



At this very moment, for $14,000, you can purchase a humanoid robot.
There’s no formally reviewed safety certification, no validated standard testing protocol in place. What you’re getting is a machine that can exert physical force and make autonomous decisions on the fly. And the systems designed to verify its behavior are still struggling to keep pace with what it’s actually capable of.
That’s not a knock on the engineers developing these systems. The intelligence side of robotics is progressing at a pace that truly warrants the enthusiasm it receives: sharper perception, more dependable locomotion, quicker inference, and tighter control loops.
But here’s the question that keeps nagging at me: As the control architecture of these systems advances from basic teleoperation all the way through to fully autonomous reinforcement learning, are our testing methods and safety validation processes keeping up?
I don’t believe they are. Not yet. And I believe that gap deserves attention — not to hold the industry back, but to help it grow responsibly.
Two recent research papers I’ve co-authored have significantly influenced how I think about this issue. The first introduces a framework for categorizing robot intelligence based on its underlying control architecture. The second explores how software safety risk analysis must adapt for AI-powered systems.
Collectively, they highlight something the industry increasingly requires: a testing philosophy that grows in step with autonomy. One where formal safety assurances take the place of test-case checklists at the highest levels, and where adversarial robustness testing becomes just as standard as functional testing.
First, a snapshot of where we stand
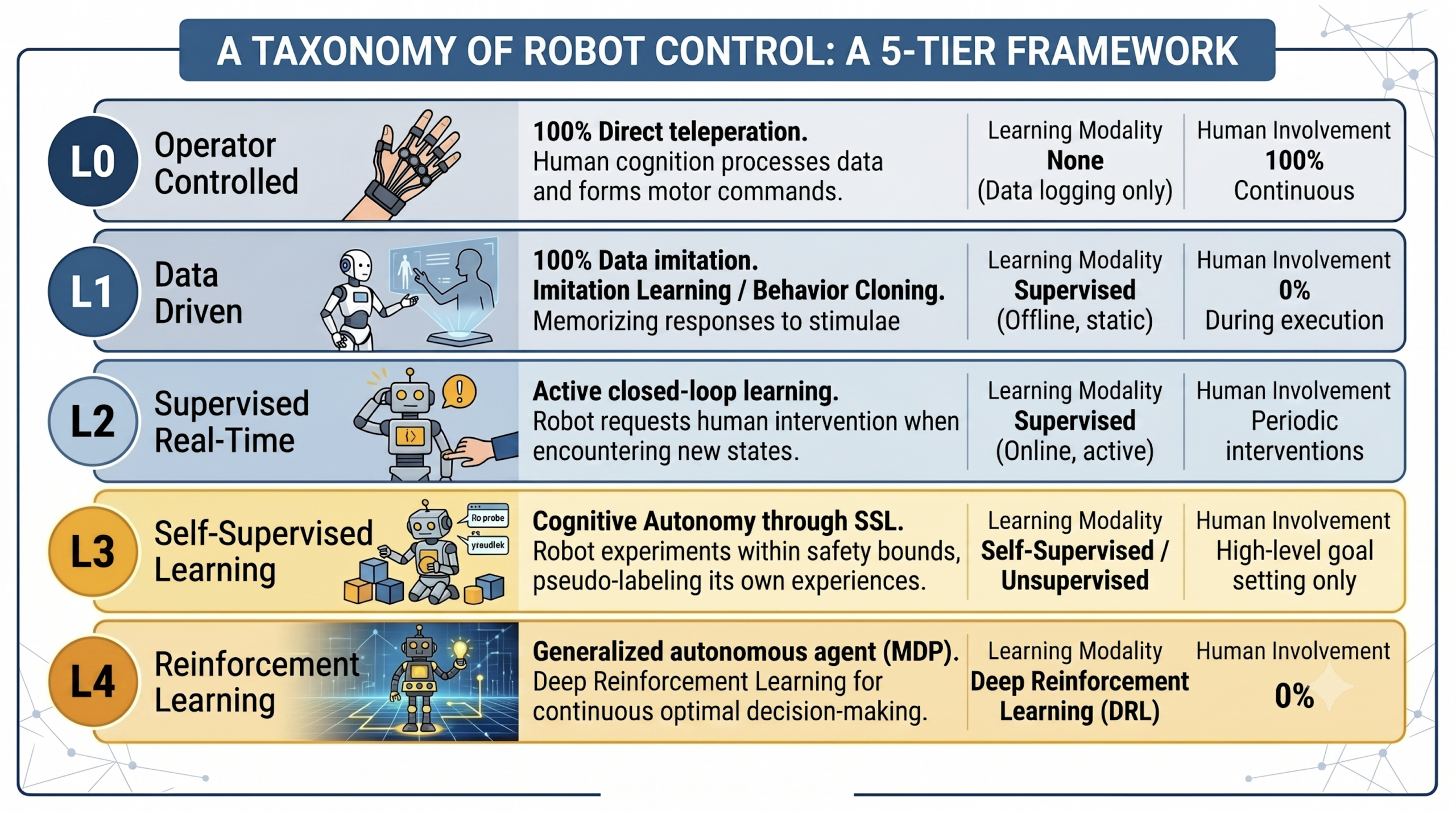
Before discussing how to test autonomous systems, it’s useful to be clear about exactly what kind of system we’re evaluating.
In a paper published in IJRCAR in March 2026, I introduced a five-level classification system that sorts robots by their cognitive and control architecture — not by how alert a human operator is, as the SAE driving levels do, but by how the machine itself processes information and produces behavior.
Levels 0 and 1: Teleoperation and imitation. At Level 0, a human does all the thinking. The robot carries out commands directly through teleoperation. At Level 1, it has learned to mimic actions from recorded demonstrations via behavior cloning and can function without a live operator, but only within the boundaries of what it has previously encountered. The fragility at this stage is well-established: Robots trained on polished, structured demonstrations falter when real-world conditions deviate even slightly from training data. A different floor surface, an object positioned at an unexpected angle. Testing at these levels is relatively manageable, and the available tools are well-developed.
