



# Introduction
When you first dive into machine learning, everything feels straightforward. You follow a guide that tells you to load some data, train a model, and suddenly you encounter lines like loss = "mse" or criterion = nn.CrossEntropyLoss().
Before you know it, the guide jumps into formulas, gradients, optimization techniques, and Greek symbols. If you have ever pretended to follow along without truly grasping what a loss function actually does, don’t worry — you are in good company. Loss functions tend to be taught in the wrong order. Most guides begin with the math when they should begin with the core concept. This article belongs to my noob series, where I break things down so they actually make sense. Let’s dive in.
# What Is a Loss Function?
A loss function is simply how a machine learning model figures out how far off it is. That is the entire idea in a nutshell. The model produces a prediction. The loss function checks that prediction against the true answer. Then it hands the model a score that says, “Here is how badly you messed up.”
A high loss means the model was way off.
A low loss means the model was pretty close.
Throughout training, the model continuously tweaks itself to push that loss lower.
That is the essence of how learning works. Think of it like playing darts. You toss the dart. To get better, you need feedback. You need to know whether your dart was a little off, way too far, too high, or too far to the left. Without that feedback, improvement is impossible. The bullseye represents the correct answer, and the dart is your prediction. You measure the gap between where the dart landed and the bullseye. The loss function does exactly that — it measures how far the dart ended up from the center. That gap becomes the model’s feedback signal. Here is a visual to help you picture it.
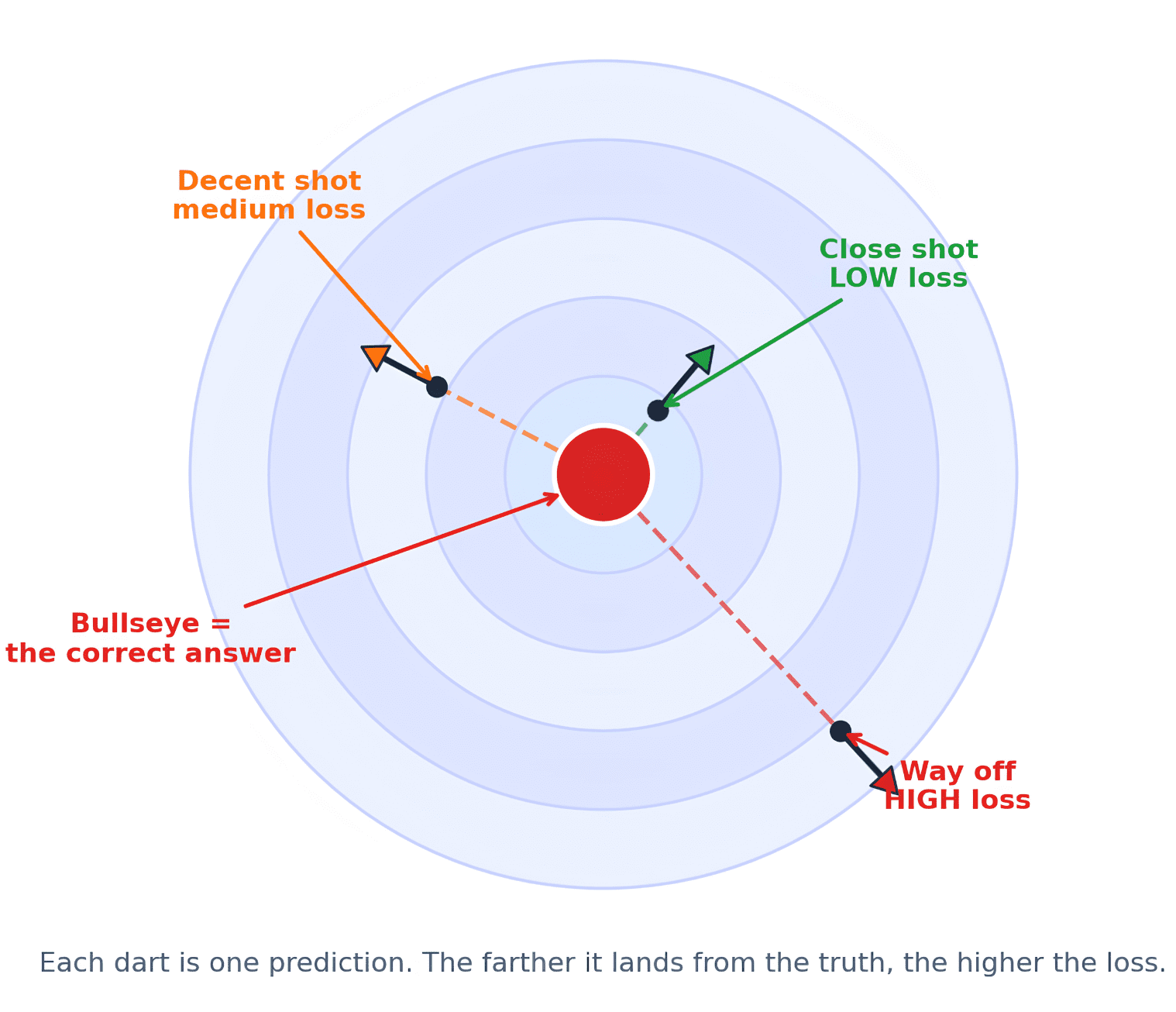
Just as the distance from the center counts, landing near the bullseye is very different from missing it entirely. In the same way, for models, simply knowing the answer is wrong is not sufficient. The model needs to understand the degree of its failure in order to get better.
