



Most search agents grow step by step, with the model deciding how to search while also tracking what it found, which pieces of evidence are important, and which claims it already verified. Researchers from the University of Illinois Urbana-Champaign, UC Berkeley, and Chroma believe this places too much burden on a single system. In their view, reinforcement learning ends up trying to optimize both the search strategy and the routine record-keeping at the same time.
Their solution is Harness-1, a 20-billion-parameter retrieval subagent built on top of gpt-oss-20b. It was trained using reinforcement learning within a stateful search harness. The harness takes care of the record-keeping, while the policy focuses on semantic choices. Both the model weights and the harness code have been made publicly available.
What Is Harness-1, Exactly?
Harness-1 generates a ranked list of documents for a downstream model that handles the actual question answering. It does not answer questions on its own. Instead, it operates inside a state-machine framework built around a per-episode WORKINGMEMORY store.
Each step follows a cycle. The harness presents a compact summary of the current search state along with recent actions taken. The model then issues one structured action. The harness carries out that action, updates the internal state, and generates the next observation for the model to react to.
The Stateful Harness: What Gets Shifted Out of the Policy
The research team describes its core idea as stateful cognitive offloading. The policy handles the decisions — what to search for, what to curate, what to verify, and when to wrap up. The harness maintains the recoverable state surrounding those decisions.
That held state includes several components. A candidate pool collects compressed, deduplicated documents. A curated set — limited to 30 documents — holds the final output, each tagged with an importance level: very_high, high, fair, or low. A full-text repository stores every chunk retrieved outside of the prompt context.
An evidence graph adds further organization. A regex-based extractor scans each chunk for proper nouns, years, and dates. The harness then identifies frequently appearing entities, bridge documents, and singletons. Bridge documents mention two or more frequent entities, while singletons appear in just a single document and point toward promising follow-up directions.
The policy interacts with eight tools: fan_out_search, search_corpus, grep_corpus, read_document, review_docs, curate, verify, and end_search. Search results are compressed using sentence-BM25, which retains only the top four sentences. A two-level deduplication process removes duplicates by both chunk ID and content fingerprint.
One notable design choice solves the cold-start problem. The first successful search automatically populates the curated set with eight reranked results at fair importance. The policy then upgrades the strongest documents and removes the weakest ones. This reframes the task — rather than starting from nothing, the model is refining an initial pool.
The team outlines three requirements for a trainable harness: warm-started curation, compact rendering of derived state, and incentives that preserve diversity. Harness-1 incorporates all three.
How It Is Trained
Training mirrors the structure of the harness itself. Supervised fine-tuning first teaches the model how to use the interface. Reinforcement learning then sharpens the search decisions made over the maintained state.
A single teacher model — GPT-5.4 — operates live inside the full harness. After filtering, 899 trajectories remain for supervised fine-tuning. Training uses LoRA at rank 32 for three epochs. The checkpoint from step 550 serves as the starting point for reinforcement learning.
The RL phase uses on-policy CISPO with a 40-turn limit and reward only at the end of each episode. Training is restricted to SEC queries. Groups receiving identical rewards are excluded from gradient updates. All training was conducted on Tinker.
The reward function distinguishes between discovering relevant documents and selecting the best ones.
It also includes a bonus for using multiple different tools. In the absence of this incentive, the agent falls into the trap of performing the same search over and over again. Without the bonus, curated recall levels out close to 0.53. Once the bonus is applied, the variety of tools remains steady and recall climbs to roughly 0.60.
The Benchmark Results
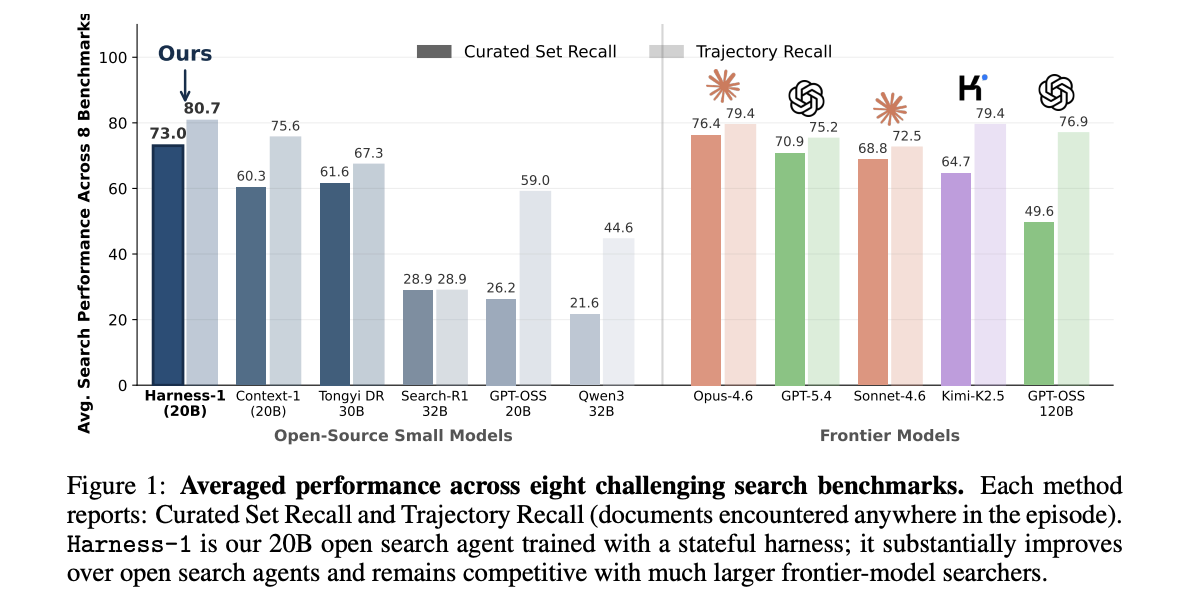
Harness-1 was put through its paces on eight separate benchmarks covering web queries, financial documents, patents, and multi-step question answering. The primary measure is curated recall, which tracks how well the final collection of documents covers what is relevant. Trajectory recall, on the other hand, counts any evidence the agent came across at any point during an episode, regardless of whether it made it into the final set.
