365) AS prorated_employee_expense
FROM linkedin_projects a
INNER JOIN linkedin_emp_projects b ON a.id = b.project_id
INNER JOIN linkedin_employees c ON b.emp_id = c.id
GROUP BY a.title,
a.funds,
a.end_date,
a.start_date
HAVING CEILING(DATEDIFF(a.end_date, a.start_date) * SUM(c.wage) / 365) > a.funds
ORDER BY a.title ASC;
In MySQL, the DATEDIFF() perform is required for date arithmetic, which explicitly computes what number of days are between two dates.
Whereas this provides a perform name, MySQL’s question optimizer handles this effectively.
Lastly, let’s check out the SQLite resolution:
SELECT a.title,
a.funds,
CAST(
(julianday(a.end_date) - julianday(a.start_date)) * (SUM(c.wage) / 365) + 0.99
AS INTEGER) AS prorated_employee_expense
FROM linkedin_projects a
INNER JOIN linkedin_emp_projects b ON a.id = b.project_id
INNER JOIN linkedin_employees c ON b.emp_id = c.id
GROUP BY a.title, a.funds, a.end_date, a.start_date
HAVING CAST(
(julianday(a.end_date) - julianday(a.start_date)) * (SUM(c.wage) / 365) + 0.99
AS INTEGER) > a.funds
ORDER BY a.title ASC;
SQLite makes use of the julianday() perform to transform dates to numeric values for arithmetic operations.
As a result of SQLite doesn’t have a CEILING() perform, we will mimic it by including 0.99 and changing to an integer, which rounds up precisely.
// Optimizing Queries
For every of the three engines, indexes could also be used on be a part of columns (project_id, emp_id, id) to enhance efficiency dramatically. PostgreSQL’s benefits come up from using composite indexes on (title, funds, end_date, start_date) for the GROUP BY clause.
Correct major key utilization is crucial, as MySQL’s InnoDB engine mechanically clusters information by the first key.
// Answering Interview Query #2: Discovering Consumer Purchases
The objective of this interview query is to output the IDs of repeat prospects who made a second buy inside 1 to 7 days after their first buy (excluding same-day repurchases).
Knowledge Tables: The one desk is amazon_transactions. It incorporates transaction information with id, user_id, merchandise, created_at, and income.
![]()
PostgreSQL Resolution:
WITH day by day AS (
SELECT DISTINCT user_id, created_at::date AS purchase_date
FROM amazon_transactions
),
ranked AS (
SELECT user_id, purchase_date,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY purchase_date) AS rn
FROM day by day
),
first_two AS (
SELECT user_id,
MAX(CASE WHEN rn = 1 THEN purchase_date END) AS first_date,
MAX(CASE WHEN rn = 2 THEN purchase_date END) AS second_date
FROM ranked
WHERE rn <= 2
GROUP BY user_id
)
SELECT user_id
FROM first_two
WHERE second_date IS NOT NULL
AND (second_date - first_date) BETWEEN 1 AND 7
ORDER BY user_id;
In PostgreSQL, the answer is to make use of CTEs (Widespread Desk Expressions) to interrupt the issue into logical and readable steps.
The date forged perform turns timestamps into dates, whereas the window capabilities with ROW_NUMBER() rank purchases chronologically. The inherent date subtraction function of PostgreSQL retains the ultimate filter tidy and efficient.
MySQL Resolution:
WITH day by day AS (
SELECT DISTINCT user_id, DATE(created_at) AS purchase_date
FROM amazon_transactions
),
ranked AS (
SELECT user_id, purchase_date,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY purchase_date) AS rn
FROM day by day
),
first_two AS (
SELECT user_id,
MAX(CASE WHEN rn = 1 THEN purchase_date END) AS first_date,
MAX(CASE WHEN rn = 2 THEN purchase_date END) AS second_date
FROM ranked
WHERE rn <= 2
GROUP BY user_id
)
SELECT user_id
FROM first_two
WHERE second_date IS NOT NULL
AND DATEDIFF(second_date, first_date) BETWEEN 1 AND 7
ORDER BY user_id;
MySQL’s resolution is much like the earlier PostgreSQL construction, utilizing CTEs and window capabilities.