Now that we understand what a loss function is and why it matters, let’s explore some of the most widely used loss functions in machine learning.
# Mean Squared Error
The go-to loss for predicting numerical values is mean squared error (MSE). It is commonly used when the model is forecasting things like house prices, temperatures, or delivery times. The concept is straightforward.
- Error: For each prediction, calculate the difference between the guess and the actual value.
- Squared: Multiply each difference by itself.
- Mean: Take the average of all those squared differences.
Here is how you could write it in Python:
def mean_squared_error(predictions, actuals):
squared_errors = [(p - a) ** 2 for p, a in zip(predictions, actuals)]
return sum(squared_errors) / len(squared_errors)I realize that computing errors and averaging them across predictions feels natural, but the reason we square them might not be obvious. There are two key reasons for this:
- Squaring ensures every error is positive. An error of +3 and an error of -3 are equally bad, and squaring converts both into 9, so they do not cancel each other out.
- Squaring penalizes large mistakes much more severely than small ones. This is desirable in many scenarios. For instance, if you are estimating house prices, being off by $1,000 versus $200,000 should carry very different penalties.
# Mean Absolute Error
Another frequently used loss function is mean absolute error (MAE). MAE also quantifies the gap between predictions and actual values, but it skips the squaring step. Instead, it simply takes the absolute value of each error.
Here is the Python implementation:
def mean_absolute_error(predictions, actuals):
absolute_errors = [abs(p - a) for p, a in zip(predictions, actuals)]
return sum(absolute_errors) / len(absolute_errors)So, it still penalizes larger errors, but not as aggressively as MSE does.
- An error of 10 costs 10, and an error of 20 costs 20.
- If your dataset contains outliers and you do not want your model to overreact to them, MAE is a solid choice.
Let me share a quick graph that contrasts the MSE and MAE curves.

# Cross-Entropy Loss
Up to now, we have focused on predicting numbers. But a huge number of machine learning problems involve predicting categories.
Is this email spam or not spam?
Is this image showing a cat, a dog, or a fish?
Is a particular transaction fraudulent or legitimate?
For classification tasks, models typically output probabilities such as:
Dog: 70%
Cat: 20%
Fish: 10%If the image truly is a dog, that is a strong prediction. But if it is actually a cat, then the model should be penalized for giving a low probability to the correct class.
The intuition breaks down like this:
- Correct and confident — low loss
- Correct but uncertain — medium loss
- Wrong and confident — high loss
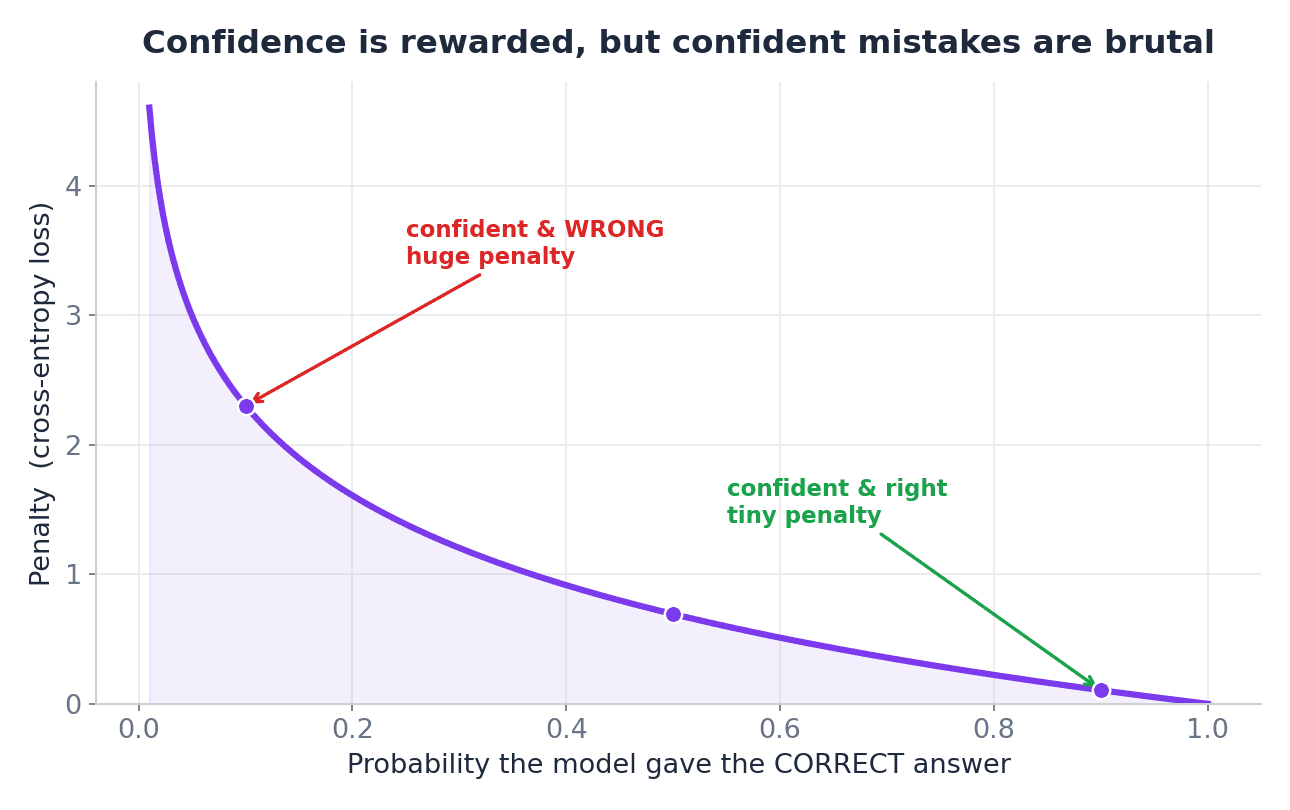
This is precisely why cross-entropy is so popular for classification. It does not only care about whether the model got the answer right. It also factors in how confident the model was in its prediction.