Level 2: Supervised real-time learning. The robot can recognize its own uncertainty, halt safely, ask for guidance, and fold that guidance into its future behavior through inverse reinforcement learning. Testing becomes a dual challenge: confirming that the uncertainty detection mechanism itself works correctly, and verifying the soundness of the learning update triggered by each corrective input.
Level 3: Self-supervised learning. The robot creates its own training signals through experimentation, labeling its own successes and failures without human involvement. Here, the test engineer’s role fundamentally shifts. You’re no longer simply evaluating fixed behavior. You’re validating a system that is constantly revising its own policy. Testing must gauge not only present performance, but also the safety of the learning process itself.
Level 4: Reinforcement learning. Complete autonomy. The robot treats every task as an optimization problem and works it out through ongoing interaction with its environment, often arriving at solutions a human couldn’t have demonstrated. At this stage, traditional test-case enumeration falls apart. The behavior space is too vast, too fluid, and too emergent to catalog exhaustively.
Each step up this ladder doesn’t merely add capability. It also introduces an entirely new category of failure mode and calls for an entirely different validation strategy.
Where existing safety frameworks fall short
The default risk analysis tool in automotive and robotics software development is FMEA (failure mode and effects analysis). In a co-authored paper published in IRE Journals (2025), we investigated the specific shortcomings of software design FMEA when applied to AI-driven systems, and what a stronger approach would look like.
The central problem lies with the risk priority number, or RPN, which is FMEA’s standard scoring metric. It multiplies Severity, Occurrence, and Detection into a single value. The issue becomes apparent the moment you assign numbers: a catastrophic failure rated Severity 10, Occurrence 1, Detection 1 yields a score of 10. So does a moderate failure rated Severity 1, Occurrence 1, Detection 10. Identical number. Entirely different threat.