The principle distinction right here is using the DATE() and DATEDIFF() capabilities for date extraction and comparability. MySQL 8.0+ helps CTEs effectively, whereas earlier variations require subqueries.
SQLite Resolution:
WITH day by day AS (
SELECT DISTINCT user_id, DATE(created_at) AS purchase_date
FROM amazon_transactions
),
ranked AS (
SELECT user_id, purchase_date,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY purchase_date) AS rn
FROM day by day
),
first_two AS (
SELECT user_id,
MAX(CASE WHEN rn = 1 THEN purchase_date END) AS first_date,
MAX(CASE WHEN rn = 2 THEN purchase_date END) AS second_date
FROM ranked
WHERE rn <= 2
GROUP BY user_id
)
SELECT user_id
FROM first_two
WHERE second_date IS NOT NULL
AND (julianday(second_date) - julianday(first_date)) BETWEEN 1 AND 7
ORDER BY user_id;
SQLite (model 3.25+) additionally helps CTEs and window capabilities, making the construction an identical to the 2 earlier ones. On this case, the one distinction is the date arithmetic, which makes use of julianday() as a substitute of native subtraction or DATEDIFF().
// Optimizing Queries
Indexes will also be used on this case for environment friendly partitioning in window capabilities, particularly for the user_id. PostgreSQL can profit from partial indexes on energetic customers.
If working with massive datasets, one may take into account materializing the day by day CTE in PostgreSQL. For optimum CTE efficiency in MySQL, make sure you’re utilizing model 8.0+.
# Fixing Arduous-Stage Questions
// Answering Interview Query #3: Income Over Time
This interview query asks you to compute a 3-month rolling common of complete income from purchases.
The objective is to output year-month values with their corresponding rolling averages, sorted chronologically. Returns (unfavorable buy quantities) must be excluded.
Knowledge Tables:
amazon_purchases: Incorporates buy information with user_id, created_at, and purchase_amt
![]()
First, let’s examine the PostgreSQL resolution:
SELECT t.month,
AVG(t.monthly_revenue) OVER(
ORDER BY t.month
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS avg_revenue
FROM (
SELECT to_char(created_at::date, 'YYYY-MM') AS month,
sum(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt > 0
GROUP BY to_char(created_at::date, 'YYYY-MM')
ORDER BY to_char(created_at::date, 'YYYY-MM')
) t
ORDER BY t.month ASC;
PostgreSQL outperforms with window capabilities, because the body specification ROWS BETWEEN 2 PRECEDING AND CURRENT ROW defines the rolling window exactly.
The to_char() perform codecs dates into year-month strings for grouping.
Subsequent, the MySQL Resolution:
SELECT t.`month`,
AVG(t.monthly_revenue) OVER(
ORDER BY t.`month`
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS avg_revenue
FROM (
SELECT DATE_FORMAT(created_at, '%Y-%m') AS month,
sum(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt > 0
GROUP BY DATE_FORMAT(created_at, '%Y-%m')
ORDER BY DATE_FORMAT(created_at, '%Y-%m')
) t
ORDER BY t.`month` ASC;
MySQL’s implementation handles the window perform identically, though it makes use of the DATE_FORMAT() perform as a substitute of to_char().
Notice this engine has a particular syntax requirement to keep away from key phrase conflicts, therefore the backticks round month.
Lastly, the SQLite resolution is:
SELECT t.month,
AVG(t.monthly_revenue) OVER(
ORDER BY t.month
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS avg_revenue
FROM (
SELECT strftime('%Y-%m', created_at) AS month,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt > 0
GROUP BY strftime('%Y-%m', created_at)
ORDER BY strftime('%Y-%m', created_at)
) t
ORDER BY t.month ASC;
Date formatting in SQLite requires the utilization of strftime(), and this engine helps the identical window perform syntax as PostgreSQL and MySQL (in model 3.25+). Efficiency is comparable for small to medium-sized datasets.
// Optimizing Queries
Window capabilities might be computationally costly to make use of.
For PostgreSQL, take into account creating an index on created_at and, if this question runs steadily, a materialized view for month-to-month aggregation.
MySQL advantages from overlaying indexes that embrace each created_at and purchase_amt.
