



Anthropic has launched Claude Opus 4.6, its most succesful mannequin to this point, targeted on long-context reasoning, agentic coding, and high-value data work. The mannequin builds on Claude Opus 4.5 and is now out there on claude.ai, the Claude API, and main cloud suppliers beneath the ID claude-opus-4-6.
Mannequin focus: agentic work, not single solutions
Opus 4.6 is designed for multi-step duties the place the mannequin should plan, act, and revise over time. As per the Anthropic staff, they use it in Claude Code and report that it focuses extra on the toughest elements of a process, handles ambiguous issues with higher judgment, and stays productive over longer periods.
The mannequin tends to suppose extra deeply and revisit its reasoning earlier than answering. This improves efficiency on tough issues however can improve price and latency on easy ones. Anthropic exposes a /effort parameter with 4 ranges — low, medium, excessive (default), and max — so builders can explicitly commerce off reasoning depth in opposition to velocity and value per endpoint or use case.
Past coding, Opus 4.6 targets sensible knowledge-work duties:
- operating monetary analyses
- doing analysis with retrieval and looking
- utilizing and creating paperwork, spreadsheets, and displays
Inside Cowork, Anthropic’s autonomous work floor, the mannequin can run multi-step workflows that span these artifacts with out steady human prompting.
Lengthy-context capabilities and developer controls
Opus 4.6 is the primary Opus-class mannequin with a 1M token context window in beta. For prompts above 200k tokens on this 1M-context mode, pricing rises to $10 per 1M enter tokens and $37.50 per 1M output tokens. The mannequin helps as much as 128k output tokens, which is sufficient for very lengthy stories, code evaluations, or structured multi-file edits in a single response.
To make long-running brokers manageable, Anthropic ships a number of platform options round Opus 4.6:
- Adaptive considering: the mannequin can resolve when to make use of prolonged considering based mostly on process issue and context, as an alternative of all the time operating at most reasoning depth.
- Effort controls: 4 discrete effort ranges (low, medium, excessive, max) expose a clear management floor for latency vs reasoning high quality.
- Context compaction (beta): the platform robotically summarizes and replaces older elements of the dialog as a configurable context threshold is approached, lowering the necessity for customized truncation logic.
- US-only inference: workloads that should keep in US areas can run at 1.1× token pricing.
These controls goal a standard real-world sample: agentic workflows that accumulate a whole bunch of 1000’s of tokens whereas interacting with instruments, paperwork, and code over many steps.
Product integrations: Claude Code, Excel, and PowerPoint
Anthropic has upgraded its product stack in order that Opus 4.6 can drive extra lifelike workflows for engineers and analysts.
In Claude Code, a brand new ‘agent teams’ mode (analysis preview) lets customers create a number of brokers that work in parallel and coordinate autonomously. That is geared toward read-heavy duties equivalent to codebase evaluations. Every sub-agent may be taken over interactively, together with through tmux, which inserts terminal-centric engineering workflows.
Claude in Excel now plans earlier than performing, can ingest unstructured knowledge and infer construction, and may apply multi-step transformations in a single go. When paired with Claude in PowerPoint, customers can transfer from uncooked knowledge in Excel to structured, on-brand slide decks. The mannequin reads layouts, fonts, and slide masters so generated decks keep aligned with current templates. Claude in PowerPoint is presently in analysis preview for Max, Group, and Enterprise plans.
Benchmark profile: coding, search, long-context retrieval
Anthropic staff positions Opus 4.6 as cutting-edge on a number of exterior benchmarks that matter for coding brokers, search brokers, {and professional} choice help.