# Loss vs. Accuracy
Now that we have covered several loss functions, I also want to clear up the distinction between loss and accuracy. They are not interchangeable.
Accuracy tells you how many predictions were correct.
But loss tells you how severe the model’s mistakes were.
Imagine you have two models — Model A and Model B — and both correctly predict 90 out of 100 examples. They will have identical accuracy. However, one model might be highly confident on the correct answers and only slightly off on the wrong ones, while the other might be barely correct on many cases and extremely confident when it is wrong.
In that scenario, the accuracy would be identical, but the loss would differ significantly.
# The Training Loop
Once the model receives a loss value, it can start improving. The training loop works like this:
- The model makes predictions.
- The loss function measures
- The optimizer adjusts the model’s parameters.
- The model makes another attempt.
- The loss ideally decreases.
During training, we typically track the loss over time. Initially, the model makes frequent errors and performs poorly in its predictions, resulting in a high loss value. However, as training continues, the loss steadily declines and the model improves its predictive accuracy.
A typical healthy training curve follows this pattern:
High initial loss → rapid decline → slow leveling off
as illustrated in the following figure.

This leveling off is expected. It indicates the model has captured the simpler patterns and is now refining its understanding with smaller gains. However, if the training loss continues to decrease while the validation loss begins to rise, this may signal overfitting — meaning the model might be memorizing the training data rather than discovering patterns that apply more broadly.
# Final Thoughts
A loss function acts as the model’s error score.
It quantifies how far off the model’s predictions are, and it provides training with a clear objective: minimize that value.
Once you grasp loss functions, numerous other machine learning concepts become more intuitive — such as gradient descent, backpropagation, optimization, overfitting, and evaluation metrics.
You don’t need to begin with intimidating equations. Start with the core concept:
- The model makes a prediction.
- The loss function evaluates the prediction.
- The model adjusts itself to lower the score.
This is the essence of machine learning.
Loss is how a model recognizes its errors.
Training is how it learns to make fewer errors.
This concludes our article. We’ll keep exploring fascinating topics in our beginner-friendly series.
Kanwal Mehreen is a machine learning engineer and technical writer with a deep passion for data science and the intersection of AI and medicine. She co-authored the ebook “Maximizing Productivity with ChatGPT”. As a 2022 Google Generation Scholar for APAC, she advocates for diversity and academic excellence. She has also been recognized as a Teradata Diversity in Tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is a passionate advocate for change, having founded FEMCodes to support women in STEM.