For SQLite, you could be utilizing model 3.25 or later to have window perform assist.
// Answering Interview Query #4: Widespread Associates’ Good friend
Shifting on to the following interview query, this one asks you to search out the depend of every person’s mates who’re additionally mates with the person’s different mates (basically, mutual connections inside a community). The objective is to output person IDs with the depend of those widespread friend-of-friend relationships.
Knowledge Tables:
google_friends_network: Incorporates friendship relationships with user_id and friend_id.
![]()
The PostgreSQL resolution is:
WITH bidirectional_relationship AS (
SELECT user_id, friend_id
FROM google_friends_network
UNION
SELECT friend_id AS user_id, user_id AS friend_id
FROM google_friends_network
)
SELECT user_id, COUNT(DISTINCT friend_id) AS n_friends
FROM (
SELECT DISTINCT a.user_id, c.user_id AS friend_id
FROM bidirectional_relationship a
INNER JOIN bidirectional_relationship b ON a.friend_id = b.user_id
INNER JOIN bidirectional_relationship c ON b.friend_id = c.user_id
AND c.friend_id = a.user_id
) base
GROUP BY user_id;
In PostgreSQL, this advanced multi-join question is dealt with effectively by its refined question planner.
The preliminary CTE creates a two-way view of connections inside the community, adopted by three self-joins that determine triangular relationships through which ( A ) is mates with ( B ), ( B ) is mates with ( C ), and ( C ) can also be mates with ( A ).
MySQL Resolution:
SELECT user_id, COUNT(DISTINCT friend_id) AS n_friends
FROM (
SELECT DISTINCT a.user_id, c.user_id AS friend_id
FROM (
SELECT user_id, friend_id
FROM google_friends_network
UNION
SELECT friend_id AS user_id, user_id AS friend_id
FROM google_friends_network
) AS a
INNER JOIN (
SELECT user_id, friend_id
FROM google_friends_network
UNION
SELECT friend_id AS user_id, user_id AS friend_id
FROM google_friends_network
) AS b ON a.friend_id = b.user_id
INNER JOIN (
SELECT user_id, friend_id
FROM google_friends_network
UNION
SELECT friend_id AS user_id, user_id AS friend_id
FROM google_friends_network
) AS c ON b.friend_id = c.user_id
AND c.friend_id = a.user_id
) base
GROUP BY user_id;
MySQL’s resolution repeats the UNION subquery thrice as a substitute of utilizing a single CTE.
Though much less elegant, that is required for MySQL variations prior to eight.0. Trendy MySQL variations can use the PostgreSQL method with CTEs for higher readability and potential efficiency enhancements.
SQLite Resolution:
WITH bidirectional_relationship AS (
SELECT user_id, friend_id
FROM google_friends_network
UNION
SELECT friend_id AS user_id, user_id AS friend_id
FROM google_friends_network
)
SELECT user_id, COUNT(DISTINCT friend_id) AS n_friends
FROM (
SELECT DISTINCT a.user_id, c.user_id AS friend_id
FROM bidirectional_relationship a
INNER JOIN bidirectional_relationship b ON a.friend_id = b.user_id
INNER JOIN bidirectional_relationship c ON b.friend_id = c.user_id
AND c.friend_id = a.user_id
) base
GROUP BY user_id;
SQLite helps CTEs and handles this question identically to PostgreSQL.
Nevertheless, efficiency could degrade when dealing with massive networks attributable to SQLite’s less complicated question optimizer and the absence of superior indexing methods.
// Optimizing Queries
For all engines, composite indexes on (user_id, friend_id) might be created to enhance efficiency. In PostgreSQL, we will use hash joins for giant datasets when work_mem is configured appropriately.
For MySQL, be sure that the InnoDB buffer pool is sized adequately. SQLite could wrestle with very massive networks. For this, take into account denormalizing or pre-computing relationships for manufacturing use.