| Model | Type | Avg Curated Recall | Avg Trajectory Recall |
|---|---|---|---|
| Harness-1 (20B) | Open small | 0.730 | 0.807 |
| Tongyi DeepResearch 30B | Open small | 0.616 | 0.673 |
| Context-1 (20B) | Open small | 0.603 | 0.756 |
| Search-R1 (32B) | Open small | 0.289 | 0.289 |
| GPT-OSS-20B | Open small | 0.262 | 0.590 |
| Qwen3 (32B) | Open small | 0.216 | 0.446 |
| Opus-4.6 | Frontier | 0.764 | 0.794 |
| GPT-5.4 | Frontier | 0.709 | 0.752 |
| Sonnet-4.6 | Frontier | 0.688 | 0.725 |
| Kimi-K2.5 | Frontier | 0.647 | 0.794 |
| GPT-OSS-120B | Frontier | 0.496 | 0.769 |
Harness-1 achieves an average curated recall of 0.730, which surpasses the strongest open subagent competitor, Tongyi DeepResearch 30B, by a margin of 11.4 percentage points. Among leading-edge search models, Opus-4.6 is the sole one that posts a higher average score.
The transfer results paint the clearest picture of what is going on under the hood. Supervised fine-tuning was carried out on four benchmark families, while reinforcement learning was restricted to SEC data. On tasks from those source families, Harness-1 improved by 7.9 points over the nearest open rival. On the four benchmarks that were held out entirely, the improvement jumped to 17.0 points, which is 2.2 times larger than the in-domain gain, indicating a much stronger effect on tasks furthest from what the model saw during training.
Component removal tests reinforce the value of the harness infrastructure. Stripping away all harness-level mechanisms causes a 12.2 percent relative drop in recall on BrowseComp+. The policy that was trained continues to search actively but lacks any way to properly prioritize what it finds.

Practical Applications
The approach is designed for evidence-driven retrieval, where collected documents serve as the foundation for an answer. The following are some scenarios that fit this mold:
One scenario is reviewing scientific literature or patents. The evidence graph and the curated document set are useful for organizing and making sense of a large number of sources. Another scenario is analyzing financial filings. The SEC demonstration case shows how the model can pinpoint an exact executive transition date by pulling from multiple 8-K filings.
A third scenario is multi-step fact verification. The fan_out_search and verify tools are used to disambiguate unclear entities before locking in a response. A fourth scenario is modular retrieval-augmented generation (RAG). The curated document set is passed into a fixed generator, and higher-quality sets directly translate to more accurate final answers.
Advantages and Limitations
Advantages
- Delivers the highest average curated recall among all open models evaluated, with only Opus-4.6 ranking above it overall.
- Performance gains persist on benchmarks the model never encountered during training, indicating search strategies that generalize across domains.
- Trained on just 4,352 unique items, a considerably smaller dataset than what many competing methods require.
- The model weights and harness code are both publicly available and can be deployed with standard inference runtimes.
Limitations
- The evidence graph
- It relies on regex-based extraction rather than complete entity linking.
- The verification tool acts as an LLM proxy and may produce errors on unclear claims.
- Sentence-BM25 compression can lose context connected to discourse structure.
- The research team provides point estimates but does not include full confidence intervals.
Key Takeaways
- Harness-1 is a 20B-parameter search agent that shifts search-related bookkeeping to the environment, allowing the policy to focus on semantic decisions.
- It achieves an average curated recall of 0.730 across eight benchmarks, outperforming the next best open subagent by 11.4 points.
- Among all tested search agents, only Opus-4.6 achieves a higher average curated recall.
- Performance gains are more pronounced on held-out benchmarks (+17.0 vs. +7.9 points), indicating that the learned search operations generalize well.
- Model weights and harness code are publicly available and can be served using vLLM, SGLang, or Transformers.
Marktechpost’s Visual Explainer
Stateful Search Agents
1 / 7Explore the Paper, Model weights, and GitHub Repo. Also, follow us on Twitter, join our 150k+ ML SubReddit, and subscribe to our Newsletter. Are you on Telegram? You can now join us there too!
Interested in partnering with us to promote your GitHub repo, Hugging Face page, product launch, or webinar? Get in touch with us

