



As cloud-native architectures proceed to mature, observability has develop into a foundational requirement slightly than an optionally available add-on. Based on the Cloud Native Computing Basis, OpenTelemetry continues to develop its contributor base and stays the second highest velocity mission in CNCF, changing into the “kubernetes” of the o11y world. Its fast progress and powerful group momentum mirror accelerating adoption amongst Kubernetes and cloud-native groups.
As organizations standardize on OpenTelemetry, one architectural query persistently arises: ought to telemetry be collected utilizing an OpenTelemetry Collector, an agent, or a mix of each? On this information, we demystify the OpenTelemetry Collector vs. agent debate, clarify how every suits into the OpenTelemetry structure, and allow you to select the fitting strategy for constructing environment friendly, scalable observability pipelines.
What are the principle elements of the OpenTelemetry structure?
Earlier than exploring the OpenTelemetry Collector vs agent variations, it’s important to know how each elements perform inside the OpenTelemetry structure.
What’s the OpenTelemetry Collector?
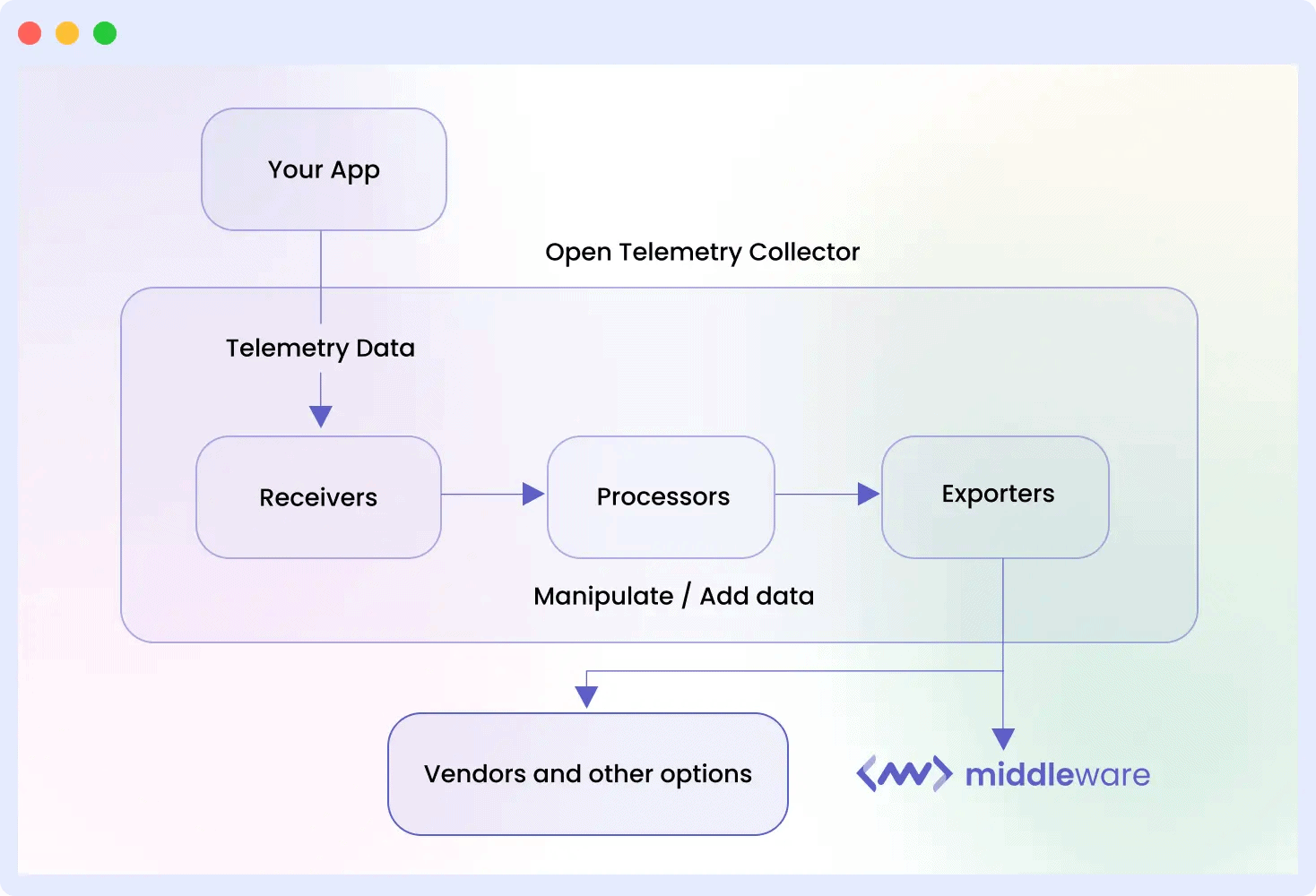
The OpenTelemetry Collector acts as a centralized service for managing telemetry knowledge. When evaluating the OpenTelemetry Collector vs agent, the Collector serves because the central processing hub for telemetry pipelines.