# Evaluating Efficiency
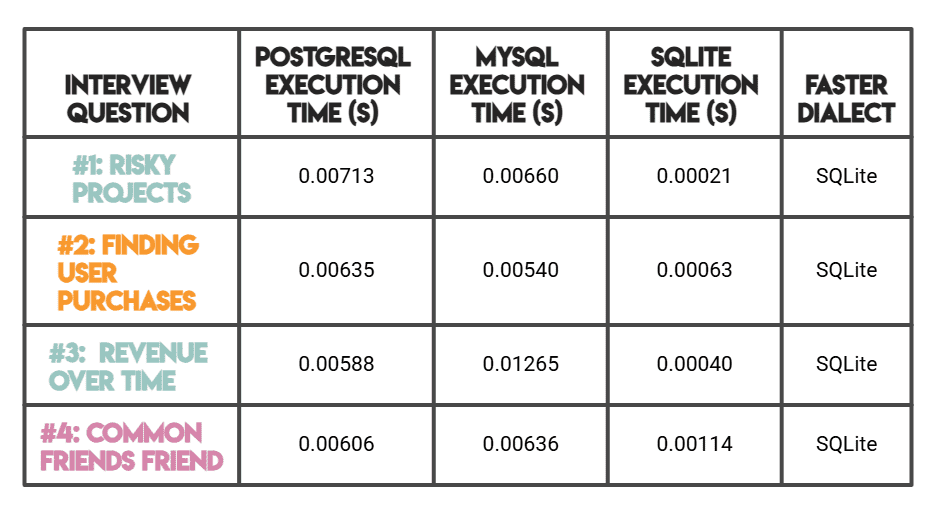
Notice: As talked about earlier than, PostgreSQL and MySQL have been benchmarked on StrataScratch’s platform (server-based), whereas SQLite was benchmarked regionally in reminiscence.
SQLite’s considerably sooner instances make sense attributable to its serverless, zero-overhead structure (fairly than superior question optimization).
For a server-to-server comparability, MySQL outperforms PostgreSQL on less complicated queries (#1, #2), whereas PostgreSQL is quicker on advanced analytical workloads (#3, #4).
# Analyzing Key Efficiency Variations
Throughout these benchmarks, a number of patterns emerged:
SQLite was the quickest engine throughout all 4 questions, usually by a major margin. That is largely attributable to its serverless, in-memory structure, with no community overhead or client-server communication; question execution is almost instantaneous for small datasets.
Nevertheless, this pace benefit is most pronounced with smaller information volumes.
PostgreSQL demonstrates superior efficiency in comparison with MySQL on advanced analytical queries, notably these involving window capabilities and a number of CTEs (Questions #3 and #4). Its refined question planner and in depth indexing choices make it the go-to alternative for information warehousing and analytics workloads the place question complexity issues greater than uncooked simplicity.
MySQL beats PostgreSQL on the less complicated, medium-difficulty queries (#1 and #2), providing aggressive efficiency with simple syntax necessities like DATEDIFF(). Its energy lies in high-concurrency transactional workloads, although fashionable variations additionally deal with analytical queries properly.
In brief, SQLite shines for light-weight, embedded use instances with small to medium datasets, PostgreSQL is your greatest wager for advanced analytics at scale, and MySQL strikes a stable steadiness between efficiency and general-purpose dependability.

# Concluding Remarks
From this text, you’ll perceive a number of the nuances between PostgreSQL, MySQL, and SQLite, which might allow you to decide on the appropriate software on your particular wants.

Once more, we noticed that MySQL delivers a steadiness between strong efficiency and general-purpose reliability, whereas PostgreSQL excels in analytical complexity with refined SQL options. On the similar time, SQLite provides light-weight simplicity for embedded settings.
By understanding how every engine performs specific SQL operations, you will get higher efficiency than you’ll by merely selecting the “best” one. Make the most of engine-specific options comparable to MySQL’s overlaying indexes or PostgreSQL’s partial indexes, index your be a part of and filter columns, and at all times use EXPLAIN or EXPLAIN ANALYZE clauses to grasp question execution plans.
With these benchmarks, now you can hopefully make knowledgeable choices about database choice and optimization methods that immediately impression your implementation’s efficiency.
Nate Rosidi is an information scientist and in product technique. He is additionally an adjunct professor educating analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from high corporations. Nate writes on the newest traits within the profession market, provides interview recommendation, shares information science initiatives, and covers all the things SQL.