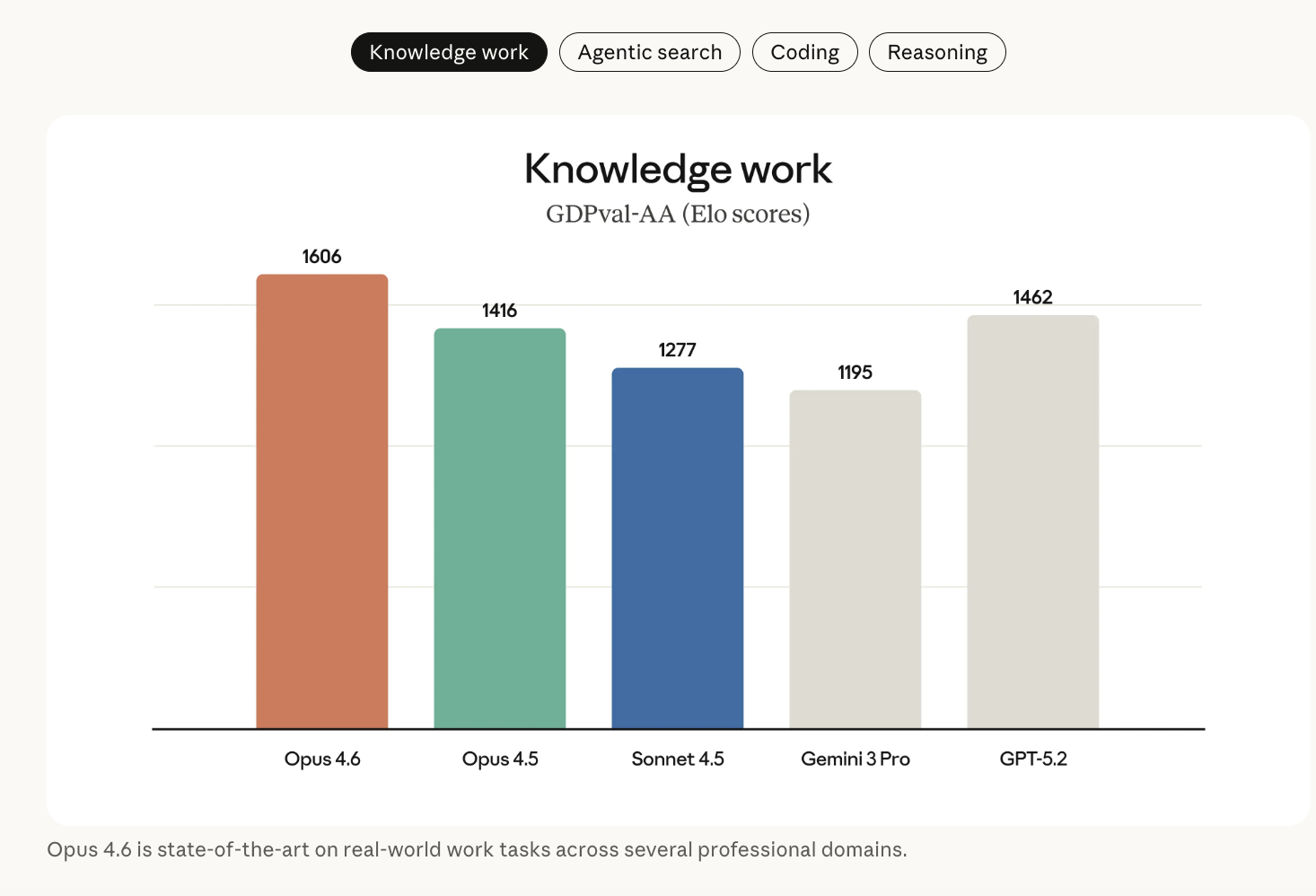
Key outcomes embody:
- GDPval-AA (economically priceless data work in finance, authorized, and associated domains): Opus 4.6 outperforms OpenAI’s GPT-5.2 by round 144 Elo factors and Claude Opus 4.5 by 190 factors. This suggests that, in head-to-head comparisons, Opus 4.6 beats GPT-5.2 on this analysis about 70% of the time.
- Terminal-Bench 2.0: Opus 4.6 achieves the very best reported rating on this agentic coding and system process benchmark.
- Humanity’s Final Examination: on this multidisciplinary reasoning take a look at with instruments (internet search, code execution, and others), Opus 4.6 leads different frontier fashions, together with GPT-5.2 and Gemini 3 Professional configurations, beneath the documented harness.
- BrowseComp: Opus 4.6 performs higher than another mannequin on this agentic search benchmark. When Claude fashions are mixed with a multi-agent harness, scores improve to 86.8%.