In a traditional deterministic software system, seasoned engineers compensate for this with professional judgment. In a neural network-driven system where failure modes are emergent and context-sensitive, that judgment is far harder to apply consistently.
The fallout from getting it wrong isn’t merely a failed test. It’s deployment delays, liability risk, and in the most serious cases, incidents that erode public confidence across an entire product category.
The paper recommends incorporating a risk priority matrix alongside HAZOP (hazard and operability study) analysis — methods that assess risk through richer contextual lenses rather than compressing everything into a single figure. Rooted in ISO 26262 for functional safety and ISO 21434 for automotive cybersecurity, this blended approach equips engineers with a more nuanced vocabulary for reasoning about AI-specific
ways things can go wrong.
The regulatory landscape highlights why this is so important. ISO 25785-1, the first global safety standard focused on bipedal robots, was released in May 2025 and applies specifically to industrial workplace settings. ISO 13482, which governs personal-care robots, also received an update in 2025 but was written before the rise of modern foundation models.
The 2025 update to ISO 10218-1 for industrial robotics represented a meaningful step forward, but safety researchers are already spotting shortcomings related to AI-powered humanoids and mobile manipulation that the revision doesn’t fully resolve. These standards serve as vital building blocks. They need hands-on input from practitioners to keep pace with the technology.
A testing mindset that grows alongside autonomy
So what should a more suitable testing strategy look like at each of these control levels? Here’s my perspective.
At Levels 0 and 1, traditional verification and validation techniques still work reasonably well. Hardware-in-the-loop (HiL) testing, structured test suites, and systematic boundary testing of the training data distribution are both practical and effective. The main addition needed for Level 1 is intentional out-of-distribution (OOD) testing — deliberately probing the boundaries of the training data rather than assuming full coverage.
At Level 2, the testing approach must broaden to encompass the learning loop itself. Two distinct aspects need separate validation:
- The uncertainty quantification mechanism — Can the robot accurately recognize when it’s uncertain or lacks knowledge?
- The policy update mechanism — Is the corrective feedback incorporated in a safe and precise manner?
Robust logging and replay capabilities become essential. Every instance of human intervention should be captured, labeled, and analyzed as a potential indicator of where the policy falls short.
At Level 3, formal methods transition from being optional to genuinely necessary. When a system is modifying its own policy through self-supervised learning, the safety constraints governing that learning process must be mathematically defined and verified — not merely tested through trial and error.
In real-world practice, the toughest challenge of Level 3 validation isn’t the tooling itself; it’s reaching consensus on what “safe exploration” actually means for your particular platform before testing even starts. Techniques like constrained reinforcement learning and safe exploration algorithms should be woven into the architecture from the outset, not bolted on afterward. Sim-to-real validation cycles need to rigorously stress-test self-supervised behaviors in edge-case scenarios before any real-world rollout takes place.
At Level 4, the testing philosophy must evolve away from listing individual test cases and toward statistical coverage and formal safety guarantees. Large-scale Monte Carlo simulations, adversarial environment generation, and domain randomization — the same methods used during training — should equally serve as core validation instruments. Behavioral specification frameworks that define what the policy must never do, irrespective of what it learns, carry the same weight as performance benchmarks.
The federated learning challenge
One area that warrants special attention as the industry moves toward Level 4 is federated reinforcement learning — the approach where entire robot fleets exchange policy updates across a network, distributing computational load and speeding up learning convergence.
The efficiency benefits are tangible and substantial. But the testing and validation demands are fundamentally different from those of single-robot setups.
When policy updates travel peer-to-peer across a fleet, the integrity of those updates must be confirmed at the point of aggregation. Research into federated learning security has cataloged specific ways things can go wrong: data poisoning, where a compromised node injects manipulated updates; backdoor attacks, where a trigger planted during training causes targeted misbehavior at inference time; and model inversion, where gradient sharing unintentionally exposes details about local training environments. These aren’t hypothetical — they’ve been demonstrated in practice.