It’s one service that collects traces, metrics, and logs out of your functions, types them, after which sends them to the observability instruments or backends you utilize. In a way, it’s the heart of your monitoring setting.
As a substitute of your apps speaking on to monitoring backends, the Collector sits between them. It normalizes and prepares all knowledge earlier than forwarding it to the vacation spot.
Collector: Central hub for telemetry aggregation, transformation, and export.
What makes Collector so helpful?
- Information Assortment: The Collector can obtain telemetry from numerous sources by receivers, together with OpenTelemetry SDKs, brokers, and different observability instruments.
- Information Processing: This step lets you clear up the information earlier than it’s saved. You’ll be able to filter out the junk you don’t want, batch it up for higher effectivity, or tweak it in different methods. You too can add useful context (metadata) and cut back noise earlier than sending it off.
- Information Exporting: As soon as the information is processed, this function takes over. It makes use of exporters to ship the information to your storage and evaluation instruments (backends). The massive profit right here is that it doesn’t matter what observability instruments you’re utilizing this makes the information suitable together with your complete stack.
What’s the OpenTelemetry agent?
The OpenTelemetry agent is a light-weight course of that runs alongside your functions to gather telemetry knowledge regionally with minimal overhead earlier than forwarding it to a Collector or backend. You’ll be able to consider it as a light-weight sidecar or daemon that runs alongside together with your app and collects telemetry knowledge from it instantly.
Agent: Light-weight sidecar for knowledge seize on the software stage.
Its predominant job is simple: seize and ahead. The agent collects traces, metrics, and logs emitted by your app and sends them (usually to a Collector) with minimal processing.
The place does it differ from the Collector?
- The agent focuses on native knowledge assortment, which captures telemetry as near the supply as potential.
- It performs minimal knowledge processing, holding overhead low to attenuate influence on app efficiency.
- It’s preferrred for containerized or microservices environments, the place deploying an agent alongside every service ensures full visibility and management.
Inside the OpenTelemetry ecosystem, the agent, Collector, and SDKs combine with observability instruments similar to Prometheus, Jaeger, and Grafana. Collectively, they type a whole pipeline for metrics, logs, and traces throughout Kubernetes and hybrid cloud environments.
Collectively, the agent and Collector type the muse of an observability pipeline.
Function-by-feature comparability
The important thing distinction between the OpenTelemetry Collector and OpenTelemetry agent lies of their scope: the agent collects knowledge regionally, whereas the Collector aggregates and processes telemetry knowledge centrally earlier than exporting it to backends.
Right here’s a breakdown:
OpenTelemetry Collector vs. agent
| Function | OpenTelemetry Collector | OpenTelemetry agent |
| Deployment mannequin | Runs as a centralized service (standalone, gateway, or clustered) that gathers telemetry from a number of sources. | Deployed alongside functions (as a sidecar or daemonset) to gather telemetry knowledge regionally. |
| Major position | Acts as a knowledge pipeline receives, processes, and exports telemetry knowledge to varied observability platforms. | Features as a light-weight collector targeted on capturing and forwarding uncooked knowledge from software cases. |
| Information processing capabilities | Provides superior processing similar to batching, filtering, sampling, and transformation earlier than exporting. | Performs minimal processing, prioritizing velocity and low overhead. |
| Scalability | Extremely scalable, able to dealing with knowledge from tons of of providers or cases. | Scales naturally with the variety of software cases every handles its personal telemetry. |
| Efficiency influence | Offloads heavy processing away from apps, decreasing runtime load. | Very light-weight minimal influence on software efficiency. |
| Flexibility and customization | In depth customization by way of a number of receivers, processors, and exporters. Simply integrates with various observability instruments. | Less complicated configuration with restricted customization, preferrred for constant deployments. |
| Safety & Compliance | Requires correct entry management, TLS encryption, and authentication for centralized communication. | Operates inside the software’s trusted boundary, decreasing publicity however restricted to native scope. |
| Integration and compatibility | Appropriate with a number of backends (Prometheus, Jaeger, Elastic, and so on.) and helps hybrid or multi-cloud setups. | Tightly built-in with OpenTelemetry SDKs and helps main programming languages. |
| Finest match | Preferrred for centralized, large-scale environments that want knowledge aggregation and transformation. | Finest for application-level observability and containerized or distributed architectures. |
Key takeaway:
Use the Collector whenever you want centralized management and scalability; use the agent whenever you need localized, low-overhead telemetry seize close to the supply.
Ultimate suggestions
The proper selection between the OpenTelemetry Collector and agent relies on your system’s measurement and observability objectives.
- Use the Collector for centralized knowledge aggregation and transformation throughout a number of providers.
- Use the Agent for light-weight, native telemetry assortment close to your functions.
- For many setups, combining each delivers the very best efficiency and scalability.
This Member Weblog was initially printed on the Middleware weblog and is republished right here with permission.