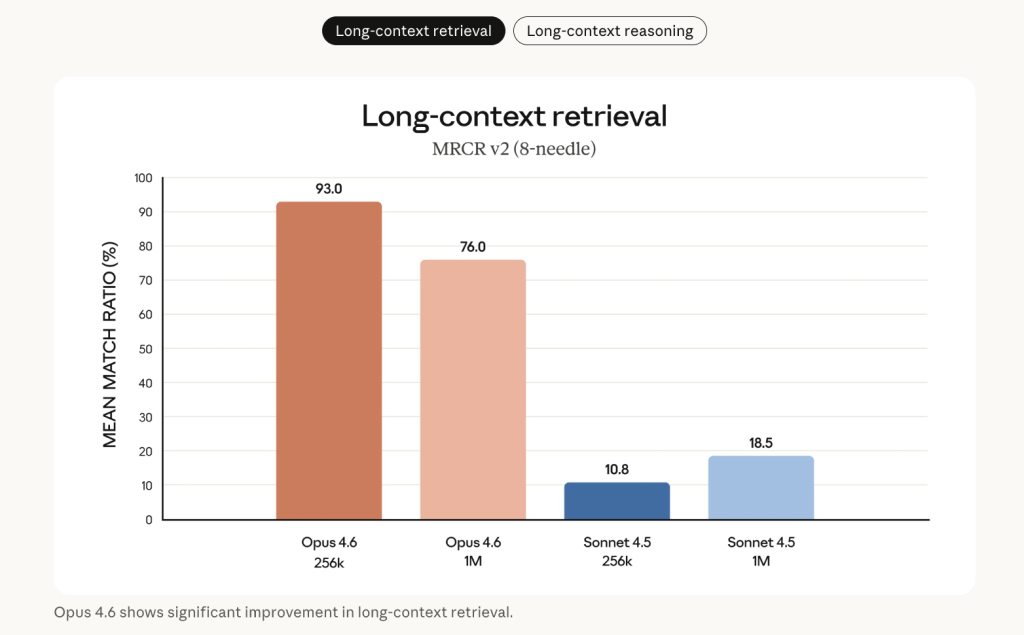
Lengthy-context retrieval is a central enchancment. On the 8-needle 1M variant of MRCR v2 — a ‘needle-in-a-haystack’ benchmark the place information are buried inside 1M tokens of textual content — Opus 4.6 scores 76%, in comparison with 18.5% for Claude Sonnet 4.5. Anthropic describes this as a qualitative shift in how a lot context a mannequin can truly use with out context rot.
Extra efficiency beneficial properties in:
- root trigger evaluation on complicated software program failures
- multilingual coding
- long-term coherence and planning
- cybersecurity duties
- life sciences, the place Opus 4.6 performs nearly 2× higher than Opus 4.5 on computational biology, structural biology, natural chemistry, and phylogenetics evaluations
On Merchandising-Bench 2, a long-horizon financial efficiency benchmark, Opus 4.6 earns $3,050.53 greater than Opus 4.5 beneath the reported setup.
Key Takeaways
- Opus 4.6 is Anthropic’s highest-end mannequin with 1M-token context (beta): Helps 1M enter tokens and as much as 128k output tokens, with premium pricing above 200k tokens, making it appropriate for very lengthy codebases, paperwork, and multi-step agentic workflows.
- Specific controls for reasoning depth and value through effort and adaptive considering: Builders can tune
/effort(low, medium, excessive, max) and let ‘adaptive thinking’ resolve when prolonged reasoning is required, exposing a transparent latency vs accuracy vs price trade-off for various routes and duties. - Sturdy benchmark efficiency on coding, search, and financial worth duties: Opus 4.6 leads on GDPval-AA, Terminal-Bench 2.0, Humanity’s Final Examination, BrowseComp, and MRCR v2 1M, with giant beneficial properties over Claude Opus 4.5 and GPT-class baselines in long-context retrieval and tool-augmented reasoning.
- Tight integration with Claude Code, Excel, and PowerPoint for actual workloads: Agent groups in Claude Code, structured Excel transformations, and template-aware PowerPoint technology place Opus 4.6 as a spine for sensible engineering and analyst workflows, not simply chat.
Take a look at the Technical particulars and Documentation. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be a part of us on telegram as nicely.
Max is an AI analyst at MarkTechPost, based mostly in Silicon Valley, who actively shapes the way forward for know-how. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI each day to translate complicated tech developments into clear, comprehensible insights