Testing a federated system, then, must include adversarial robustness evaluation of the aggregation mechanism itself, not just the individual policy. Byzantine-fault-tolerant aggregation algorithms like Krum and FedProx, anomaly detection applied to incoming gradient updates, and cryptographic verification of update provenance are all engineering decisions that should be addressed during design and verifiable during validation. Differential privacy methods applied at the gradient-sharing stage provide an additional safeguard, limiting the damage any single compromised update can inflict. These aren’t niche research instruments. They’re accessible, well-documented, and increasingly essential to adopt as standard practice in any federated deployment.
Tying it all together
The journey from Level 0 to Level 4 is genuinely thrilling. The capabilities being showcased across autonomous vehicles, humanoid platforms, and industrial systems are real and significant. What the industry needs now is a testing philosophy that matures at the same rate.
That means treating safety validation as a core design requirement from the start, not a last-minute checkpoint. It means embedding HAZOP and Risk Priority Matrix analysis into the software development lifecycle from day one, not reaching for a FMEA spreadsheet right before launch. It means defining what counts as sufficient coverage for a self-supervised or RL-trained system before it’s deployed — not after the first failure occurs.
And it means giving standards bodies the real-world practitioner feedback they need to keep ISO 26262, ISO 21434, and the emerging bipedal robot standards evolving faster than the technology is leaving them behind.
The robots are outpacing the validation frameworks built to certify them. Bridging that divide isn’t purely a regulatory challenge or purely a research challenge. It’s a challenge rooted in engineering culture. It gets resolved when testing is regarded as a first-class design discipline from the very beginning, not a final hurdle before going live.
For those building autonomous systems at any of these levels: at what point does the system’s complexity make traditional test-case enumeration truly impractical, and what have you discovered actually takes its place? I’d especially value insights from anyone working through Level 3 or Level 4 validation in production environments.
 Submit your session idea for the 2026 RoboBusiness
Submit your session idea for the 2026 RoboBusinessAbout the author
 Atharv Kolhar serves as a staff test automation engineer at Figure AI. In this role, he focuses on hardware-in-the-loop test infrastructure for the Figure 03 humanoid robot and the testing of mission-critical robotic software. With experience spanning humanoid robotics, autonomous lidar sensing, and electric vehicles, he specializes in verification for safety-critical autonomous systems. He previously built the software test discipline that supported Aeva Technologies’ ASPICE Level 2 certification, and has held earlier positions at Lucid Motors and NIO.
Atharv Kolhar serves as a staff test automation engineer at Figure AI. In this role, he focuses on hardware-in-the-loop test infrastructure for the Figure 03 humanoid robot and the testing of mission-critical robotic software. With experience spanning humanoid robotics, autonomous lidar sensing, and electric vehicles, he specializes in verification for safety-critical autonomous systems. He previously built the software test discipline that supported Aeva Technologies’ ASPICE Level 2 certification, and has held earlier positions at Lucid Motors and NIO.
Kolhar is a voting member of IEEE P2817, the working group developing the international standard for autonomous systems verification. He also serves as a committee member of ASTM F45.06 on legged robot systems and acts as a peer reviewer for IEEE IROS and IEEE Transactions on Automation Science and Engineering.
The opinions expressed in this article are entirely his own and do not reflect the position, views, or stance of his employer or any affiliated organization.
Editor’s notes: This article is informed by two published papers: “Standardizing Robot Control Levels: A Framework for Autonomous Operation, Real-Time Navigation, and Federated Reinforcement Learning” (IJRCAR, Vol. 14, Issue 3, March 2026) and “Enhancing Software DFMEA Processes through ISO 26262 and ISO 21434: Addressing RPN Limitations with Risk Priority Matrix and HAZOP Integration” (IRE Journals, Vol. 8, Issue 7, 2025).